



1. 蒸馏原理
所谓 “知识蒸馏”,简单来讲就是通过 “某种方式” 来让小模型学习到大模型的 “某方面优势”。这里的 “某方面优势” 对于 R1 来说,就是 R1 的推理能力,而 “某种方式” 简单来讲就是监督微调(Supervised Fine-Tuning,即 SFT)。而监督微调的数据,就是 R1 推理时生成的思维链。基本思路如下:
1️⃣选定某领域数据集 {question:"xxxxx?", answer:"yyyyy"},取其中的 question:"xxxxx?" 利用 DeepSeek R1 模型进行推理,对推理结果进行筛选和清洗,得到 R1 带思维链数据 R1_CoT_Ans:"wwwwww"。
2️⃣将数据集中的原问题 "xxxxx?" 与 R1 的思维链数据组成新的数据集:{question:"xxxxx?", R1_CoT_Ans:"wwwwww"},作为微调小模型的数据集,即蒸馏数据集。
3️⃣利用新数据集 {question:"xxxxx?", R1_CoT_Ans:"wwwwww"} 对小模型进行监督微调,并对微调后的小模型进行评测,比较微调前后模型的效果。
清楚基本原理后,我们就可以设计我们的蒸馏方案了。
2. 蒸馏方案
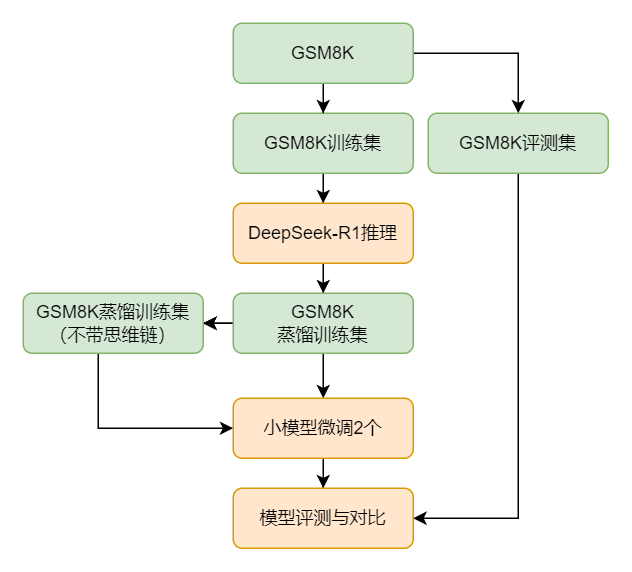
我们使用 DeepSeek-R1 来对小模型进行蒸馏,其过程大致如下图所示:首先我们选取 GSM8K 数据集,使用其训练集中的题目来不断喂给 DeepSeek-R1 来获得用于训练的问答对,在获得蒸馏训练集后为了查看思维链在其中的效果,我们还单独剔除了数据集中的思维链来作为另外一个训练集,基于这两个训练集分别微调出两个小模型,最后我们对微调后的两个小模型、DeepSeek-R1 以及微调前的小模型进行评测以查看提升效果。
数据准备
这里我们选用 GSM8K(Grade School Math 8K),该数据集由 OpenAI 团队构建,是一个用于数学问题求解的文本数据集,其中包含了 8000 多个小学数学水平的问题(训练集:7473 题,测试集:1319 题)。这些问题主要涉及基本的算术运算,如加法、减法、乘法和除法,以及一些简单的数学应用题。每个问题都附有自然语言形式的答案,这些答案不仅提供了最终的结果,还详细解释了解题的步骤和过程。下面是该数据集中的一条数据:
{
"question": "James decides to run 3 sprints 3 times a week. He runs 60 meters each sprint. How many total meters does he run a week?",
"answer": "He sprints 3*3=<<3*3=9>>9 times\nSo he runs 9*60=<<9*60=540>>540 meters\n#### 540"
}可以看到该数据集中答案都以 \n#### ans 开头,该特性方便我们对模型的推理效果有一个明确的数值评价。
蒸馏数据
接下来我们对 GSM8K 数据集中的训练数据集进行重建,获得用于蒸馏小模型的训练集。数据集重建的目的在于:我们希望获得一个带有思维链的且最终提供正确格式和正确答案的回答。主要过程是:
1️⃣提取 GSM8K 数据集的训练集:7473 个题目,去除其中的回答,仅保留提问。
2️⃣将 7473 个题目喂给 DeepSeek-R1,保存其对应的输出来作为新的回答,即实现问答对的重建。
以下几个关键点要注意:
-
DeepSeek-R1 要明确让它将答案放到 '\\boxed {true_answer}' 中,所以需要对它设置一个 Prompt:<|begin▁of▁sentence|>You are a math problem solver. Provide the final answer in a boxed format using \\boxed {{answer}}.\n<|User|>{question}<|Assistant|>,其中 question 就是放置题目的地方;
2. 为了提升推理的速度,需要尽量将并发量提高(可根据供应商的并发量限制来最大化设置);
3. DeepSeek-R1 生成的答案需要满足一定的标准才能被保存,具体要求如下:
1️⃣推理的答案中必须包含标准答案,且满足格式:'\\boxed {{{true_answer}}}'
2️⃣推理的答案中需要包含思维链,筛选标志:</think>
4. 保存答案的策略:如果不满足上述两个保存的条件,那么该问题就会被记录下来,完成一轮推理后再把记录下来的所有问题再重新进行一轮。该过程会至少重复 15 次。
最终得到构造的满足需求的问答对如下:
{
"instruction": "Mel is three years younger than Katherine. When Katherine is two dozen years old, how old will Mel be in years?",
"output": "<think>\nOkay, let's see. The problem says Mel is three years younger than Katherine. So, if I figure out Katherine's age first, then I can subtract three to get Mel's age. \n\nThe question is asking, when Katherine is two dozen years old, how old will Mel be? Hmm, a dozen is 12, so two dozen would be 24. Wait, is that right? Yeah, 12 times 2 is definitely 24. So Katherine will be 24 years old at that time.\n\nSince Mel is three years younger, I need to subtract 3 from Katherine's age. Let me do the math here: 24 minus 3 equals 21. So that should be Mel's age when Katherine is 24. Let me double-check. If Mel is always three years younger, then no matter when, the difference stays the same. So when Katherine is 24, subtracting 3 gives 21. Yeah, that makes sense. I think that's the answer.\n</think>\n\nWhen Katherine is two dozen (24) years old, Mel, being three years younger, will be:\n\n\\boxed{21}",
"input": ""
}其中:
-
instruction 是 GSM8K 中的 question 问题;
-
output 是 DeepSeek-R1 输出的,带思维链的且格式和答案都正确的回答;
-
input 为空,主要微调训练的时候需要该字段;
微调模型
-
技术选型:和上期教程一样采用 LoRA(Low-Rank Adaptation) 实现轻量微调,显著降低计算开销;
-
参数配置:

这里在微调模型的过程中,主要采用了 基于 DeepSeek-R1 蒸馏出的数据集。同时,为了验证其中的思维链是否真的有效,以作为对比,我们可以将该数据再次处理,去除其中的思维链部分。也就是说在微调部分,需要微调出两个模型:一个基于蒸馏出的数据集,另外一个是基于去除掉思维链的蒸馏数据集。
模型评测
在获得微调的模型之后,需要对模型进行评测。这里我们采用如下标准:
-
评测标准:
⚒️数值正确性:生成答案与标准答案完全匹配;
⚒️格式合规性:答案需以 \\boxed {...} 包裹。
-
对比实验设计:
⚒️蒸馏前模型:未经优化的原始小模型;
⚒️蒸馏后模型 1:基于完整蒸馏数据(带思维链)微调的模型;
⚒️蒸馏后模型 2:基于不带思维链的蒸馏数据微调的模型;
⚒️基准模型:DeepSeek-R1 作为性能上限参考。


















 1227
1227

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









