





DENOISING DIFFUSION IMPLICIT MODELS
去噪扩散隐式模型
摘要
去噪扩散概率模型(DDPMs)在没有对抗性训练的情况下实现了高质量的图像生成,但它们需要多次模拟马尔可夫链才能生成样本。为了加速采样,我们提出了去噪扩散隐式模型(DDIMs),这是一种更有效的迭代隐式概率模型,具有与DDPMs相同的训练过程。在ddpm中,生成过程被定义为一个特定的马尔可夫扩散过程的反向过程。我们通过一类非马尔可夫扩散过程来推广ddpm,从而得到相同的训练目标。这些非马尔可夫过程可以对应于确定性的生成过程,从而产生能够快速产生高质量样本的隐式模型。我们的经验证明,与DDPMs相比,DDIMs可以更快地产生10×到50×的高质量样本,使我们能够在样本质量上权衡计算,直接在潜在空间中执行有语义意义的图像插值,并以极低的误差重建观测结果。
介绍
深度生成模型已经证明了在许多领域产生高质量样本的能力(Karras等人,2020年;van den Oord等人,2016a)。在图像生成方面,生成对抗网络(GANs、古德费尔等人(2014))目前具有基于可能性的样本质量,如变分自编码器(金玛和韦林,2013)、自回归模型(范登德等人,2016b)和归一化流(雷曾德和穆罕默德,2015;Dinh等人,2016年)。然而,为了稳定训练,GANs在优化和架构方面需要非常具体的选择(Arjov斯基等人,2017;古拉贾尼等人,2017;卡拉斯等人,2018年;布洛克等人,2018年),而且可能无法涵盖数据分布模式(Zhao等人,2018年)。
最近在迭代生成模型(Bengio等人,2014),如去噪扩散概率模型(DDPM,Ho等人(2020))和噪声条件评分网络(NCSN,Song & Ermon(2019))已经证明能够在不进行对抗性训练的情况下产生与GANs相当的样本。为了实现这一点,许多去噪自编码模型被训练来去噪被不同水平的高斯噪声破坏的样本的去噪。然后由一个马尔可夫链产生样本,该链从白噪声开始,逐步将其去噪为一个图像。这种生成马尔可夫链过程要么基于朗之万动力学(Song & Ermon,2019),要么通过逐步将图像转化为噪声(Sohl-Dickstein等人,2015)。
这些模型的一个关键缺点是,它们需要多次迭代来产生高质量的样本。对于ddpm来说,这是因为生成过程(从噪声到数据)近似于正向扩散过程(从数据到噪声)的反向过程,这可能有数千个步骤;遍历所有步骤才能产生单个样本,这比GANs要慢得多,GANs只需要通过一个网络。例如,从DDPM上采样32×32大小的50k图像大约需要20个小时,但从Nvidia 2080 Ti GPU上的GAN上采样则不到一分钟。这对于较大的图像来说更成问题,因为在同一GPU上采样256×256大小的50k图像可能需要近1000个小时。
为了缩小ddpm和GANs之间的效率差距,我们提出了去噪扩散隐式模型(DDIMs)。DDIMs是隐式概率模型(穆罕默德和拉克什米纳拉亚南,2016),与DDPMs密切相关,其意义上是它们是用相同的目标函数训练的。
在第3节中,我们将DDPMs所使用的正向扩散过程,即马尔可夫扩散过程,推广到非马尔可夫扩散过程,为此我们仍然能够设计合适的逆生成马尔可夫链。我们证明了由此产生的变分训练目标有一个共享的替代目标,这正是用于训练DDPM的目标。因此,我们可以通过选择不同的非马尔可夫扩散过程(第4.1节)和相应的反向生成马尔可夫链,从使用相同神经网络的大量生成模型中自由选择。特别是,我们能够使用非马尔可夫扩散过程,从而导致“短的”生成马尔可夫链(第4.2节),这可以在少量的步骤中进行模拟。这只能以样品质量的微小成本大幅提高样品效率。
在第5节中,我们演示了DDIMs相对于DDPMs的几个经验好处。首先,当我们使用我们提出的方法将采样加速到10×到100×时,与DDPMs相比,DDIMs具有更好的样本生成质量。其次,DDIM样本具有以下“一致性”特性,这对于ddpm不成立:如果我们从相同的初始潜在变量开始,生成几个具有不同长度的马尔可夫链的样本,这些样本将具有相似的高级特征。第三,由于DDIMs中的“一致性”,我们可以通过操纵DDIMs中的初始潜在变量来执行具有语义意义的图像插值,而DDPMs由于随机生成过程在图像空间附近进行插值。
背景
给定来自数据分布q(x0)的样本,我们感兴趣的是学习一个近似于q(x0)的模型分布pθ(x0),并且很容易从中采样。去噪扩散概率模型是该形式的潜在变量模型:

其中,x1,……,xT是与x0(记为x)相同的样本空间中的潜在变量。通过最大化一个变分下界,学习了参数θ来拟合数据分布q(x0):
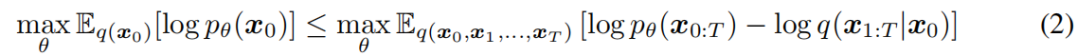
其中,q(x1:T |x0)是对潜在变量的一些推理分布。与典型的潜在变量模型(如变分自动编码器(Rezende et al.,2014))不同,ddpm是通过固定的(而不是可训练的)推理过程q(x1:T |x0)学习的,而潜在变量是相对高维的。例如,Ho等人(2020)考虑了以下马尔可夫链,其参数化由一个递减序列α1:T∈(0,1]T:
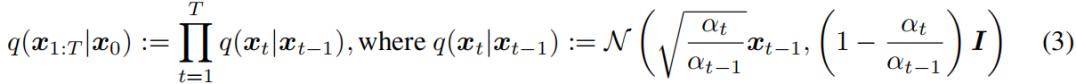
其中,保证协方差矩阵的对角线上有正的项。由于采样过程的自回归性质(从x0到xT),这被称为正向过程。我们称潜在变量模型为pθ(x0:T),它是一个从xT到x0的马尔可夫链,生成过程,因为它近似于难以处理的反向过程q(xt−1|xt)。直观地看,正向过程逐渐向观测x0增加噪声,而生成过程逐渐去噪有噪声的观测(图1,左)。
正向过程的一个特殊性质是
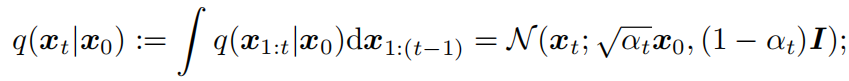
所以我们可以把xt表示为x0和噪声变量:
![]()
当我们将αT设置得足够接近0时,q(xT |x0)对所有x0收敛于标准高斯分布,所以很自然地设置pθ(xT):= N(0,I)。如果所有的条件都建模为具有可训练均值函数和固定方差的高斯,等式的目标(2)可简化为1:
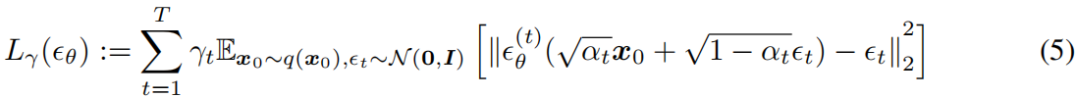
θ:={(θ t)} T t=1是一组T函数,每θ t): X→X(由t索引)是一个具有可训练参数θ (t)的函数,而γ := [γ1,…,γT ]是目标中的正系数向量,依赖于α1:T。在Ho等人(2020)中,γ = 1的目标被优化,以最大限度地提高训练模型的生成性能;这也是基于分数匹配的噪声条件分数网络(Song & Ermon,2019)中使用的相同目标(Hyv¨¨,2005;文森特,2011)。从一个训练好的模型中,首先从先验的pθ(xT)中采样xT,然后从生成过程中迭代采样xt−1。
正向过程的长度T是ddpm中一个重要的超参数。从变分的角度来看,一个大的T允许反向过程接近高斯分布(Sohl-迪克斯坦等人,2015),因此用高斯条件分布建模的生成过程成为一个很好的近似;这激发了对大T值的选择,如Ho等人(2020)中的T = 1000。然而,由于所有的T迭代都必须按顺序执行,而不是并行地获得样本x0,从ddpm采样比从其他深度生成模型采样要慢得多,这使得它们对于计算有限和延迟至关重要的任务不现实。
非马尔可夫正向过程的变分推理
由于生成模型近似于推理过程的相反,我们需要重新考虑推理过程,以减少生成模型所需的迭代次数。我们的关键观察结果是,以Lγ形式存在的DDPM目标仅依赖于边线2q(xt|x0),而不直接依赖于关节q(x1:T |x0)。由于有许多具有相同边缘的推理分布(关节),我们探索了非马尔可夫性的替代推理过程,这导致了新的生成过程(图1,右)。这些非马尔可夫推理过程导致了与DDPM相同的代理目标函数,我们将如下所示。在附录A中,我们证明了非马尔可夫视角也适用于高斯情况之外。
3.1非马尔可夫正向过程
让我们考虑一个推理分布的族Q,由一个真实的向量σ∈RT≥0索引:
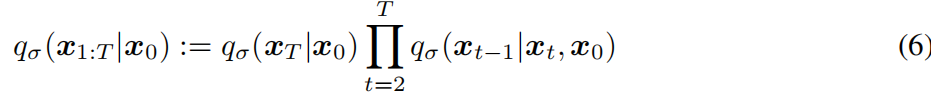
其中,qσ(xT|x0)=N(√αT x0,(1−αT)I)和对于所有的t > 1,
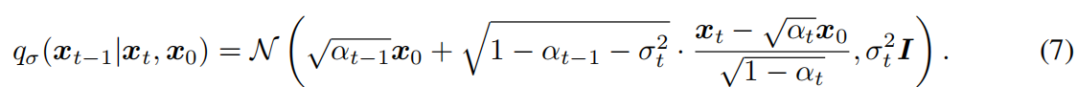
选择均值函数是为了确保qσ(xt|x0)=N(√αtx0,(1−αt)I)(见附录B的引理1),因此它定义了一个与“边线”匹配的联合推理分布。正向过程3可以由贝叶斯规则推导出:

这也是高斯分布的(虽然我们在本文的其余部分中没有使用这个事实)。不像在等式中的扩散过程(3),这里的正向过程不再是马尔可夫式的,因为每个xt都可以同时依赖于xt−1和x0。σ的大小控制了正向过程的随机性;当σ→0时,我们达到一个极端情况,只要我们观察某些t的x0和xt,xt−1就已知和固定。
生成过程和统一的变分推理目标
接下来,我们定义了一个可训练的生成过程pθ(x0:T),其中每个p(θt)(xt−1|xt)都利用了qσ的知识(xt−1|xt,x0)的知识。直观地说,给定一个噪声观测xt,我们首先对相应的x0进行预测4,然后使用它通过我们定义的反向条件分布qσ(xt−1|xt,x0)获得一个样本xt−1,我们已经定义。
对于一些x0∼q(x0)和t∼N(0,I),xt可以使用等式得到 (4).然后,模型(θ t)(xt)在不知道x0的情况下,尝试从xt预测t。通过重写等式(4),然后可以预测去噪观测,这是给定的x0的预测:
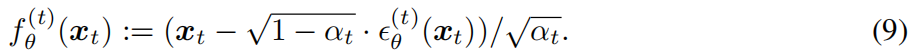
然后,我们可以用一个固定的先验pθ(xT)= N(0,I)和来定义生成过程

其中,qσ(xt−1|xt,fθ(t)(xt))被定义为在等式中(7)将x0替换为fθ (t)(xt)。对于t = 1的情况,我们添加了一些高斯噪声(协方差σ 2 1I),以确保生成过程得到任何支持。
我们通过以下变分推理目标(θ是θ上的一个函数)来优化θ:
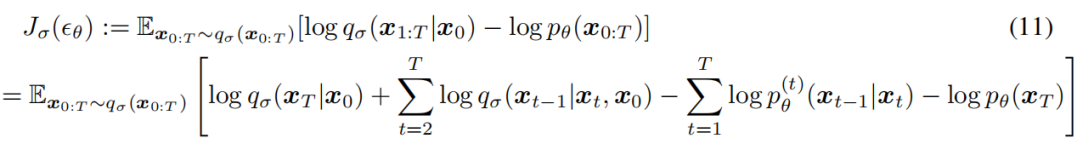
其中,我们根据等式进行分解qσ(x1:T |x0)(6)和pθ(x0:T)根据等式 (1).从Jσ的定义来看,似乎对于σ的每个选择都需要训练一个不同的模型,因为它对应于一个不同的变分目标(和一个不同的生成过程)。然而,对于某些权重的γ,Jσ等价于Lγ,如下图所示。
定理1。对于所有的σ > 0,都存在γ∈R T >0和C∈R,即Jσ = Lγ + C。
变分目标Lγ是特殊的意义,如果参数θ模型(θ)不共享不同的t,那么θ的最优解将不依赖于权重γ(全局最优是通过分别最大化每项的总和)。Lγ的这个特性有两个含义。一方面,这证明了使用L1作为DDPMs中变分下界的替代目标函数;另一方面,由于Jσ等同于定理1中的一些Lγ,Jσ的最优解也与L1的最优解相同。因此,如果模型θ中的t之间不共享参数,那么Ho等人(2020年)使用的L1目标也可以作为变分目标Jσ的替代目标。
从广义生成过程中进行抽样
以L1为目标,我们不仅学习了so尔-迪克斯坦等(2015)和Ho等(2020)考虑的马尔可夫推理过程的生成过程,还学习了我们描述的由σ参数化的许多非马尔可夫正向过程的生成过程。因此,我们基本上可以使用预先训练好的DDPM模型作为新目标的解决方案,并专注于寻找一个生成过程,通过改变σ来更好地根据我们的需求生成样本。

去噪扩散隐式模型
从等式中的pθ(x1:T)开始(10),我们可以通过以下方式从一个样本xt中生成一个样本xt−1:
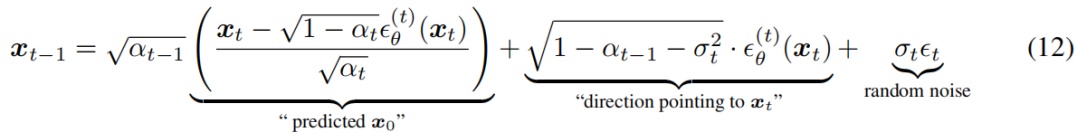
其中,t∼N(0,I)是独立于xt的标准高斯噪声,我们定义了α0 := 1。不同的σ值选择会导致不同的生成过程,而使用相同的模型θ,因此没有必要对模型进行重新训练。当σt = p(1−αt−1)/(1−αt)p 1−αt/αt−1时,正向过程为马尔可夫,生成过程为DDPM。
我们注意到另一个特殊情况,当所有t5的σt = 0;给定xt−1和x0,正向过程变得确定性,除了t = 1;在生成过程中,随机噪声t之前的系数为零。由此得到的模型成为一个隐式概率模型(穆罕默德和拉克什米纳拉亚南,2016),其中样本是通过一个固定的程序(从xT到x0)从潜在变量生成的。我们将其命名为去噪扩散隐式模型(DDIM,发音/d:Im/),因为它是一个用DDPM目标训练的隐式概率模型(尽管正向过程不再是一个扩散)。
加速生成过程
在前面几节中,生成过程被认为是反向过程的近似值;由于正向过程有T个步骤,生成过程也被迫对T个步骤进行采样。但是,由于只要qσ(xt|x0)是固定的,去噪目标L1就不依赖于特定的正向过程,因此我们也可以考虑长度小于T的正向过程,这样无需训练不同的模型,即可加速相应的生成过程。
让我们考虑正向过程不是定义在所有潜在变量x1:T上,而是在一个子集{xτ1,…,xτS },其中τ是长度为[1,…,T]的递增子序列。特别是,我们定义了xτ1上的顺序正向过程,…,xτS使q(xτi|x0)=N(√ατix0,(1−ατi)I)匹配“边线”(见图2)。生成过程现在根据反向(τ)对潜在变量进行采样,我们称之为(采样)轨迹。当采样轨迹的长度远小于T时,由于采样过程的迭代特性,我们可以显著提高计算效率。
使用类似于第3节中的论点,我们可以证明使用使用L1目标训练的模型,因此在训练中不需要改变。我们展示了对等式中的更新只有轻微的变化(12)需要获得新的、更快的生成过程,这适用于DDPM、DDIM,以及等式中考虑的所有生成过程 (10).我们在附录C.1中包含了这些细节。
原则上,这意味着我们可以用任意数量的前进步骤来训练一个模型,但在生成过程中只从其中一些步骤中采样。因此,训练后的模型可以考虑比(Ho et al.,2020)或甚至连续时间变量t(Chen et al.,2020)中考虑的更多的步骤。我们将这方面的实证调查留为未来的工作。

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









