



迁移学习:快速构建高效模型
学习目标
本课程将深入探讨迁移学习的概念,学习如何利用预训练模型进行快速模型开发,减少训练时间和资源消耗。通过本课程,能够理解迁移学习的基本原理,掌握如何选择和使用预训练模型,以及如何在自己的项目中应用迁移学习技术。
相关知识点
- 迁移学习的应用与预训练模型的使用
学习内容
1 迁移学习的应用与预训练模型的使用
1.1 迁移学习的基本概念
迁移学习是一种机器学习方法,它利用在某一任务上训练的模型的知识来帮助解决另一个相关任务。这种方法的核心思想是,如果两个任务之间存在某种相关性,那么在一个任务上学习到的知识可以被用来提高在另一个任务上的学习效率。迁移学习在深度学习领域尤为重要,因为深度神经网络通常需要大量的数据和计算资源来训练,而迁移学习可以显著减少这些需求。
迁移学习的主要优势包括:
- 减少数据需求:通过利用预训练模型,可以在数据量较小的情况下训练出性能良好的模型。
- 减少训练时间:预训练模型已经学习了大量通用特征,因此在新任务上进行微调时,训练时间大大减少。
- 提高模型性能:在某些情况下,迁移学习可以提高模型在新任务上的性能,尤其是在数据量有限的情况下。
1.2 预训练模型的选择与使用
选择合适的预训练模型是迁移学习成功的关键。在选择预训练模型时,需要考虑以下几个因素:
- 模型架构:不同的模型架构适用于不同的任务。例如,卷积神经网络(CNN)通常用于图像识别任务,而循环神经网络(RNN)则适用于序列数据处理。
- 预训练数据集:预训练模型是在特定数据集上训练的,选择与目标任务数据集相似的预训练模型可以提高迁移学习的效果。
- 模型性能:选择在基准测试中表现良好的模型,可以提高在新任务上的性能。
在使用预训练模型时,通常有以下几种方法:
- 特征提取:将预训练模型的某些层作为特征提取器,冻结这些层的权重,只训练新添加的层。
- 微调:在新任务上对预训练模型进行微调,可以调整整个模型或部分层的权重。
下面是一个使用预训练模型进行特征提取的示例代码:
%pip install tensorflow
!wget https://model-community-picture.obs.cn-north-4.myhuaweicloud.com/ascend-zone/notebook_models/f44bca482fdb11f09664fa163edcddae/vgg16_weights_tf_dim_ordering_tf_kernels_notop.h5
!wget https://model-community-picture.obs.cn-north-4.myhuaweicloud.com/ascend-zone/notebook_datasets/d9a445802fdb11f09664fa163edcddae/data.zip
!wget https://model-community-picture.obs.cn-north-4.myhuaweicloud.com/ascend-zone/notebook_datasets/d9a445802fdb11f09664fa163edcddae/glove.6B.50d.txt
!unzip data.zip
import tensorflow as tf
from tensorflow.keras.applications import VGG16
from tensorflow.keras.layers import Dense, Flatten, Embedding, LSTM
from tensorflow.keras.models import Model
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.models import Sequential
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
import numpy as np
# 指定本地权重文件路径
local_weights_path = 'vgg16_weights_tf_dim_ordering_tf_kernels_notop.h5' # 替换为你的实际路径
# 加载预训练的VGG16模型结构(不包括顶部全连接层)
base_model = VGG16(
weights=None, # 不加载默认权重
include_top=False,
input_shape=(224, 224, 3)
)
# 加载本地保存的权重
base_model.load_weights(local_weights_path)
# 冻结预训练模型的层
for layer in base_model.layers:
layer.trainable = False
# 添加新的全连接层
x = base_model.output
x = Flatten()(x)
x = Dense(256, activation='relu')(x)
predictions = Dense(10, activation='softmax')(x)
# 构建新的模型
model = Model(inputs=base_model.input, outputs=predictions)
# 编译模型
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# 打印模型结构
model.summary()
1.3 迁移学习在实际项目中的应用
迁移学习在实际项目中有着广泛的应用,特别是在数据量有限或计算资源有限的情况下。以下是一些迁移学习在实际项目中的应用示例:
图像分类
在图像分类任务中,迁移学习是一种极为有效的策略,能够显著提升模型性能。传统方法通常需要大量标注数据从头训练模型,而迁移学习允许我们利用在大型数据集(如ImageNet)上预训练的模型,这些模型已学习到丰富的图像特征。在图像分类中,通过复用预训练模型的底层特征提取部分(如卷积层),我们只需针对特定任务微调高层网络或添加分类器,便可快速构建高性能模型。
这种策略不仅减少了数据需求,还大幅缩短了训练时间,尤其适用于数据量有限或计算资源不足的场景。此外,预训练模型已捕捉到图像的通用特征,迁移学习能让模型更快适应新任务,提升分类准确率。因此,迁移学习已成为图像分类任务中提升模型性能的关键技术手段。
# 指定本地权重文件路径
local_weights_path = 'vgg16_weights_tf_dim_ordering_tf_kernels_notop.h5' # 替换为你的实际路径
# 加载预训练的VGG16模型,不包括顶部的全连接层
base_model = VGG16(weights=None, include_top=False, input_shape=(224, 224, 3))
# 加载本地保存的权重
base_model.load_weights(local_weights_path)
# 冻结预训练模型的层
for layer in base_model.layers:
layer.trainable = False
# 添加新的全连接层
x = base_model.output
x = Flatten()(x)
x = Dense(256, activation='relu')(x)
predictions = Dense(5, activation='softmax')(x) # 假设有5类花卉
# 构建新的模型
model = Model(inputs=base_model.input, outputs=predictions)
# 编译模型
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# 数据增强
train_datagen = ImageDataGenerator(rescale=1./255, shear_range=0.2, zoom_range=0.2, horizontal_flip=True)
test_datagen = ImageDataGenerator(rescale=1./255)
# 从文件夹中加载数据
train_generator = train_datagen.flow_from_directory('data/train', target_size=(224, 224), batch_size=32, class_mode='categorical')
validation_generator = test_datagen.flow_from_directory('data/validation', target_size=(224, 224), batch_size=32, class_mode='categorical')
# 训练模型
model.fit(train_generator, epochs=2, validation_data=validation_generator)
文本分类
在文本分类任务中,迁移学习通过复用预训练模型的知识,成为提升模型性能的利器。传统文本分类模型通常需要大量标注数据从头训练,而迁移学习允许我们借助在海量文本数据(如维基百科、新闻语料)上预训练的语言模型。这些预训练模型通过无监督学习捕捉了语言的深层语义和语法特征,形成了丰富的语言表示能力。在文本分类任务中,我们只需在预训练模型的基础上,针对特定分类任务微调模型参数或添加分类层,即可快速构建高效的分类器。
这种策略显著降低了对标注数据的依赖,减少了训练时间和计算成本,尤其适用于数据稀缺或领域特定的文本分类场景。此外,预训练模型已学习到通用的语言模式,迁移学习能够将这些知识迁移到新任务中,使模型更快收敛并提升分类准确率。因此,迁移学习在文本分类中展现出强大的性能提升潜力,成为自然语言处理领域的重要技术手段。
# 示例文本数据
texts = ["This is a sample text.", "Another example for demonstration."]
# 初始化Tokenizer
tokenizer = Tokenizer(num_words=10000)
tokenizer.fit_on_texts(texts)
# 本地GloVe文件路径
glove_file_path = 'glove.6B.50d.txt' # 替换为你的本地GloVe文件路径
# 创建一个字典来存储词向量
embeddings_index = {}
with open(glove_file_path, encoding='utf8') as f:
for line in f:
values = line.split()
word = values[0]
coefs = np.asarray(values[1:], dtype='float32')
embeddings_index[word] = coefs
# 初始化嵌入矩阵
embedding_dim = 50 # 注意:这里应该是50,因为GloVe 6B 50d的维度是50
embedding_matrix = np.zeros((len(tokenizer.word_index) + 1, embedding_dim))
for word, i in tokenizer.word_index.items():
embedding_vector = embeddings_index.get(word)
if embedding_vector is not None:
# 如果词在GloVe中存在,则使用GloVe的词向量
embedding_matrix[i] = embedding_vector
else:
# 如果词不在GloVe中,则随机初始化
embedding_matrix[i] = np.random.normal(scale=0.6, size=(embedding_dim,))
# 构建模型
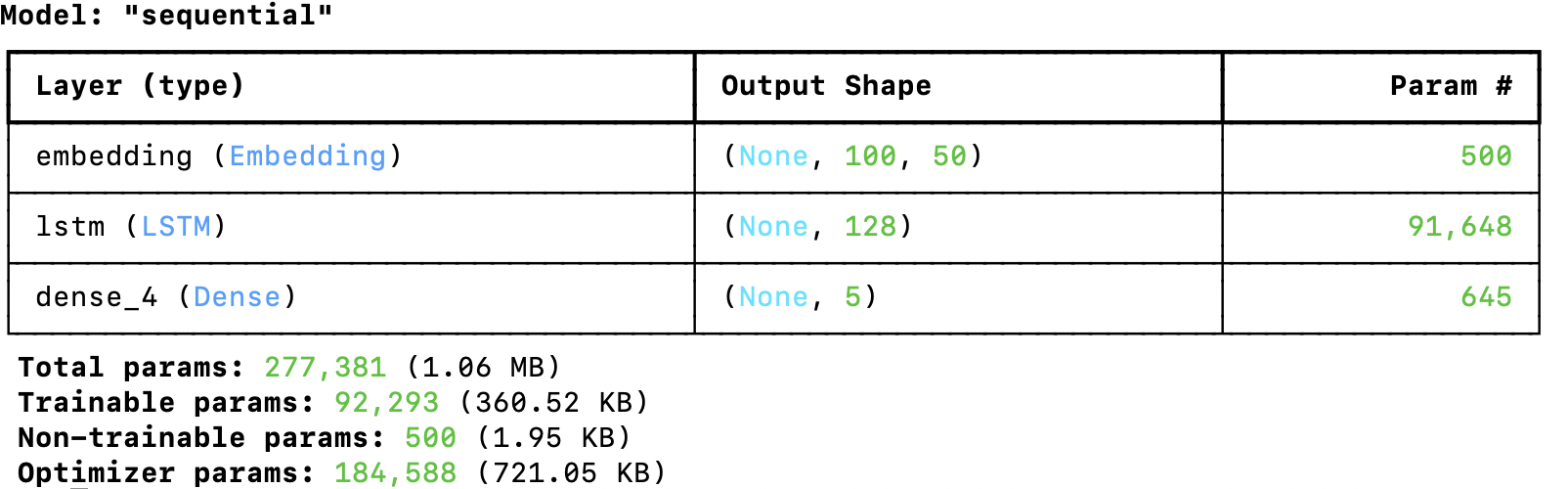
model = Sequential()
model.add(Embedding(input_dim=len(tokenizer.word_index) + 1, output_dim=50, weights=[embedding_matrix], input_length=100, trainable=False))
model.add(LSTM(128))
model.add(Dense(5, activation='softmax')) # 假设有5类文本
# 编译模型
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# 准备数据
sequences = tokenizer.texts_to_sequences(texts)
data = pad_sequences(sequences, maxlen=100)
# 假设labels是经过one-hot编码的标签
labels = np.array([[1, 0, 0, 0, 0], [0, 1, 0, 0, 0]]) # 示例标签
# 训练模型
model.fit(data, labels, epochs=10, batch_size=32)


















 968
968

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









