python爬虫脚本(获取小说)
一.以下为思路分析参考
1.通过网页的开发者工具提取想要摘取的小说所需要的东西
(1)目标URL地址和请求类型(当前举例为get)
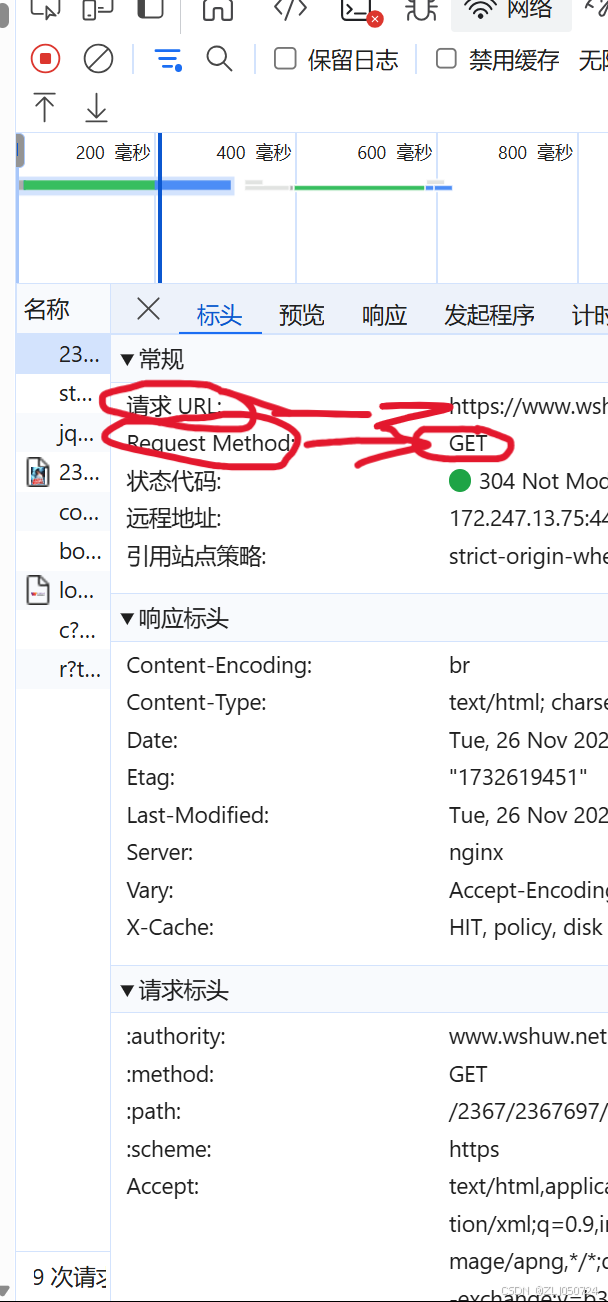
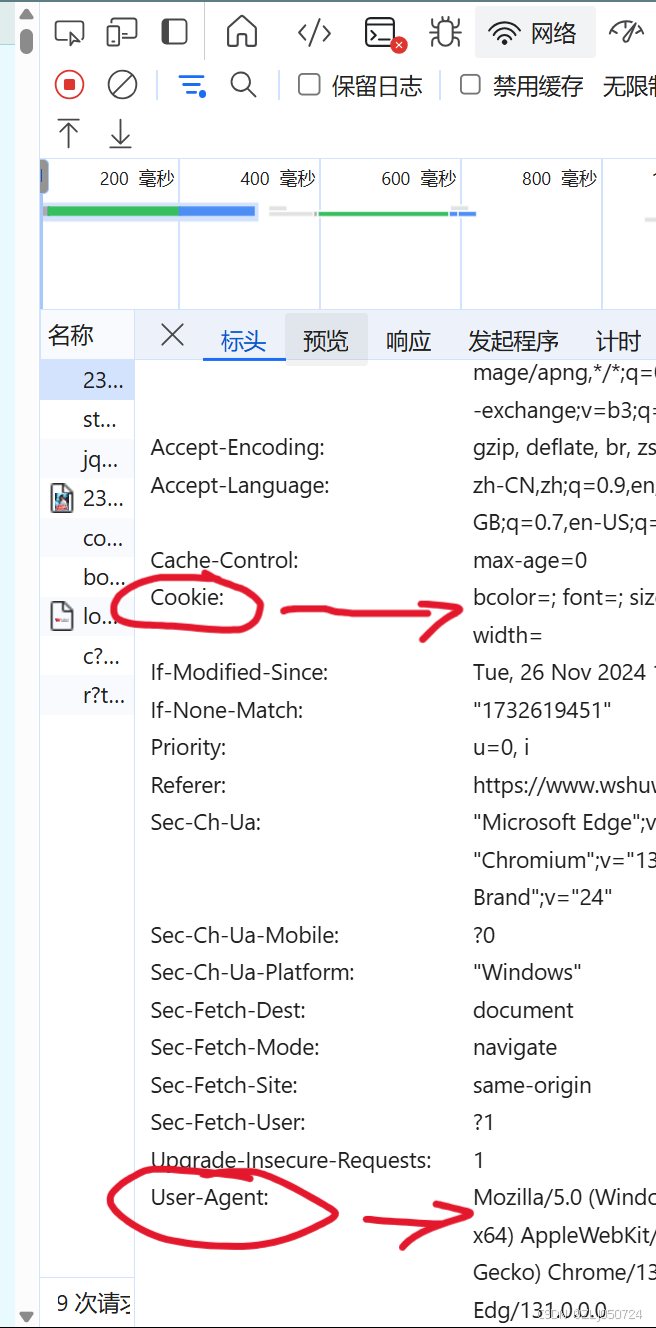
(2)请求头信息,包括Cookie(可以不要)和User-Agent
二.代码实现
1.获取小说目录
import requests
headers = {
'Cookie': '',
'User_Agent': ''
}
url = "https://www.wshuw.net/2367/2367697/"
response = requests.get(url=url, headers=headers)
content = response.text
import re
p = r'<dd><a href ="(.*?)">(.*?)</a></dd>'
chs = re.findall(p, content, re.DOTALL)
chapter = dict()
for ch in chs:
chapter[ch[1]] = "https://www.wshuw.net" + ch[0]
i = 7824
while i <= 7835:
chapter.pop(f'第{i}章')
i += 1
for i in chapter:
print(i, chapter[i])
import json
with open('chapters.txt', 'wt', encoding='utf-8') as file:
json.dump(chapter, file)
2.获取小说的章节内容
import requests, re
import time, random
import json
with open("chapters.txt", encoding="UTF-8") as file:
chs = json.load(file)
headers = {
'Cookie': 'x-web-secsdk-uid=91a9b1fd-26c3-4a04-a5d7-444bbee22c10; Hm_lvt_2667d29c8e792e6fa9182c20a3013175=1732345091; HMACCOUNT=07C9417AE3A8436C; s_v_web_id=verify_m3ttjfuo_9hL0iFhg_9eld_4BFr_84Q0_7sguuhzNKDMe; csrf_session_id=03e5b6e78edf718e6881f63ca28cbc3c; novel_web_id=7440365449727313459; Hm_lpvt_2667d29c8e792e6fa9182c20a3013175=1732345426; ttwid=1%7C2zZ8x9gEPHxD4IjMlzwSZrSTLJvygVrVQ6WIc4ZRJIQ%7C1732345427%7Cdc1fe6dc4be7b1bd74911d679bc61b4e2a208030d1b5d174a0abd0750c917216',
'User_Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36 Edg/131.0.0.0'
}
for title, url in chs.items():
print(f"准备采集: {title}")
response = requests.get(url, headers=headers)
html = response.text
p = r'<div id="content" class="showtxt">(.*?)</div>'
content = re.search(p, html, re.DOTALL)
content = content.group(1).strip()
content = re.sub("", "", content)
content = re.sub(";", "", content)
content = re.sub("<br />", "", content)
content = re.sub("app2", "", content)
content = re.sub("read2", "", content)
content = content.replace("()", "")
with open("我,杂役弟子,剑道无敌.txt", mode="at", encoding="utf-8") as file:
file.write("\n\n-----------------------\n\n")
file.write("\n\n" + title + "\n\n")
file.write(content)
time.sleep(random.randint(3, 5))
print(f"{title} 章节采集完成")






















 1547
1547

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









