






什么是 LangChain?
LangChain 是一个为各种大型语言模型应用提供通用接口的框架,旨在简化应用程序的开发流程。通过 LangChain,开发者可以轻松构建如图所示的 RAG(Retrieval-Augmented Generation)应用。
前排提示,文末有大模型AGI-优快云独家资料包哦!
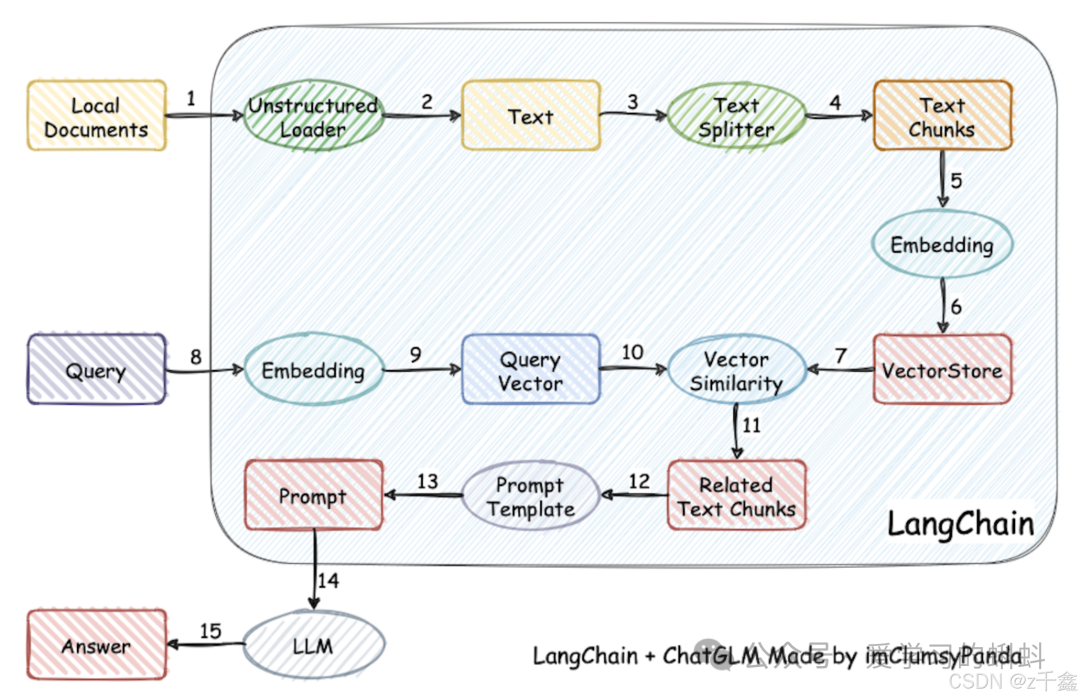
在这里插入图片描述
LangChain 概述
LangChain 是一个专为构建大型语言模型(LLMs)驱动的应用程序而设计的框架,其核心目标是简化从开发到生产的整个应用程序生命周期。
主要特点
-
模块化构建:提供一套模块化的构建块和组件,便于集成到第三方服务中,帮助开发者快速构建应用程序。
-
生命周期支持:涵盖应用程序的整个生命周期,从开发、生产化到部署,确保每个阶段的顺利进行。
-
开源与集成:提供开源库和工具,支持与多种第三方服务的集成。
-
生产化工具:LangSmith 是一个开发平台,用于调试、测试、评估和监控基于 LLM 的应用程序。
-
部署:LangServe 允许将 LangChain 链作为 REST API 部署,方便应用程序的访问和使用。
理解 Agent 和 Chain
Chain
在 LangChain 中,Chain 是指一系列按顺序执行的任务或操作,这些任务通常涉及与语言模型的交互。Chain 可以看作是处理输入、执行一系列决策和操作,最终产生输出的流程。Chain 的复杂性可以从简单的单一提示(prompt)和语言模型调用,扩展到涉及多个步骤和决策点的复杂流程。
Agent
Agent 是 LangChain 中更为高级和自主的实体,负责管理和执行 Chain。Agent 可以决定何时、如何以及以何种顺序执行 Chain 中的各个步骤。通常,Agent 基于一组规则或策略来模拟决策过程,能够观察执行结果并根据这些结果调整后续行动。Agent 的引入使得 LangChain 能够构建更为复杂和动态的应用程序,如自动化聊天机器人或个性化问答系统。
示例
-
Agent:基于某模型实现的问答系统可以视为一个 Agent。
-
Chain:问答系统根据一个 prompt 给出回答的过程可以看作是一个 Chain,实际回答过程通常涉及多个任务(Chain)依次执行。
简单顺序链示例
from langchain import Chain, Agent # 定义一个简单的 Chain simple_chain = Chain([ {"task": "获取用户输入"}, {"task": "处理输入"}, {"task": "生成回答"} ]) # 定义一个 Agent simple_agent = Agent(chain=simple_chain) # 执行 Agent response = simple_agent.execute() print(response)
检索增强生成(RAG)
检索增强生成(RAG, Retrieval-Augmented Generation)是一种创新架构,巧妙地整合了从庞大知识库中检索到的相关信息,以指导大型语言模型生成更为精准的答案。这一方法显著提升了回答的准确性与深度。
LLM 面临的主要问题
- 信息偏差/幻觉:
-
LLM 有时会生成与客观事实不符的信息,导致用户接收到不准确的信息。
-
解决方案:RAG 通过检索数据源辅助模型生成过程,确保输出内容的精确性和可信度,减少信息偏差。
- 知识更新滞后性:
-
LLM 基于静态数据集训练,可能导致知识更新滞后,无法及时反映最新信息动态。
-
解决方案:RAG 通过实时检索最新数据,保持内容的时效性,确保信息的持续更新和准确性。
- 内容不可追溯:
-
LLM 生成的内容往往缺乏明确的信息来源,影响内容的可信度。
-
解决方案:RAG 将生成内容与检索到的原始资料建立链接,增强内容的可追溯性,提升用户对生成内容的信任度。
- 领域专业知识能力欠缺:
-
LLM 在处理特定领域的专业知识时,效果可能不理想,影响回答质量。
-
解决方案:RAG 通过检索特定领域的相关文档,为模型提供丰富的上下文信息,提升专业领域内的问题回答质量和深度。
- 推理能力限制:
-
面对复杂问题时,LLM 可能缺乏必要的推理能力,影响问题理解和回答。
-
解决方案:RAG 结合检索到的信息和模型的生成能力,通过提供额外的背景知识和数据支持,增强模型的推理和理解能力。
- 应用场景适应性受限:
-
LLM 需在多样化应用场景中保持高效和准确,但单一模型可能难以全面适应所有场景。
-
解决方案:RAG 使得 LLM 能够通过检索对应应用场景数据,灵活适应问答系统、推荐系统等多种应用场景。
- 长文本处理能力较弱:
-
LLM 在理解和生成长篇内容时受限于有限的上下文窗口,处理速度随着输入长度增加而减慢。
-
解决方案:RAG 通过检索和整合长文本信息,强化模型对长上下文的理解和生成,有效突破输入长度限制,降低调用成本,提升整体处理效率。
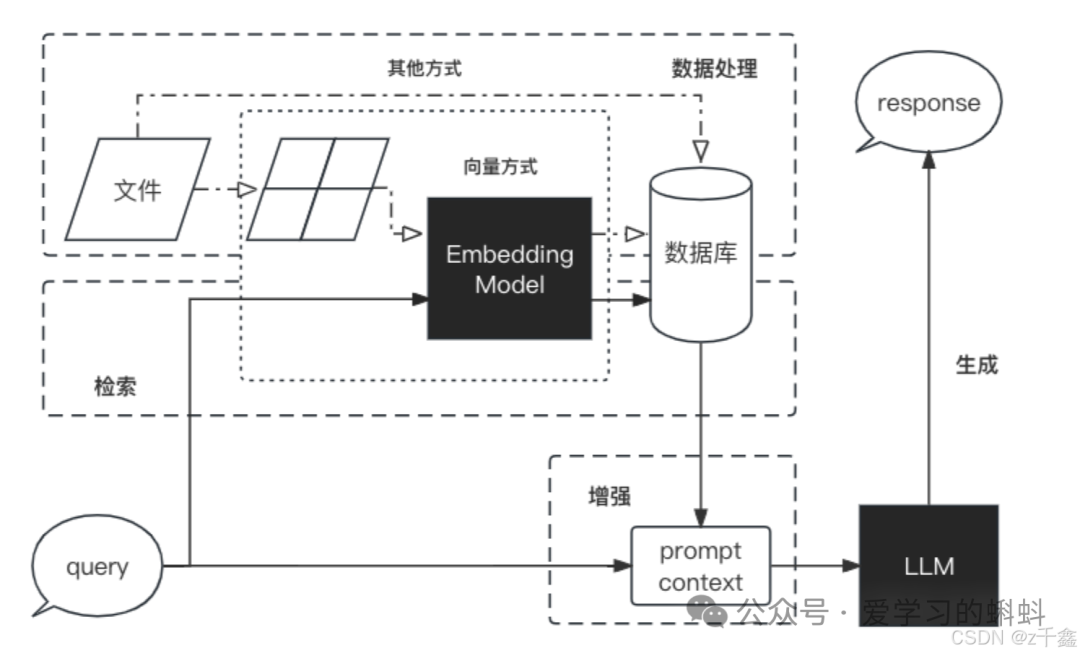
RAG 的工作流程
RAG 是一个完整的系统,其工作流程可以简单地分为以下四个阶段:
- 数据处理:
- 收集和预处理相关数据,以确保信息的质量和可用性。
- 检索阶段:
- 从知识库中检索与用户查询相关的信息,确保获取最新和最相关的数据。
- 增强阶段:
- 将检索到的信息与用户输入结合,为模型提供丰富的上下文。
- 生成阶段:
- 基于增强的信息,使用大型语言模型生成最终的回答或内容。
在这里插入图片描述
LangChain 核心组件
LangChain 是一个强大的大语言模型开发框架,能够将 LLM 模型(如对话模型、嵌入模型等)、向量数据库、交互层 Prompt、外部知识和代理工具整合在一起,从而自由构建 LLM 应用。LangChain 主要由以下六个核心组件组成:
1. 模型输入/输出(Model I/O)
与语言模型交互的接口,负责处理输入和输出数据。
2. 数据连接(Data Connection)
与特定应用程序的数据进行交互的接口,确保数据流的顺畅。
3. 链(Chains)
将各个组件组合实现端到端应用。例如,检索问答链可以完成检索和回答的任务。
4. 记忆(Memory)
用于链的多次运行之间持久化应用程序状态,确保上下文的连贯性。
5. 代理(Agents)
扩展模型的推理能力,执行复杂任务和流程的关键组件。代理可以集成外部信息源或 API,增强功能。
6. 回调(Callbacks)
用于扩展模型的推理能力,支持复杂应用的调用序列。
在开发过程中,开发者可以根据自身需求灵活组合这些组件,以实现特定功能。
获取OpenAI API KEY的两种方式,开发者必看全方面教程,点击就在这里!
LangChain-CLI
LangChain 提供了一个命令行工具 langchain-cli,通过该工具可以快速创建基于 LangChain 的应用,访问方式为 REST API。
-
项目地址:LangChain CLI GitHub
-
使用视频:YouTube 教程
-
对应项目地址:CSV Agent 示例
配置步骤(Pirate-Speak 模板案例)
- Git 配置:
- 确保 Git 已安装并配置。
- 环境变量配置:
- 设置
OPENAI_API_KEY和OPENAI_BASE_URL(如果转发 API 不是直接向api.openai.com发起请求,则需要配置后者)。
-
创建新环境:
conda create -n my-env python=3.11 conda activate my-env -
更换 pip 源:
python -m pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/ -
安装 Poetry:
pip install poetry -
安装 LangChain:
pip install langchain -
创建 LangChain 应用:
langchain app new my-app -
进入 Poetry 环境:
cd my-app poetry shell
- 安装依赖:
poetry install
- 运行模板:
poetry run langchain app add pirate-speak
- 注意:如果出现错误,可能是网络问题,请尝试更换网络。
- **修改
server.py**:在./app/server.py中去掉注释内容及if语句上一行的add_routes语句,加入以下内容:
from pirate_speak.chain import chain as pirate_speak_chain add_routes(app, pirate_speak_chain, path=“/pirate-speak”)
- 注意:在 Windows 系统中,
path="/pirate-speak"中的斜杠需要改为path="\pirate-speak"。
- 启动应用:
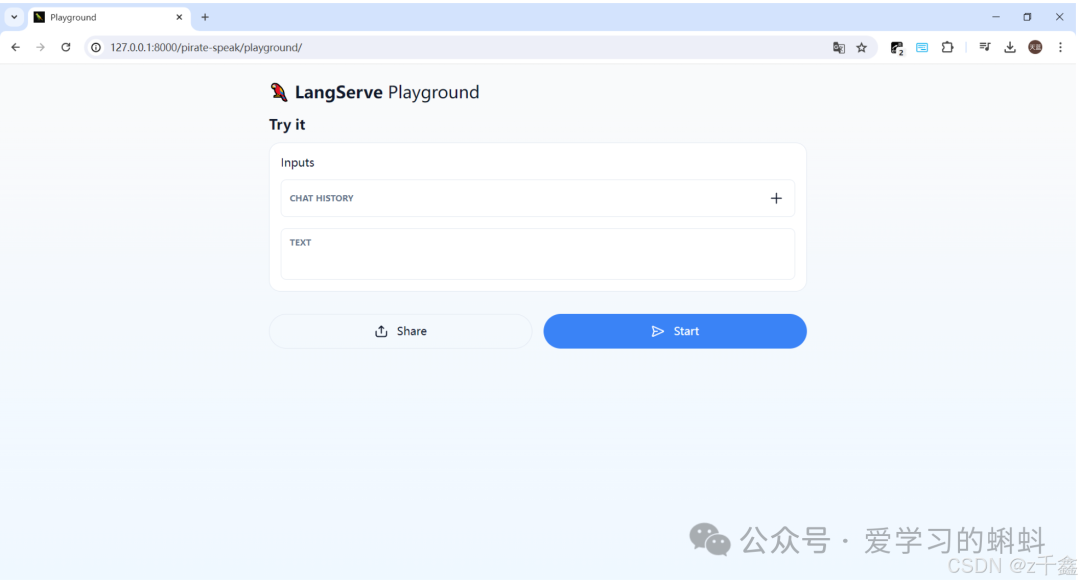
poetry run langchain serve
最后,您可以在浏览器中访问 http://127.0.0.1:8000/pirate-speak/playground/ 来查看和使用应用。
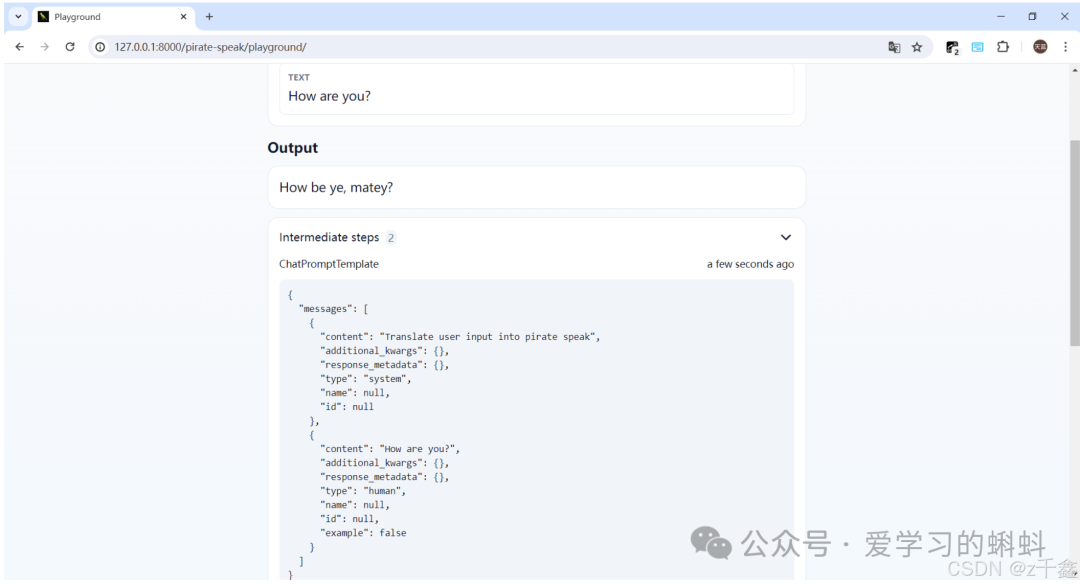
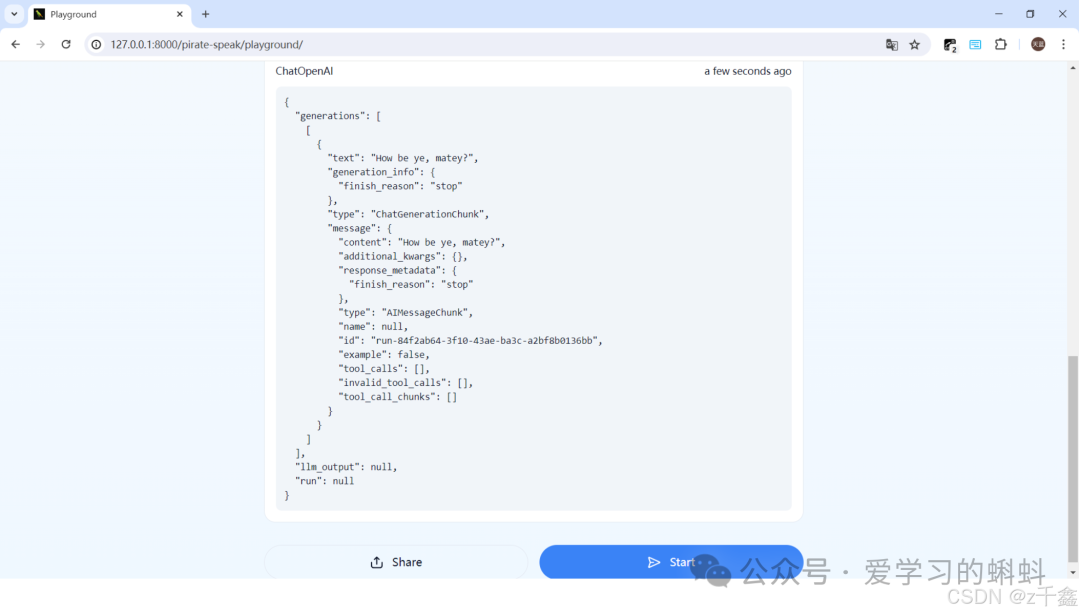
在这里插入图片描述
CSV-Agent 模板配置
在完成上述模板的配置后,您可以直接配置 CSV-Agent 模板,跳过部分步骤。
配置步骤
-
添加 CSV-Agent:在
my-app目录下运行以下命令:poetry run langchain app add csv-agent
- 输入
Y后等待安装完成。如果遇到网络问题,请参考之前的解决办法。
-
**修改
server.py**:在./app/server.py中添加以下内容:from csv_agent import agent_executor as csv_agent_chain add_routes(app, csv_agent_chain, path="/csv-agent") # Windows 系统中将 "\" 改为 "/" -
启动应用:运行以下命令启动应用:
poetry run langchain serve
处理反序列化错误
如果在启动时遇到以下错误:
`ValueError: The de-serialization relies loading a pickle file. Pickle files can be modified to deliver a malicious payload that results in execution of arbitrary code on your machine. You will need to set `allow_dangerous_deserialization` to `True` to enable deserialization. `
解决方案
-
打开
faiss.py文件:找到报错信息中提到的faiss.py文件,路径通常类似于:C:\xxxxxx\anaconda3\envs\LCTest\Lib\site-packages\langchain_community\vectorstores\faiss.py -
**修改
allow_dangerous_deserialization**:在文件中找到allow_dangerous_deserialization的相关代码,将其设置为True:allow_dangerous_deserialization = True注意:确保您信任要反序列化的文件来源。仅在确认文件未被他人修改的情况下执行此操作。
使用应用
启动应用后,您可以在浏览器中访问以下链接来查看和使用 CSV-Agent:http://127.0.0.1:8000/csv-agent/playground
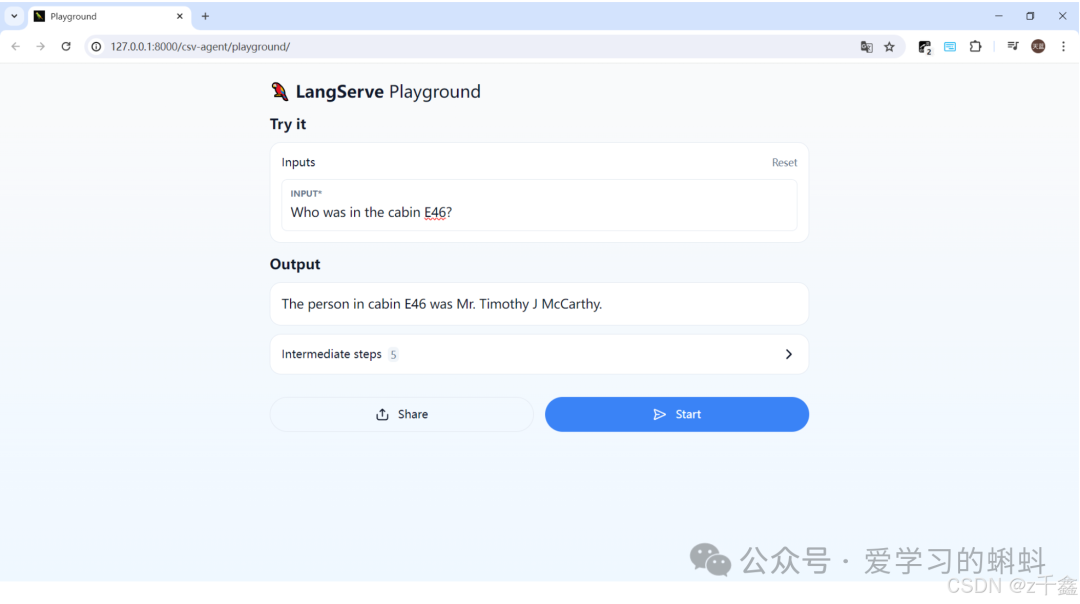
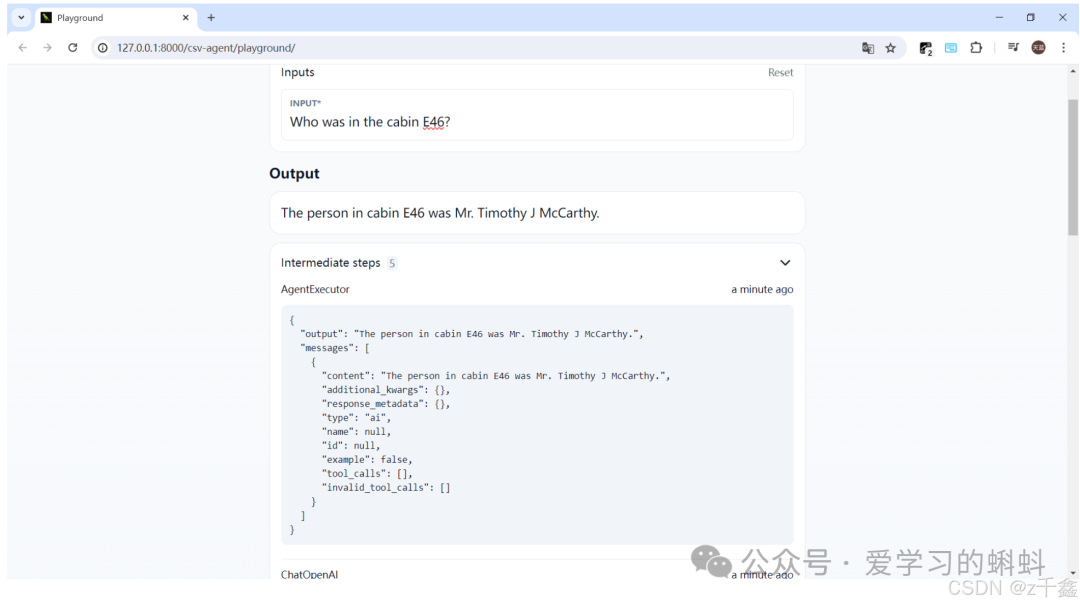
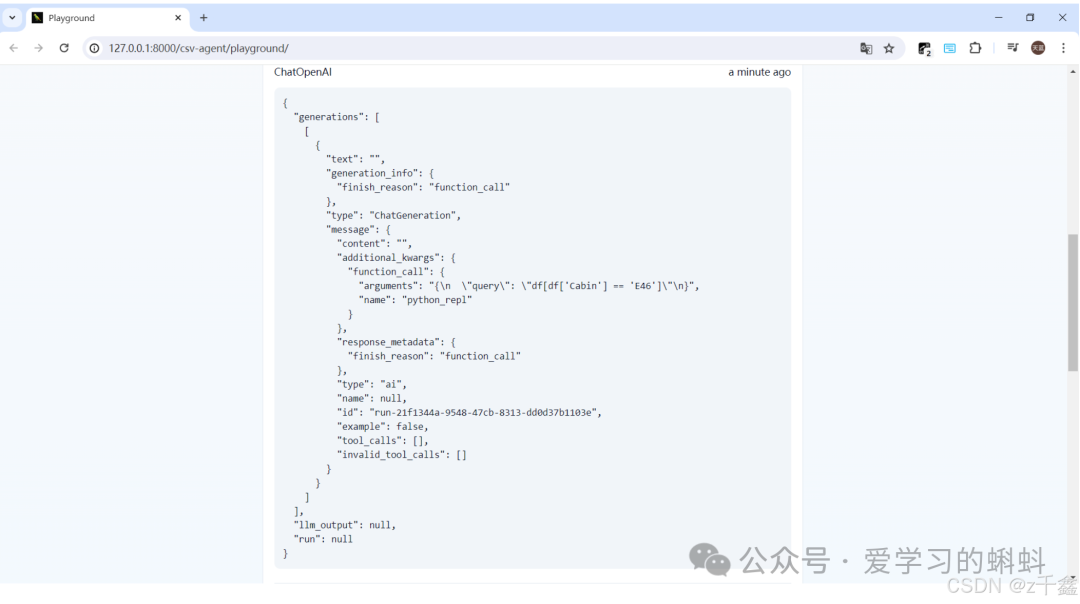
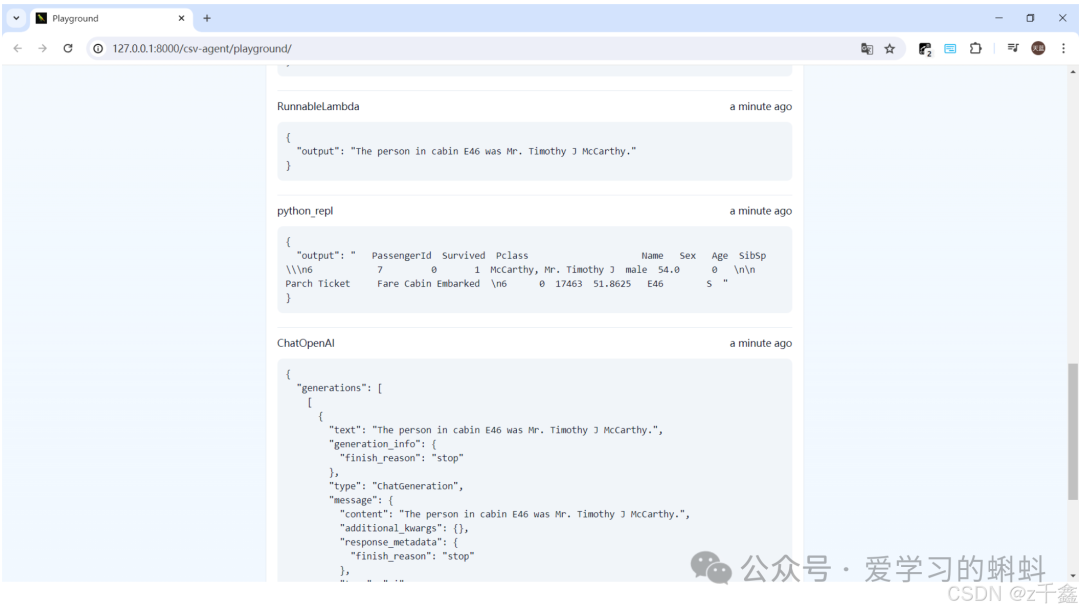
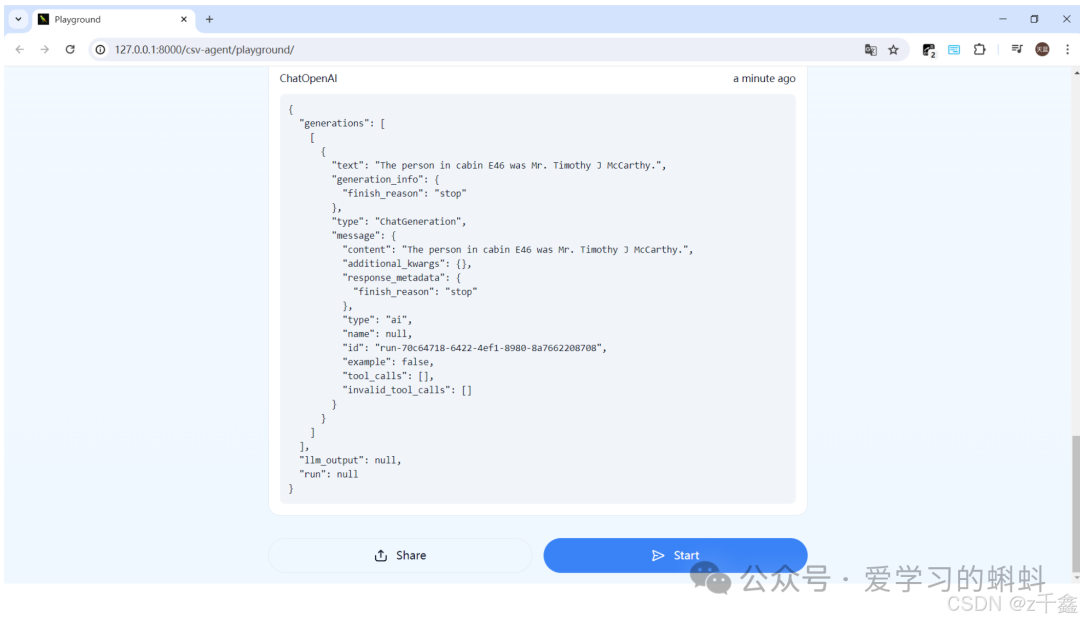
LangChain LCEL 概述
什么是 LCEL?
LangChain Expression Language(LCEL)是 LangChain 工具包的重要组成部分,旨在提供一种声明式方法,用于组合不同组件以创建处理链(chain)。LCEL 的设计理念是提供一个强大而灵活的方式来组合不同的组件和服务,从而创建复杂的工作流程。通过 LCEL,开发者可以定义数据的流动方式,以及如何在 LangChain 的不同组件之间转换和处理数据。
获取OpenAI API KEY的两种方式,开发者必看全方面教程,点击就在这里!
LCEL 的设计目标
-
提高效率和灵活性:LCEL 旨在提高文本处理任务的效率,支持流处理、批处理和异步任务,具有模块化架构,方便用户定制和修改链组件。
-
简化复杂链的构建:为涉及多次大型语言模型(LLM)调用的复杂链提供简单的解决方案。
-
与 LangSmith 平台兼容:LCEL 设计时考虑了与 LangSmith 平台的配合,帮助用户从原型开发过渡到生产阶段。
LCEL 的主要特点
- 流媒体支持:
- LCEL 构建的链可以以流的形式直接从 LLM 获取并处理输出,提供快速响应。
- 异步支持:
- 允许链以同步或异步的方式执行,适合在不同环境下(如 Jupyter 笔记本或 LangServe 服务器)使用。
- 优化的并行执行:
- LCEL 链中的步骤如果能够并行执行,框架会自动优化以减少延迟。
- 重试和回退机制:
- 为链的任何部分配置重试和回退策略,提高链的可靠性。
- 访问中间结果:
- 允许在最终输出产生之前访问中间步骤的结果,有助于调试和提供反馈。
- 输入和输出模式:
- 为每个 LCEL 链提供推断出的 Pydantic 和 JSONSchema 模式,有助于验证输入和输出。
- 与 LangSmith 和 LangServe 的集成:
- LCEL 链自动记录到 LangSmith 以便于跟踪和调试,同时可以使用 LangServe 进行部署。
LCEL 的应用示例
LCEL 通过管道符 | 来连接不同的组件,创建一个处理链。例如,一个简单的链可能如下所示:
chain = (prompt | model | output_parser)
这个链将用户的输入传递给提示模板,模板生成的提示再传递给模型进行处理,最后由输出解析器将模型的输出转换为最终结果。
实际应用
LCEL 不仅支持简单的链,还可以构建更复杂的链,例如结合向量数据库进行检索增强的生成(RAG)查询。在这些复杂的应用中,LCEL 提供了 RunnableMap、RunnableParallel 等原语来并行化组件、动态配置内部链等。
OpenAI API KEY
获取OpenAI API KEY的两种方式,开发者必看全方面教程,点击就在这里!

读者福利:倘若大家对大模型抱有兴趣,那么这套大模型学习资料肯定会对你大有助益。
针对0基础小白:
如果你是零基础小白,快速入门大模型是可行的。
大模型学习流程较短,学习内容全面,需要理论与实践结合
学习计划和方向能根据资料进行归纳总结
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
这里我们能提供零基础学习书籍和视频。作为最快捷也是最有效的方式之一,跟着老师的思路,由浅入深,从理论到实操,其实大模型并不难。




👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

学习路上没有捷径,只有坚持。但通过学习大模型,你可以不断提升自己的技术能力,开拓视野,甚至可能发现一些自己真正热爱的事业。
最后,送给你一句话,希望能激励你在学习大模型的道路上不断前行:
If not now, when? If not me, who?
如果不是为了自己奋斗,又是为谁;如果不是现在奋斗,什么时候开始呢?

















 213
213

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









