







引言:当 LLM 遇上“外部大脑”
大型语言模型(LLM),如 GPT 系列、Qwen系列、DeepSeek系列、Claude、Llama、GLM系列 等,无疑是近年来人工智能领域最耀眼的明星。它们强大的自然语言理解和生成能力,正在深刻地改变着我们与信息的交互方式,从写邮件、编代码到进行创意写作,LLM 展现出了惊人的潜力。然而,正如再聪明的学生也有知识边界,这些强大的 AI 模型也并非无所不能,它们面临着固有的局限性。
想象一下,你向一个非常博学但自毕业后就没再更新知识的专家咨询最新的行业动态,或者让他回忆某个非常具体、只在少数内部文档中记载的细节,他很可能会遇到困难,甚至可能“自信地”给出错误的答案。LLM 也面临类似的问题。
为了克服这些局限,一种强大的范式应运而生,它就是我们这个专栏的主角——检索增强生成(Retrieval-Augmented Generation, RAG)。简单来说,RAG 就像是给 LLM 配备了一个可以实时查询的、动态更新的“外部大脑”或“开放式笔记”,让它在回答问题或生成内容时,能够基于最新的、相关的、甚至私有的信息。
本章作为 RAG 实战专栏的开篇,将带您一起:
- 深入理解 LLM 面临的核心挑战。
- 揭开 RAG 的神秘面纱,了解其基本原理和核心思想。
- 认识 RAG 带来的关键价值和优势。
- 鸟瞰 RAG 的基础架构和工作流程。
- 探索 RAG 的典型应用场景。
- 并提前认识到 RAG 实践中评估与伦理的重要性。
准备好了吗?让我们一起踏上 RAG 的探索之旅!
1.1 LLM 的局限性:光环之下的挑战
尽管 LLM 能力非凡,但在实际应用中,我们很快会遇到它们的“阿喀琉斯之踵”:
- 知识过时(Knowledge Cutoff): 大多数 LLM 的知识都来自于其训练数据,而这些数据通常截止于某个特定的时间点。这意味着模型无法获知这个时间点之后发生的事件、新知识或信息更新。比如,你问一个去年训练的模型“本周的热点新闻是什么?”,它很可能无法回答,或者给出过时的信息。
- 幻觉频发(Hallucination): 这是 LLM 最令人头疼的问题之一。当模型遇到其知识范围之外的问题,或者对其内部知识“记忆不清”时,它有时会“一本正经地胡说八道”,即生成看似合理但实际上是虚假、捏造或与事实不符的信息。这种“自信的错误”在需要高准确性的场景下是致命的。
- 领域知识鸿沟(Domain Knowledge Gap): 通用 LLM 通常在广泛的公开数据上训练,对于特定行业、特定公司或特定产品的深入、细粒度的知识(如内部规章制度、专业技术手册、非公开的项目文档)往往知之甚少。直接让它们处理这些专业领域的任务,效果通常不佳。
- 缺乏溯源性(Lack of Traceability): LLM 的回答往往像一个“黑箱”,我们很难知道它是基于哪些信息得出结论的,这使得验证答案的准确性和可靠性变得困难。
正是这些局限性,催生了对更可靠、更可信、更能利用特定知识的 AI 解决方案的需求,而 RAG 正是应对这些挑战的有力武器。
1.2 RAG 诞生:检索先行,生成有据
面对 LLM 的局限,我们不禁思考:能不能让 LLM 在回答前,先去“查查资料”呢?RAG 的核心思想正是如此。
-
定义与核心思想: RAG 是一种结合了信息检索(Information Retrieval)和自然语言生成(Natural Language Generation)的技术范式。其核心流程可以概括为三步:
- 检索 (Retrieve): 当收到用户查询时,系统首先不是直接交给 LLM,而是利用用户的查询去一个外部知识源(如文档集合、数据库、知识图谱)中检索出最相关的信息片段。
- 增强 (Augment): 接着,将这些检索到的相关信息片段(称为上下文 Context)与用户的原始查询整合起来,形成一个新的、更丰富的提示词 (Augmented Prompt)。这里的“增强”是关键,它意味着我们主动地将相关的外部知识注入到即将给 LLM 的指令中。
- 生成 (Generate): 最后,将这个“增强后”的提示词喂给 LLM,要求它基于提供的上下文信息来生成最终的答案或内容。
-
关键依赖: RAG 系统效果的天花板很大程度上取决于检索阶段。如果检索器无法找到准确、相关的上下文信息,或者检索到了错误、无关的信息(“Garbage In”),那么即使 LLM 再强大,也很难生成高质量、可靠的答案(“Garbage Out”)。因此,如何构建高质量的知识库和设计高效的检索策略,是 RAG 实践的核心挑战,也是我们后续章节将深入探讨的内容。
-
对比 Fine-tuning: 另一种让 LLM 学习特定知识的方法是微调(Fine-tuning),即使用特定领域的数据继续训练 LLM。RAG 和 Fine-tuning 各有优劣,需要根据场景权衡:
- RAG 优势: 知识更新更方便(只需更新知识库)、幻觉更少(基于给定上下文)、可溯源、成本相对较低(无需重新训练大模型)。
- Fine-tuning 优势: 可以让模型学习特定的风格、语气或隐式知识,对于需要模型深度理解和模仿特定模式的任务可能更有效。
- 权衡(Trade-offs): RAG 更适合知识密集型、需要实时性、可溯源性的问答或生成任务;Fine-tuning 更适合需要模型“内化”特定行为模式或风格的任务。实践中,两者也可以结合使用。
1.3 RAG 的核心优势与价值
采用 RAG 架构,能为我们的 AI 应用带来诸多显著的优势:
- 提升知识时效性,显著减少幻觉: 通过实时检索外部最新知识源,RAG 极大地缓解了 LLM 的知识过时问题。同时,要求 LLM 基于明确提供的上下文作答,能有效抑制其“自由发挥”产生幻觉的倾向。
- 提供答案溯源,提升可解释性与可信度: RAG 的一大亮点是,我们可以(也应该)让 LLM 在生成答案时,明确指出它参考了哪些检索到的上下文片段(Citations/Sources)。这大大提高了答案的可信度,用户可以自行查证来源,增强了系统的透明度和可解释性。
- 高效注入领域知识,实现个性化: RAG 使得向 LLM 注入特定领域的专业知识或私有数据变得非常高效。只需将相关文档或数据构建成可检索的知识库即可,无需昂贵的模型重训练。这使得构建面向特定业务场景(如公司内部知识库)或个性化(如基于用户历史邮件的问答)的应用成为可能。
- 相对更优的成本效益与开发效率: 相比于动辄需要大量算力进行微调甚至预训练,构建和维护一个 RAG 知识库的成本通常更低。同时,对于知识更新频繁的场景,RAG 的开发和维护效率也更高。
1.4 RAG 基础架构与核心组件
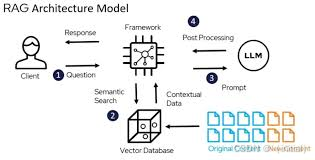
为了更直观地理解 RAG 的工作方式,让我们来分解一下它的基础流程和核心组件:
- 用户查询 (Query): 用户提出的问题或指令。
- 检索器 (Retriever): 这是 RAG 的“信息搜集员”。它的任务是理解用户查询的意图,并从配置好的知识库 (Knowledge Base)(可能是向量数据库、传统搜索引擎、知识图谱等)中,找出与查询最相关的若干信息片段(上下文 Context)。后续章节将深入探讨如何设计和优化检索器。
- 获取相关上下文 (Context): 检索器返回的一个或多个信息片段,这些是 LLM 回答问题的主要依据。
- 增强提示词 (Augmented Prompt): 将原始的用户查询和检索到的上下文 Context 按照特定模板组合起来,形成最终喂给 LLM 的指令。这个 Prompt 通常会明确要求 LLM 基于提供的 Context 作答。
- 生成器 (Generator - LLM): 也就是大型语言模型。它接收增强后的提示词,理解其中的指令和上下文信息,并生成最终的文本答案。后续章节也会讨论如何选择 LLM 以及如何通过 Prompt Engineering 与之高效交互。
- 最终答案 (Response): LLM 生成的,理想情况下是基于所提供上下文的、准确且相关的回答,可能还包含来源引用。
这个流程清晰地展示了 RAG 如何通过“检索”来“增强”LLM 的“生成”能力。
1.5 典型应用场景(结合微型案例)
RAG 的能力使其在众多场景下都能大放异彩:
- 企业知识库问答: 员工可以快速查询公司内部的规章制度、产品文档、技术手册、历史项目资料等。(例如:“根据最新的员工手册,年假申请需要提前多少天提交?”)
- 智能客服与技术支持: 自动根据产品文档、FAQ、知识库文章回答用户的咨询和报障。(例如:“我的 X 型号打印机出现错误代码 E05,根据手册应该如何处理?”)
- 内容创作助手: 辅助撰写报告、文章、邮件,可以要求模型基于提供的背景资料或实时信息进行创作,并自动引用来源。(例如:“根据我提供的这三篇市场分析报告,总结一下 A 产品的竞争优势,并列出报告来源。”)
- 研究分析工具: 帮助研究人员快速检索、阅读和总结大量文献,或者基于特定数据集进行问答。(例如:“根据这篇论文的第三章,作者提出的主要实验方法是什么?”)
- 个性化推荐解释: 不仅给出推荐结果,还能基于用户历史行为或产品知识库解释推荐的原因。
这些场景都凸显了 RAG 在结合通用语言能力与特定领域知识方面的独特优势。
1.6 重要性前置:为何评估 RAG 如此关键且具有挑战性?
在兴奋地投入 RAG 开发之前,我们必须认识到评估其效果的重要性与复杂性。为何关键?因为 RAG 系统的最终价值直接取决于其输出的质量和可靠性。为何具有挑战性?
- 多组件耦合: RAG 的效果是检索器和生成器共同作用的结果。问题可能出在检索(没找到、找错了),也可能出在生成(没理解上下文、表达不清),或者是两者交互不良。评估需要能够区分问题来源。
- 评估维度多元: 仅仅看答案是否“看起来对”是远远不够的。我们需要评估答案是否忠实于提供的上下文(Faithfulness)、是否真正回答了用户的问题(Answer Relevancy)、检索到的上下文本身是否与问题相关(Context Relevancy),以及答案的流畅性、安全性等。
- 缺乏标准答案: 很多 RAG 场景(尤其是开放域问答)并没有唯一的标准答案,使得自动化评估更加困难。
因此,建立一套有效的评估体系,结合自动化指标和必要的人工评估,是贯穿 RAG 系统开发、优化和维护全过程的核心任务。我们将在后续章节(特别是第六章)深入探讨 RAG 的评估方法和工具。
1.7 初步伦理考量:技术向善的基石
与所有强大的 AI 技术一样,RAG 的应用也伴随着伦理责任:
- 数据来源版权: 用于构建知识库的数据是否拥有合法授权?尤其在使用网络爬取或第三方数据时,需要关注版权问题。
- 偏见传播: 如果知识库本身包含偏见信息(如性别歧视、刻板印象),RAG 系统可能会在检索和生成过程中放大这些偏见。
- 信息真实性风险: 即使 RAG 能减少幻觉,但如果检索到的信息本身就是错误的或过时的,生成的答案依然可能是错误的。如何保证知识库的质量和准确性是一个持续的挑战。
- 隐私保护: 如果知识库包含个人敏感信息,需要确保在检索和生成过程中不会泄露隐私。
在设计和部署 RAG 系统时,必须将这些伦理因素纳入考量,采取必要的措施(如数据审核、偏见检测、访问控制、内容过滤),确保技术的负责任应用。
结语:开启 RAG 的探索之旅
本章我们初步认识了 RAG,理解了它为何出现、基本如何工作、能带来什么价值,以及在实践中需要关注的关键考量(评估与伦理)。RAG 不是一个简单的“即插即用”模块,而是一个需要精心设计、构建、评估和优化的系统工程。
接下来的章节,我们将深入 RAG 的内部,逐一解构其核心组件:从如何构建高质量的知识库(包括向量库和知识图谱),到设计先进的检索策略,再到与 LLM 的高效协同,以及如何评估和优化整个系统。让我们一起动手,揭开 RAG 的更多奥秘,掌握构建强大知识增强型 AI 应用的钥匙!
内容同步在gzh:智语Bot



















 742
742

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











