



第九章 双手与复杂对象操控
9.1 双手系统的运动学与动力学挑战
双手操控涉及两臂或两手协同作用于同一对象或相互耦合的多个接触点,其物理本质由多体刚性–接触约束的耦合动力学决定。与单臂操控相比,双手系统在自由度、接触分配、内力管理与重定位规划上面临显著挑战。本节从几何与动力学建模出发,系统推导双手操控的约束关系、力/力矩平衡式与自由度分解,归纳高维动作空间约简的理论方法,并给出双手协同与握持重定位的计算策略与优化框架。必要处给出严密的数学推导以便直接作为教材中算法与原理章节。
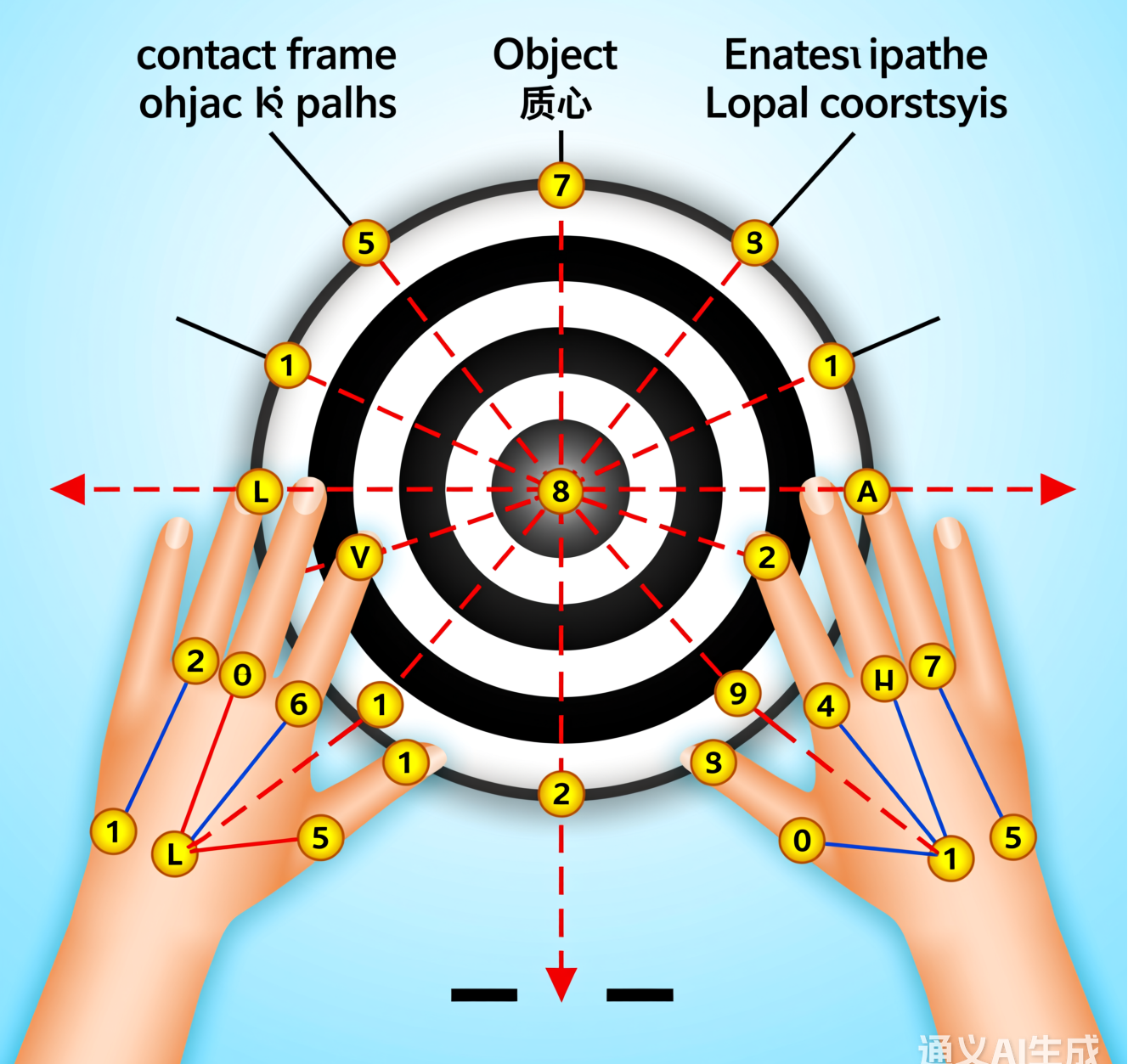
9.1.1 高维动作空间的约简技术
(一)问题表述与自由度统计

本质上,高维动作空间受接触约束、任务约束与机械结构冗余三类因素限制,约简技术旨在显式或隐式地投影到有效自由度子空间以便规划与控制。
(二)线性子空间约简:任务/骨架基与奇异值分解

(三)任务空间/操作子约简:任务优先与 Null-space 投影

(四)非线性流形学习与自编码表示

(五)基于优化的动作基结构化(稀疏基与字典学习)

9.1.2 双手协同策略与握持重定位方法
(一)接触力学与抓握映射的推导


(二)力分配的最優化形式(QP 推導)

(三)握持穩定性與抓握壓力分布:抓握力空間(Grasp Wrench Space)

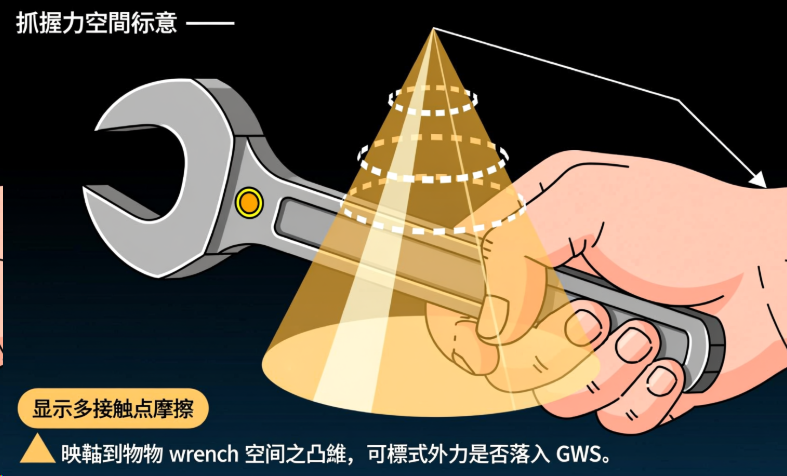
(四)重定位(Regrasp)與握持過渡的規劃框架
重定位指在保持物體受控的前提下改變接觸分配或手部姿態以實現新的抓握或操作。重定位通常分為兩類:保持 grasp(in-hand manipulation)與中途放置再抓取(regrasp via support)。重定位的可行性可借助抓握穩定性條件與接觸切換圖(grasp graph)分析。
將所有可能的穩定抓握組合作節點、可行的抓握轉換(例如單指脫離再接觸、滑動至新接觸點、依靠環境支撐的放置—再抓取)作邊,則重定位問題可形式化為圖搜索問題。邊的可行性由局部力學與碰撞檢查決定,代價函數可基於操控能耗、風險(例如失落概率)與時間。此框架給出可證明的完整性與可行解搜尋策略(在有限抓握集合下圖搜索是完整的),並可結合啟發式(例如抓握品質度量)加速搜索。

(五)協同控制架構:集中式與分散式實現
協同控制既可採集中式架構——一個中央規劃器求解整體 QP 分配力與運動命令,向各臂下發指令;亦可採分散式架構——各臂在本地感知與通信下通過協同協議(例如一致性演算法或拉格朗日乘子同步)達成全局平衡。分散式方法對通訊延遲與單點故障更具魯棒性;集中式方法能直接求解全局最優解。數學上,分散式解可通過建立拉格朗日對偶並使用分布式 ADMM(交替方向乘子法)求解,ADMM 的收斂性在凸問題下有理論保證,從而為分散式力分配提供可驗證的收斂框架。
本节小结

9.2 工具使用、握持变化与任务迁移
工具使用是人类操作能力的重要组成部分,其核心特征在于将外部工具纳入身体–物体–任务动力学体系,使其成为功能性延伸。机器人体系中的工具操作亦需通过对工具属性、抓取结构与操作接口进行抽象化表达,从而实现跨工具任务迁移。本节从工具抽象化与接口通用性入手,讨论抓取与重定位的可参数化机制,并推导在线选择与适配方法,为复杂环境下多任务通用操作提供理论基础。
9.2.1 工具抽象化、接口与通用化策略
(一)工具的功能抽象与状态表征

(二)工具–手–任务的接口结构

(三)工具策略通用化与类别共享

(四)动力学一致性与自适应

9.2.2 抓取参数化、重定位动作库与在线选择
(一)抓取动作的参数化

(二)重定位动作库构建

(三)在线选择与可行性评估

(四)迁移时的工具–动作映射

本节小结
工具使用的核心在于通过功能端点抽象与映射,使工具与手部—对象动力学系统统一建模。通过工具类别模板,可将操作从实例化提升至类别层级,促进跨工具任务迁移。抓取参数化为 {pG,RG,u}\{\mathbf{p}_G,\mathbf{R}_G,\mathbf{u}\}{pG,RG,u} 的框架,可将抓取与力闭合条件统一纳入约束优化中描述。重定位动作可组织为离散动作库,通过可行性评价与代价最小化实现在线选择。工具—动作映射基于几何配准与类别功能保持,可实现快速迁移与复用。上述理论方法为机器人在复杂环境中进行工具操作、姿态重定位与任务迁移提供了统一的数学与算法基础。
9.3 实验基准、评测套件与失败案例分析
本节系统给出灵巧双手操控实验基准的设计原则、分层任务套件、量化评价指标与统计检验流程,随后对常见失败模式作系统化分类与可操作的调试清单。所有准则力求以可复现、可量化和可比较为目标,适合作为教材中实验设计与工程验证章节的正文内容。
9.3.1 灵巧操控的任务分层基准设计
一、基准设计的目标与约束条件
基准(benchmark)旨在为算法与系统提供客观、公正、可重复的评测环境。对于双手与复杂对象操控,基准设计须同时满足以下几项原则:
-
层次性(hierarchy):任务应覆盖从低级感知—控制到高级规划—重定位的不同抽象层次,以便分离性能瓶颈来源。
-
可测量性(measurability):每个任务必须定义明确的成功判据与量化指标。
-
可复现性(reproducibility):明确硬件、软件版本、随机种子与环境初始条件,保证不同实验组可复现结果。
-
渐进难度(curriculum):任务集合应按难度分层,便于算法逐步验证与对比。
-
鲁棒性测试(stress testing):包含扰动、遮挡、参数偏差等不确定性情形以考察系统鲁棒性。
在此基础上构建层次化的任务套件并给出统一的评测流程。
二、任务分层与典型基准项
将任务划分为四个层级,每层级定义若干代表性任务与测量项。
层级 L0:感知与接触本体测试
目标:验证触觉/视觉/力传感器的基本可靠性与同步。
示例任务:静态触觉阵列压力重构、触觉-视觉对齐测试。
指标:传感器漂移(单位时间偏移),时钟同步误差(ms),静态重构 RMSE。
层级 L1:接触建立与基础力控
目标:在已知目标位置实现稳定接触并维持指定力。
示例任务:法向压入到指定力值、恒力滑动维持摩擦边界。
指标:力稳态误差($\Delta f$)、稳态方差、达稳时间 $t_{\mathrm{settle}}$、最大超冲(overshoot)。
层级 L2:双手协同与抓握稳定性
目标:两手协同抓取并维持物体姿态,评估内力分配与抓握稳定性。
示例任务:双手抓持长杆并在受扰下维持位姿、对象旋转定位(in-hand manipulation)。
指标:抓握成功率、GWS margin(见下)、内力违例次数、位姿误差($SE(3)$ 距离)、能耗。
层级 L3:任务迁移与工具使用
目标:在工具差异或外部扰动下完成复杂操作。
示例任务:用不同长度锤子敲击、用钳子协同转动阀门、放置—再抓取重定位。
指标:任务成功率、迁移效率(需要重新标定或自适应次数)、时间到完成(makespan)、安全事件率。
【建议插图:任务层级示意图(L0–L3),每层举例并标注典型指标】。
三、可量化指标、数学定义与计算方法
为保证评测的一致性,指标应有严格的数学定义与计算流程。以下列出常用指标并给出计算式或优化定义。

四、评测协议与统计检验流程
为保证结论的显著性与可重复性,评测应遵循严格协议:

9.3.2 常见失败模式与调试清单
对失败做系统化分类与诊断流程有助于快速定位问题并减少试验迭代成本。下列按故障根源分门别类,并给出可执行的检测步骤与数学检验方法。
一、感知与估计相关失败
典型症状:接触时刻检测失真、位姿估计跳变、触觉—视觉对齐失败。
可能原因:同步误差、时延、标定漂移、数据丢包、滤波器参数不当。
诊断步骤:
-
时间同步检查:比较传感器时间戳差分分布,计算均值与方差;若抖动 $\sigma_t$ 超过控制周期的一定比例(例如 $T_s/10$),需修正采样同步或采用插值对齐。
-
残差分析:在感知估计器(例如卡尔曼滤波)中检查创新序列 $y_k-H\hat x_{k|k-1}$ 的自相关与方差是否符合假定噪声模型;若不满足,需重估噪声协方差 $Q,R$ 或采用滤波器自适应。
-
标定漂移检验:在静态已知场景下重复测量并计算均值漂移速率,若漂移显著应加入温湿度补偿或定期在线重标定。
修复建议:采用硬件触发或高精度同步时钟,降低滤波器带宽以减小相位误差;在滤波器中引入延迟补偿与时变噪声估计。
二、建模与参数错配导致的失败
典型症状:力控制不稳定、阻抗振荡、任务迁移失效。
可能原因:模型不精确(惯量、摩擦、工具质量估计偏差)、阻抗参数不匹配、DOB 带宽设置不当。
诊断步骤:
-
步响应辨识:在安全条件下施加小幅已知激励(位移/力阶跃),记录输出并拟合简单二阶模型,比较估计参数与模型值差异。
-
频域分析:对闭环系统进行频响估计(Bode),检查相位裕量与增益裕量是否满足设计要求;若裕量不足,需增加阻尼或降低控制带宽。
-
扰动观测器验证:对 DOB 的估计 $\hat f$ 施以小幅已知外力,检验估计的幅值与滞后,若延迟过大则缩小 $Q(s)$ 带宽或滤波器阶数。
修复建议:采用在线参数辨识(RLS 或最小二乘)并进行增益调度;在阻抗设计中采用自然频率—阻尼比参数化并以 Bode 边界验证稳定性。
三、接触力学与摩擦引起的失败
典型症状:滑脱、抓握失稳、微动探测失败。
可能原因:摩擦系数估计偏小、法向力不足、摩擦锥线性化不精确、接触点移动未跟踪。
诊断步骤:
-
摩擦测试:在被测表面做标准摩擦系数实验(滑动/静摩擦),比较估计值与设计值差异;若波动大,采用稳健控制或保守设计(增大内力)。
-
抓握裕度计算:在实际测量数据下解 (9.13) 或 (9.14) 求 GWS margin,若 margin 近零说明易失稳。
-
接触点跟踪:比对阵列式触觉或视觉估计的接触点随时间的漂移,若接触点移动超出预期需改进滑移检测与重新规划。
修复建议:增加保守内力、改进摩擦锥建模(用多面体外接但选取更多面以提高精度)、在微动策略中引入阻抗过渡以降低滑脱风险。
四、控制实现与数值问题
典型症状:QP 解发散、求解器时间超限、数值不稳定。
可能原因:约束不满足(不可行 QP)、矩阵条件数高、采样周期过短。
诊断步骤:
-
可行性检查:在求解 QP 前做可行性检测(线性可行性或添加松弛变量并查看松弛大小),若松弛量大表示物理不可行。
-
条件数分析:计算关键矩阵(例如 $J^\top J$、QP Hessian)的条件数 $\kappa$,若 $\kappa$ 很大建议做正则化(Tikhonov)或变量缩放。
-
求解时间剖析:记录解时分布并检查尾部,若偶发延迟导致控制失稳,应采用热备份控制律(保守 fallback)或降低 QP 复杂度(层次化约束分解)。
修复建议:在求解器中使用稀疏结构与预因子化、添加小正则项保证正定性、限制迭代次数并在超时情况下退回保守控制。
五、系统与硬件故障
典型症状:驱动器过热、力传感器漂移、通信丢包。
诊断步骤:
-
统计日志分析:汇总硬件告警、温度曲线、通信丢包率并与实验失败时刻做关联分析。
-
压力/温度对性能的回归:做回归分析检验性能指标与温度/电压等变量的相关性。
修复建议:硬件冗余、实时监控报警与安全断电方案,实验前做热身与冷却周期。
六、失败案例分析流程(Root Cause Analysis)
对每次失败应采用系统化 RCA 流程:
-
重现(Reproduce):在受控条件下重现失败并记录原始数据。
-
隔离(Isolate):逐项禁用子模块(传感、估计、控制)以定位故障域。
-
量化(Quantify):用上述数学指标(GWS margin、NIS、条件数等)量化故障严重度与临界点。
-
假设检验(Hypothesis Test):构造可检验的假设(例如“摩擦系数<μ0 导致滑脱”),并通过样本或设计试验验证。
-
修复并回归(Fix & Re-test):实施修复并重复试验以确认改进效果,记录前后指标并做统计显著性检验。
该流程结合实验日志与版本控制,形成可审计的失败分析闭环。
本章小结
本节提出了针对双手与复杂对象操控的实验基准设计方法、层次化任务套件与严格的评测协议,并给出了详细的可量化指标与统计检验方法。随后对常见失败模式做了系统分类,提供了诊断步骤、数学检验与可执行修复建议,并提出了标准的根因分析流程。该内容不仅为科研比较提供规范化工具,也为工程团队在系统调试、迭代改进中提供明确的操作指引与量化判断依据。
第十章 高吞吐仿真与并行训练架构
10.1 并行化仿真设计原则
为支持大规模策略训练与数据采集,仿真系统必须在吞吐量、可重复性与资源效率之间进行工程化折衷。并行化仿真不仅关乎把更多环境实例放入并行执行,更涉及场景复用与随机化设计以提升样本有效性、并发管理与队列调度以保证系统稳定性、以及性能监控与弹性调度以实现高资源利用率和可观测的训练管道。本节从原理出发,逐步推导并行化仿真的关键构件与度量、随机化与复用策略、并发一致性与伸缩性保障,以及监控与资源调度的数学/算法基础,形成可直接用于教材的技术章节。
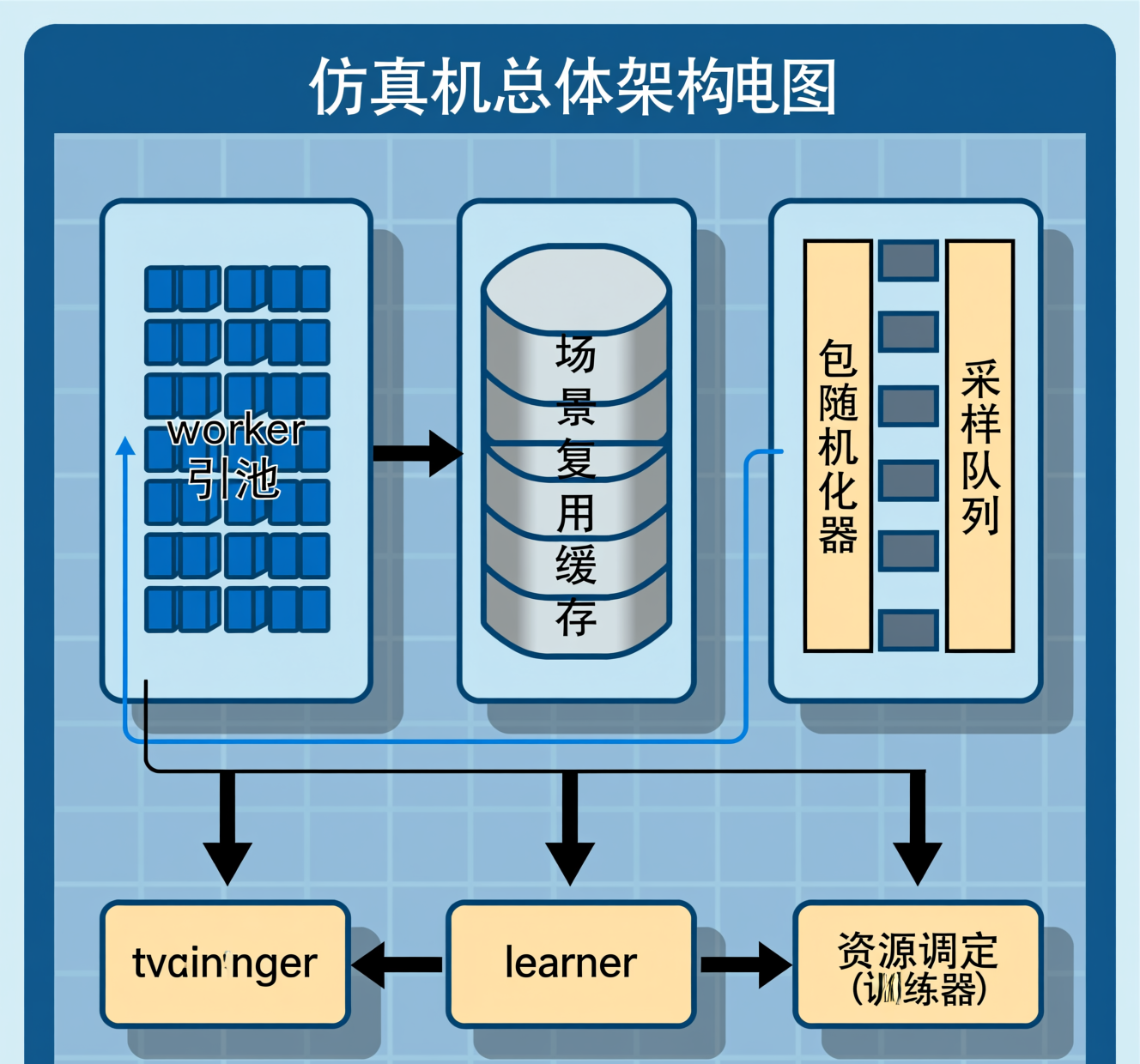
10.1 并行仿真的性能度量与设计目标
并行仿真系统的核心目标是最大化有效样本生成速率(有效帧/episode/second),同时满足可重复性与延迟约束。定义基本量:


10.1.1 场景复用、随机化与仿真并发管理
并行仿真的样本质量不仅依赖样本速率,还依赖样本的多样性与有效信息量。场景复用(scene reuse)、域随机化(domain randomization)与并发一致性控制共同构成样本生成与实验可比性的核心。
(一)场景复用与状态快照技术

(二)随机化策略与覆盖保证

(三)并发管理:无锁/消息驱动与向量化环境

10.1.2 仿真性能监控与资源调度策略

(二)资源调度建模:队列论与负载均衡

(三)调度算法与近似求解

(四)弹性伸缩、预占与抢占策略

(五)监控、可观测性与故障自愈

小结
高吞吐并行仿真是实现大规模强化学习的基础能力。设计原则包括:最大化可并行部分以提高加速比、通过场景复用与 snapshot 降低初始化开销、以域随机化与自适应采样保证样本覆盖性并控制方差、并通过向量化或 actor-based 并发模型实现高可用的采样管线。在资源层面,需用排队论与装箱/调度优化方法指导节点分配、用弹性伸缩与监控闭环保障 SLA、并设计抢占与检查点机制以实现容错。上述理论与算法构成在工程上可量化、可优化的并行仿真与训练平台的基础,可直接作为教材中关于大规模训练基础设施的章节内容。
10.2 物理一致性与参数标定技术
高吞吐并行仿真系统在展开大规模策略训练时,必须保证仿真动力学与真实系统之间的物理一致性。物理一致性不仅要求动力学方程结构保持一致,同时要求接触模型、材料参数、摩擦系数、惯性参数、阻尼、关节摩擦以及传感噪声等均得到严格标定。若仿真环境偏离真实动力学结构,则训练策略将表现出明显的 sim-to-real 性能衰减。因此,必须建立系统辨识方法、参数估计流程以及高精度接触模型与数值稳定处理机制,使得仿真与真实系统具有可验证的行为一致性。
10.2.1 系统辨识方法与参数估计流程
一、动力学参数辨识基本模型

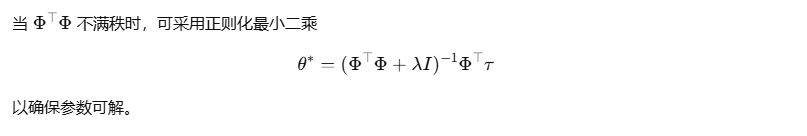
二、辨识可观测性条件

三、噪声环境下的参数估计

四、多阶段参数估计流程
参数估计流程可描述如下:
-
构建动力学模型与回归矩阵
-
收集激励轨迹数据
-
执行回归估计获得初值
-
噪声建模与加权估计
-
进入在线滤波阶段动态调整参数
-
迭代评估并更新仿真模型
-
通过交互验证确认一致性

10.2.2 高精度接触模型与数值稳定性处理
机器人操控训练中,接触建模是影响物理一致性的关键要素。接触模型必须准确描述法向约束、摩擦力、能量耗散与接触稳定区域。常用接触模型包括软接触模型、基于补充条件的刚体模型以及混合摩擦模型。
一、法向力模型与补充条件

二、摩擦锥与切向力建模

三、软接触模型与能量退火

四、数值稳定性与时间积分

五、多接触求解与线性互补问题

六、验证与收敛准则
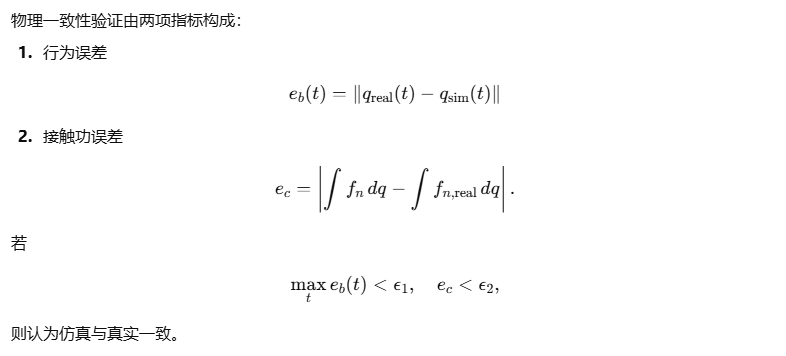
10.3 仿真数据治理与版本管理
并行仿真平台在规模化训练与验证中生成大量场景、轨迹与度量日志。为保证实验可重复、改动可追溯、sim-to-real 比较具统计意义,必须对仿真场景库、基线与变体进行规范化治理,并建立严格的“仿真快照—现实对照”实验流程。以下系统阐述场景库与变体管理的范式、版本与影响评估机制,以及仿真到现实的数据快照设计、配对对照实验与统计检验方法,形成可直接用于教材的工程与理论规范。
10.3.1 仿真场景库、基线与变体管理
(一)场景元数据模型与唯一标识
每一仿真场景应具备机器可读的规范化元数据(schema),以支持检索、重现与差异比较。建议字段包括但不限于:
-
scenario_id(全局唯一标识符,采用 UUID 或内容寻址哈希); -
commit_hash(仿真代码/物理模型对应的版本控制哈希); -
config_hash(配置参数 JSON 的内容哈希); -
seed_set(用于随机化的种子集合或生成规则); -
param_set(可随机化参数列表与其采样分布说明,如摩擦μ∼Uniform[a,b]); -
assets(几何模型、纹理与质量等资源引用); -
creator,timestamp,description,tags(创建者、时间、摘要与语义标签); -
baseline_ref(若为变体,指向其基线场景 id); -
validation_results(自动化 smoke test 与基线比对摘要)。
采用内容寻址(例如 SHA-256)为主要资源与配置文件建立不可变标识,保证任意场景在理论上可位级别重建。版本管理中应强制将 commit_hash 与 config_hash 一并记录,以确认仿真栈与参数栈的耦合状态。
(二)基线(baseline)定义与语义版本化
基线场景定义为用于长期比较、回归测试与对照实验的参考场景。基线必须满足稳定性条件(在相同配置下复现误差在给定容忍度内)。对基线采用语义版本控制(semantic versioning)规则:
-
主版本
MAJOR:当仿真引擎、物理模型、接触求解器或数学公式发生不可向后兼容变更时递增; -
次版本
MINOR:当加入新的参数化选项或额外变体但仍兼容旧基线时递增; -
修订
PATCH:仅修复实现细节或修补小错误、不影响理论模型时递增。
版本号与 commit_hash 同时记录;任何依赖实验需以 MAJOR.MINOR.PATCH+commit 的方式完全标识它的仿真基线。基线更新需伴随回归测试套件(见下)并发布变更说明(changelog),记录对现有结果可能产生的影响。
(三)变体(variant)生成与控制流

(四)回归测试与影响分析
每当基线或仿真代码发生变更,需在自动化 CI(continuous integration)中运行回归套件。回归测试包含三类测试:
-
功能性 smoke test:是否能启动场景、是否有异常退出;
-
行为回归 test:在固定随机种子及同一策略下,关键统计量(平均回报、接触次数、最大力)与历史基线的差异 Δm\Delta mΔm 是否在容忍区间内;
-
统计显著性 test:对比若干独立试验样本,使用配对检验(paired t-test 或非参数的 Wilcoxon signed-rank)验证差异是否显著;若 p-value < α 则视为回归失败并阻塞合并。
影响分析需进一步计算效应量(Cohen’s d)与置信区间,帮助判断变更是否在工程上可接受。若回归失败,需自动触发回滚或人审。
(五)差异化管理与变更影响传播(change impact)

(六)可追溯的数据治理机制
数据治理需要三项机制:可变更历史、数据血缘(lineage)与访问控制。建议实践:
-
所有场景、资源与快照均存储在内容寻址存储(CAS)中,资源与元数据通过不可变哈希连接;
-
记录血缘:一个实验条目应包含对场景 id、模型版本、策略版本、训练参数与 seed 的全部引用;
-
采用权限与审计日志:对数据的读取、写入、导出行为留痕,以满足法规或研究复现需求。
这样在出现争议或失败时可追溯到确切的代码/参数/数据组合。
10.3.2 仿真到现实的数据快照与对照实验设计
(一)仿真快照(snapshot)定义与采集协议

(二)对照实验的配对设计原则

(三)相似度度量与域差距量化

(四)因果诊断与干预式对照(counterfactual / ablation)

(五)迁移修正策略与增量验证

(六)报告与可复现的发布流程
对仿真—现实对照实验应形成结构化的报告,包含:
-
实验总体设定(场景 id、基线版本、变体描述);
-
采样协议与配对/随机化细节;
-
统计结果(均值、方差、置信区间、p-value、效果量);
-
可追溯数据包(快照 id、轨迹样本与脚本);
-
结论与建议性修正清单。
发布流程应确保所有引用资源可恢复(通过哈希),并在变更后保存旧版本以便回滚与事后审计。
本节小结
仿真数据治理与版本管理建立了从场景定义、变体管理到仿真—现实对照的完整闭环。通过规范化元数据、语义版本与回归测试,保证变更可追溯、影响可量化;通过快照化采样与配对对照设计,赋予 sim-to-real 对比以统计显著性与因果诊断能力;通过差距量化(MMD、Wasserstein、轨迹对齐)与干预式实验,支持定位关键失配因素并迭代修正。该体系是大规模并行仿真平台实现可信仿真、可复现研究与安全部署的核心工程方法论。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









