









总目录:人脸检测与表情分类
https://blog.youkuaiyun.com/whiffeyf/category_12793480.html
b站视频: https://www.bilibili.com/video/BV1u4W4eCERn/
这篇博客主要是讲的是,如何使用表情分类模型进行表情分类
前提
注意,输入的图片是裁剪好的人脸图,如:

检测人脸与检测参考:YOLOv7-face人脸检测
模型下载
https://download.youkuaiyun.com/download/WhiffeYF/89654401
解压后使用 emotion.pth
表情分类
emotion.py
执行:
python emotion.py --weights emotion.pth --source crops/face/
'''
python emotion.py --weights emotion.pth --source crops/face/
'''
import os
import torch
from torchvision import transforms
from PIL import Image
import torch.nn as nn
import torchvision.models as models
import argparse
class EmotionClassifier:
def __init__(self, model_path, device='cpu'):
self.device = device
self.class_names = ['angry', 'disgust', 'fear', 'happy', 'neutral', 'sad', 'surprise']
self.model = self.load_model(model_path)
self.transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
def load_model(self, model_path):
model = models.mobilenet_v2(pretrained=False)
model.classifier[1] = nn.Linear(model.last_channel, len(self.class_names))
model.load_state_dict(torch.load(model_path, map_location=self.device))
model.eval()
model.to(self.device)
return model
def predict(self, image_path):
image = Image.open(image_path).convert('RGB')
image = self.transform(image).unsqueeze(0).to(self.device)
with torch.no_grad():
outputs = self.model(image)
_, predicted = torch.max(outputs, 1)
predicted_class = self.class_names[predicted.item()]
return predicted_class
def predict_folder(self, folder_path):
results = {}
for filename in os.listdir(folder_path):
if filename.endswith(('.png', '.jpg', '.jpeg')):
file_path = os.path.join(folder_path, filename)
prediction = self.predict(file_path)
results[filename] = prediction
return results
def classify(self, input_path):
if os.path.isdir(input_path):
return self.predict_folder(input_path)
elif os.path.isfile(input_path):
return {os.path.basename(input_path): self.predict(input_path)}
else:
raise ValueError(f"Invalid path: {input_path}")
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default='emotion.pth')
parser.add_argument('--source', type=str, default='crops/face/')
opt = parser.parse_args()
weights = opt.weights
source = opt.source # 可以是单张图片路径或图片文件夹路径
'''
model_path = 'emotion.pth'
input_path = 'crops/face/'
'''
classifier = EmotionClassifier(weights)
predictions = classifier.classify(source)
for filename, emotion in predictions.items():
print(f'{filename}: {emotion}')
结果

表情分类改进
emotion.py
输出情绪分类的分布情况
'''
python emotion.py --weights emotion2.pth --source YS-emotion/happy
python emotion.py --weights emotion2.pth --source YS-emotion/neutral
python emotion.py --weights emotion.pth --source YS-emotion/happy
python emotion.py --weights emotion.pth --source YS-emotion/neutral
'''
import os
import torch
from torchvision import transforms
from PIL import Image
import torch.nn as nn
import torchvision.models as models
import argparse
class EmotionClassifier:
def __init__(self, model_path, device='cpu'):
self.device = device
self.class_names = ['angry', 'disgust', 'fear', 'happy', 'neutral', 'sad', 'surprise']
self.model = self.load_model(model_path)
self.transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
def load_model(self, model_path):
model = models.mobilenet_v2(pretrained=False)
model.classifier[1] = nn.Linear(model.last_channel, len(self.class_names))
model.load_state_dict(torch.load(model_path, map_location=self.device))
model.eval()
model.to(self.device)
return model
def predict(self, image_path):
image = Image.open(image_path).convert('RGB')
image = self.transform(image).unsqueeze(0).to(self.device)
with torch.no_grad():
outputs = self.model(image)
_, predicted = torch.max(outputs, 1)
predicted_class = self.class_names[predicted.item()]
return predicted_class
def predict_folder(self, folder_path):
results = {}
for filename in os.listdir(folder_path):
if filename.endswith(('.png', '.jpg', '.jpeg')):
file_path = os.path.join(folder_path, filename)
prediction = self.predict(file_path)
results[filename] = prediction
return results
def classify(self, input_path):
if os.path.isdir(input_path):
results = self.predict_folder(input_path)
self.count_emotions(results)
return results
elif os.path.isfile(input_path):
result = {os.path.basename(input_path): self.predict(input_path)}
self.count_emotions(result)
return result
else:
raise ValueError(f"Invalid path: {input_path}")
def count_emotions(self, predictions):
total = len(predictions)
emotion_count = {emotion: 0 for emotion in self.class_names}
for emotion in predictions.values():
if emotion in emotion_count:
emotion_count[emotion] += 1
print("\nEmotion Distribution:")
for emotion, count in emotion_count.items():
percentage = (count / total) * 100 if total > 0 else 0
print(f"{emotion}: {count} ({percentage:.2f}%)")
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default='emotion.pth')
parser.add_argument('--source', type=str, default='crops/face/')
opt = parser.parse_args()
weights = opt.weights
source = opt.source # 可以是单张图片路径或图片文件夹路径
classifier = EmotionClassifier(weights)
predictions = classifier.classify(source)
'''
for filename, emotion in predictions.items():
print(f'{filename}: {emotion}')
'''
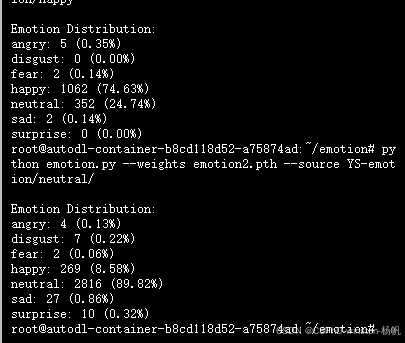
结果


















 889
889

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











