







本文探讨扩散策略的范例-Aloha的环境配置
这里先简单介绍一下扩散策略的意义。传统机器人的算法,都是一些经典的传感器,视觉,力觉,触觉等等(由此产生的视觉引导,追踪,力位混合控制等等应用案例,已经很普及,在此不一一赘述,我在机器人学导论解读的专栏有详细解说)。而扩散策略探讨的,一般是经典算法搞不定的事情。例如UMI或者Aloha所演示的一个完整任务,任务可以是叠衣服,洗杯子,或者抓起来一个东西....(为什么抓起来一个东西这么简单,也要用新方法搞(工业不是很成熟么,视觉标定,计算,发给机器人执行),因为洗杯子,叠衣服的很复杂,初学者直接搞复杂任务搞不定。你可以先尝试新方法搞简单任务,如果简单任务流程走通了,再去搞复杂任务)。这里在额外讲一下,一般最后实战的任务,都是工业不太容易做的,跟工业有区别的。比如工业很成熟的码垛,打螺丝,根本没有用新的控制算法去测试的必要,已经做的很成熟,很便宜了。那么至少一些消费级的任务,比如做家务,就很难用工业的方法做(例如洗碗,洗衣服),这类任务一般都是不一样,但是又差不多。你家的碗筷和别人家的都差不多,衣服也是。更多是需要一些鲁棒性,兼容性(你教会了他A任务,他碰到跟A很接近的也能自适应)
这是机械臂打螺丝和做手术的典型场景举例。工业任务必须是确定的任务,一层不变的。而做手术每一个病人都不一样,就没法全自动,必须有人来操作。扩散策略就是想要拟人化的处理不太一样但是又都差不多的情况。

那么什么是扩散策略,扩散策略可以理解为一个拟合函数,拟合啥呢?我讲完流程就明白了,拟合的是一串机械臂轨迹+视频流。流程上,可以分为三个过程:1 数据采集 2 数据训练 3 数据部署(执行)
1 数据采集:此时要得到一个连续作业流程(连续作业流程是指完整执行一个事情,比如洗一个碗,放一个杯子)的机械臂轨迹(可以是关节轨迹,也可以是末端轨迹)和对应视频(可以是多角度的视频,比如机械臂末端放一个摄像头,整体顶部放一个摄像头。)读者可以观察一个典型的数据文件hdf5,包含了top顶部视觉的图片流(比如每隔0.1s的一个图像,以及action和qpos,qvel,action就是主手的动作关节位置,qpos就是从手的响应关节位置,qvel就是从手的速度数据,并不一定都被用到,理论上你输入信息越丰富,训练的智能体越聪明)。但是也会有多余,例如实际上一个完整作业流程,如果真的每个伺服周期都采集上来,那绝对不止几百条数据,4ms一个周期可能几万条数据都不止,但是可能数据量太密集也没用,浪费。你可以理解为人最多一秒钟看24幅图片,更高帧率人也处理不了,智能体也一样。
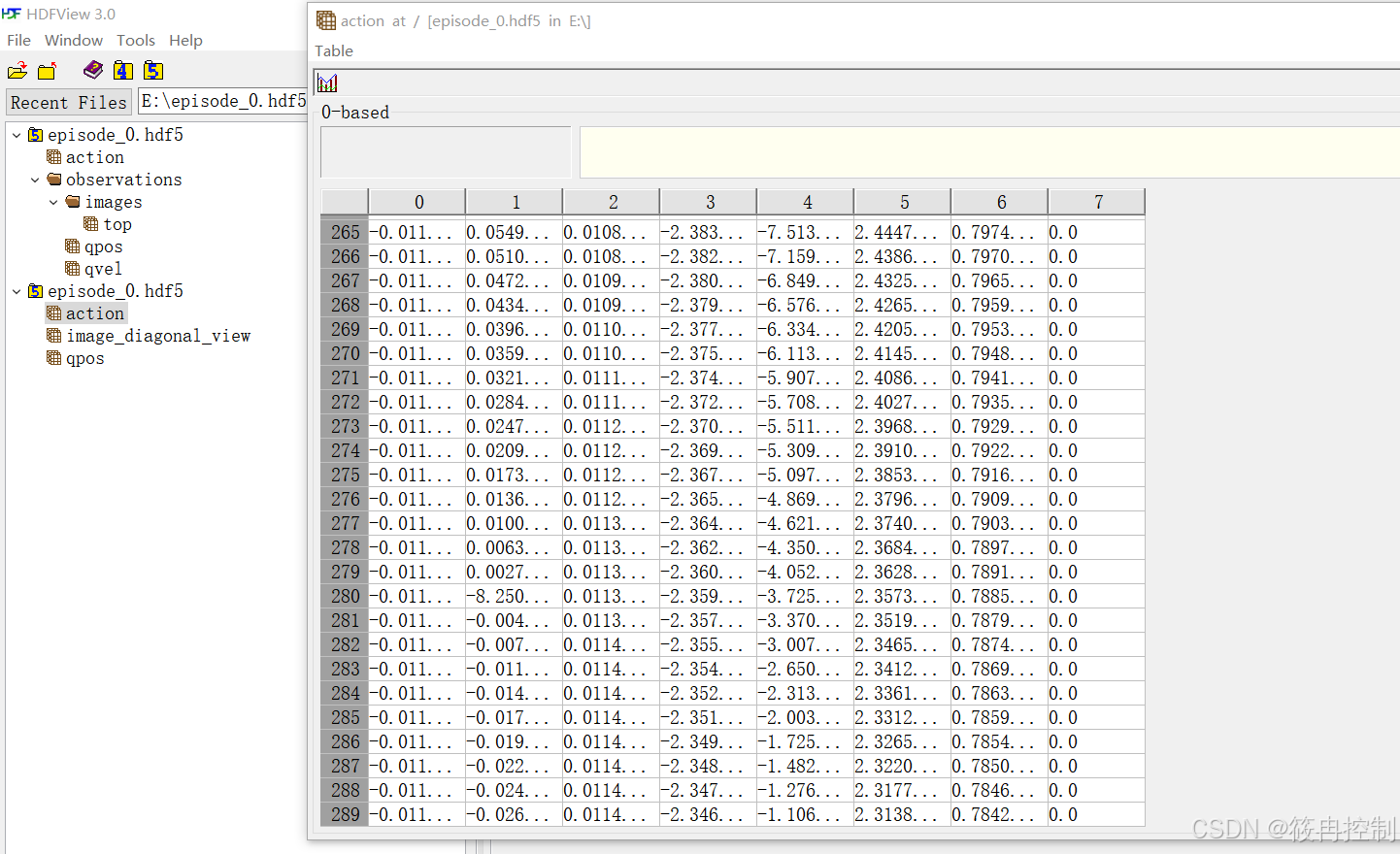
2 数据训练:以Aloha为例,执行训练之后,把前面输入的视频+机器人轨迹输出成一个“矩阵函数”吧,你可以这么理解,他就是一个函数
python3 imit
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











