






用于端到端噪声语音识别的鲁棒交互特征融合(2022)
摘要
语音增强(SE)旨在抑制噪声语音信号中的加性噪声,以提高语音的感知质量和可理解性。然而,由于缺少潜在信息,增强语音中的过抑制现象可能会降低下游自动语音识别(ASR)任务的性能。
为了缓解这一问题,我们提出了一种用于抗噪语音识别的交互式特征融合网络(IFF-Net),从增强特征和原始噪声特征中学习互补信息。
实验结果表明,该方法在 RATS Channel-A语料库上实现了比最佳基线减少4.1%的绝对词错误率。我们进一步的分析表明,所提出的IFF网络可以补充过度抑制增强特征中的一些缺失信息。
索引项:交互式特征融合、噪声鲁棒语音识别、语音增强、联合训练方法、过抑制现象
研究内容
然而,最近的工作[10、11、12]观察到,SE处理的增强语音可能并不总是能为下游ASR任务产生良好的识别精度。一个原因是SE处理和加性噪声一起减少了原始噪声语音中一些重要的潜在信息。这种过度抑制通常在增强阶段未被检测到,但可能对下游ASR任务有害。
之前的工作[13]提出了一个级联框架,仅使用ASR训练目标优化SE和ASR模块。之前提出了一种联合训练方法,通过多任务学习策略一起优化SE和ASR模块,如图1(a)所示。
然而,由于自动语音识别任务的输入信息仅来自增强语音,因此仍然存在过抑制现象。
工作[16]进一步提出了一种门递归融合(GRF)方法,将增强语音特征和噪声语音特征结合起来,用于ASR任务。前人的研究是本文的灵感来源。在本文中,我们提出了一种用于端到端ASR系统的交互式特征融合网络(IFF-Net),以提高其面对噪声数据的鲁棒性。我们从增强语音和噪声语音中学习融合表示,作为ASR任务的输入,以补充增强语音中缺失的信息。

Fig. 1. (a)联合训练法的方框图,(b)联合训练方法与我们提出的IFF-Net的方框图。
提出的方法&模型架构
整体架构 Overall Architecture
在这项工作中,我们构建了一个包含语音增强(SE)模块和自动语音识别(ASR)模块的联合系统。
具体来说,我们首先从基于双向长短时记忆(BLSTM)掩码的SE模块生成的增强波形中提取对数mel滤波器组(Fbank)特征。
然后,将增强的Fbank特征XE和带噪Fbank特征XN馈入所提出的IFF网络,以生成融合表示XF,作为后续ASR模块的输入。
训练阶段采用多任务学习策略。基于 BLSTM掩码SE模块和端到端ASR模块的结构分别与之前的工作[15]和[17]相同。
交互式特征融合网络(IFF-Net) Interactive Feature Fusion Network (IFF-Net)
IFF-Net由两个分支组成(即增强分支和噪声分支),用于在增强特征和噪声特征之间交换信息。
然后,提出了一个合并模块来生成权重掩码,指出增强特征和噪声特征的哪些部分可以保持。
然后使用掩码对这两个特征进行加权和,这样我们可以从增强特征中学习干净的语音信息,从噪声特征中学习互补信息。
由两个上采样卷积(Up-conv)块、几个残差注意力(RA)块、几个交互模块、两个下采样卷积(Dn-conv)块和一个合并模块组成,如图2所示。
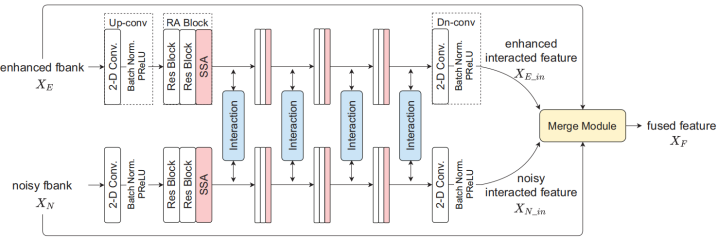
Fig. 2. 交互式特征融合网络(IFF网络)框图。“Up conv”是卷积层的上采样操作,“Dn conv”是卷积层的下采样操作。“RA”表示残差注意块,“SSA”表示可分离的自注意块,“Interaction”表示交互模块。
上样本卷积和下样本卷积 Upsample Convolution and Downsample Convolution
为了从输入中学习更丰富、更深入的信息,我们首先将增强的Fbank特征XE和带噪的Fbank特征XN输入到Up conv块,该块由二维卷积层组成,然后是批归一化(BN)层[18]和参数ReLU(PReLU)激活函数[19]。
二维卷积层的核大小为(1,1),步长为(1,1),滤波器数设置为64。同样,引入了一个与Up conv块结构相同的对应Dn conv块,以恢复交互特征XE-in和XN-in的通道维数,其与原始输入XE和XN保持相同。
Dn conv块与Up conv块共享相同的内核大小和步长,卷积层的滤波器数设置为1。
残差注意(RA)块 Residual Attention (RA) Block
为了捕捉表示中的局部和全局依赖关系,我们在Up conv块之后引入了残差注意力(RA)块[20],该块由两个残差块和一个可分离自注意力(SSA)模块组成,如图3所示。
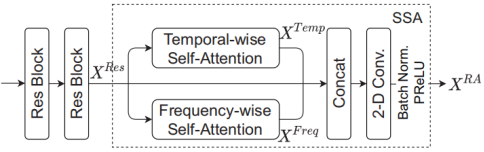
Fig. 3. 残差注意(RA)块的方框图。“Res块”是残差块的缩写。
每个残差块包括两个二维卷积层,核大小为(3,3),步长为(1,1),滤波器数为64,以从输入中提取深度局部特征。
然后,将两个残差块XRes的输出并行地馈送到时间和频率方向的自注意力块中,以捕获沿时间和频率维度的全局依赖性。在这里,我们以时间方向的自我注意为例来阐述时间和频率方向的自我注意机制:
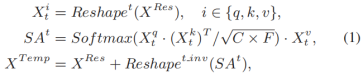
其中XRes∈ RC×T×F,Xit∈ RT×(C×F),SAt∈ RT×(C×F)和XTemp∈ RC×T×F。
C是滤波器编号,T是帧编号,F是频率编号。Reshapef是沿T维从RC×T×F到RT×(C×F)的张量整形, Reshapein_v是逆(inverse)运算。
同样,在频率方向的自注意力中,也存在类似的Reshapef重塑操作及沿F维进行的逆操作Reshapein_v。
最后,将生成的两个深度特征XTemp和XFreq以及XRes 联合(concatenated)并馈送到二维卷积层,以获得块输出XRA。
交互模块 Interaction Module
为了从增强分支和噪声分支的深度特征中学习互补信息,我们提出了一个交互模块,用于在它们之间交换信息,如图4所示。
该模块由两个交互方向组成,噪声到增强(n2e)和增强到噪声(e2n)。
以n2e方向为例,我们首先将输入增强和噪声特征XERA和XNRA连接起来,然后将其输入到二维卷积层。
然后是BN层和Sigmoid激活函数以生成乘法掩码MN,该MN掩码预测XNRA被抑制和保持信息。然后通过将MN和XNRA元素相乘来生成残差特征RN2E。
最后,该模块添加了XERA和RN2E,以获得增强特性的“过滤”版本XEIM。同样,我们对e2n交互方向执行相同的过程,其中仅交换输入“Feature-1”和“Feature-2”。
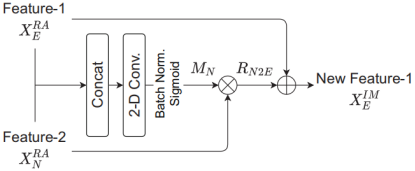
Fig. 4. 交互模块的方框图。这里我们 以n2e相互作用方向为例来说明。⊗表示元素级乘法,⊕表示残差连接。
合并模块 Merge Module
为了融合XE-in和XN -in这两个交互特性,我们提出了一个合并模块,如图5所示。此类交互特征XE-in和XN -in与输入Fbank特征XE和XN堆叠,并馈送到合并模块。合并模块由一个二维卷积层、一个来自SSA的时间自注意力块(用于捕获全局时间依赖性)和另一个卷积层(用于学习元素掩码M)组成。
合并模块充当一个门来控制交互特征的信息是保留还是丢弃。两个卷积层的核大小均为(3,3),滤波器数分别设置为4和1。最后,输出融合特征XF:![]()
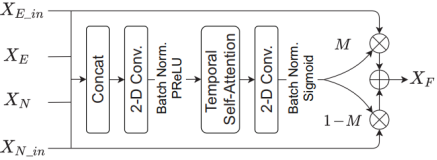
Fig. 5. 合并模块的方框图。⊗表示元素级乘法,⊕表示残差连接。
文章贡献
设计交互式特征融合网络(IFF-Net)。
基线
为了评估拟议系统的有效性,我们从之前的工作中建立了四个竞争基线进行比较。为了公平评估,我们分别对所有SE模块和ASR模块采用相同的架构。
1、E2E ASR系统[17-2020]:基于Conformer的端到端ASR系统。它在自动语音识别上取得了最先进的性能,但可能无法很好地用于抗噪语音识别任务。
2、级联SE和ASR系统[13-2019]:由前端基于BLSTM的SE模块和后端基于构象的ASR模块组成的级联系统。该系统仅使用ASR训练目标进行优化。
3、联合训练方法[15-2021]:与以前的级联系统结构相同,但采用多任务学习策略进行联合训练。它在SE和ASR之间建立了相关性,从而获得更好的识别结果。
4、GRF网络[16-2021]:一种结合增强语音和噪声语音的选通递归融合(GRF)方法,用于后续ASR训练。基于联合训练方法,进一步提高了抗噪声ASR的性能。
数据集
我们对鲁棒自动转录语音(RATS)数据集进行了实验。由于RATS语料库是LDC下的一个收费数据集,我们只在Github上发布其Fbank特性和几个监听样本以供参考。
RATS语料库由8个通道组成,在本工作中,我们只关注属于超高频(UHF)数据类别的 Channel-A数据。
RATS语料库中的Channel-A数据包括44.3小时训练数据、4.9小时有效数据和8.2小时测试数据
结果
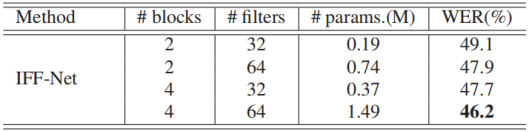
Table 1. WER%导致了对提议的IFF-Net的消融研究。“#blocks”表示IFF-Net每个分支中的RA块的数量,“#filters”表示RA块中卷积层的滤波器数量,以及“#params.”表示IFF-Net的参数量。不同的配置已经被探索,以最大化我们的GPU内存的使用。

Table 2.WER%的结果是对提出的IFF-Net的比较研究。“IFF-Net w/o noisy branch”是指无噪声分支、交互模块和合并模块。

Table 3. 提议的IFF-Net和竞争基线的WER%结果。
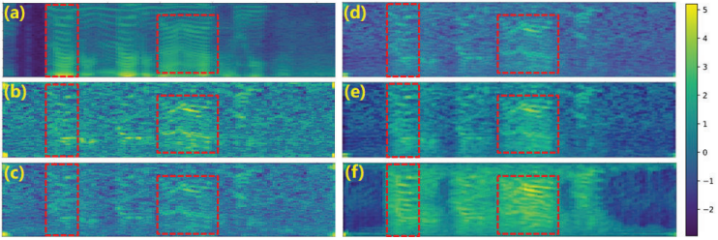
Fig. 6. (a)干净fbank频谱、(b)噪声fbank频谱;(c)级联SE和ASR系统的ASR输入,(d)联合训练方法的输入,(e)GRF网络的输入,(f)IFF-Net的输入。颜色条是为所有的光谱。
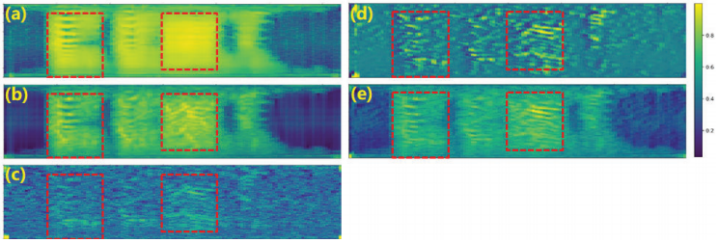
Fig. 7. IFF-Net中(a)增强fbank频谱、(b)增强交互特征、(c)噪声交互特征、(d)权重掩模、(e)融合特征。颜色条用于权重掩码。

















 2932
2932

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









