



CoT 优势
在工业级 AI 系统建设中,CoT 展现出多重应用价值:
1. 复杂问题求解:通过问题分解(Problem Decomposition)将计算资源动态分配至关键推理节点;
2. 模型可解释性:推理链输出使开发者能定位错误节点(如数学公式误用、知识检索偏差),相比黑箱模型,CoT 的推理链输出使调试更有依据;
3. 跨模型泛化性:兼容 Transformer 系列、MoE 架构等主流模型,仅需添加提示词即可实现能力迁移。
在复杂推理任务中,思维链(CoT)可以显著提升模型的推理能力。然而,CoT 数据的获取一直高度依赖人工标注,难以大规模生成和应用。DeepSeek-R1 通过强化学习优化了这一流程,使模型能够自主生成高质量 CoT 数据,并公开了这一方法,让端到端训练更加高效可复现。此外,DeepSeek 还利用大模型生成的数据训练小模型,让小模型也具备强大的推理能力,从而降低推理成本,使高质量推理能力更易落地应用。
2. 训练的过程
关于模型与流程可以简单分为 4 个阶段:
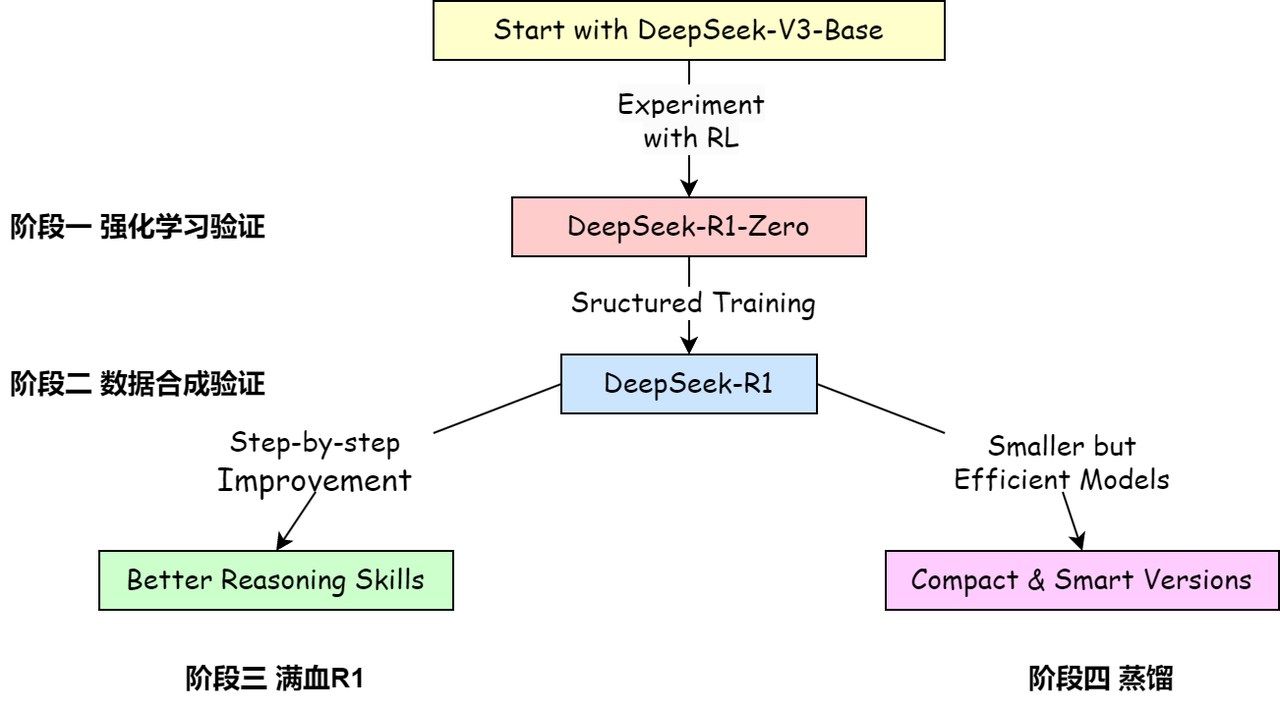
1️⃣阶段一:强化学习验证,对 DeepSeek-V3 进行纯粹的强化学习,获得 DeepSeek-R1-Zero
2️⃣阶段二:数据合成模型,使用 DeepSeek-R1-Zero 生成数据训练 DeepSeek-V3,得到 DeepSeek-V3-checkpoint,并用 DeepSeek-V3-checkpoint 生成 600k 的推理数据集
3️⃣阶段三:DeepSeek-R1 训练,混合推理数据以及非推理数据集(800k),对模型 DeepSeek-V3 进行全参数微调,获得 DeepSeek-R1
4️⃣阶段四:蒸馏实验,使用与训练 R1 相同的混合数据集,对各开源模型(Qwen,Llama)进行全参数微调,获得 DeepSeek-R1-Distill-(Qwen/Llama)-(*B)
🚨注意:实验证明,只有 “足够聪明” 的基模型才能进行后续的强化学习训练,所以这里的基模型的选择,deepseek 使用了他们本身数理能力就足够强的 MoE 模型,deepseek-V3 作为基础进行训练。

















 7423
7423

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









