 生成式轨迹模型与扩散规划
生成式轨迹模型与扩散规划




系列文章目录
文章目录
目录
4.1.3 精确密度模型:条件流模型 (Conditional Flow Models)
4.1.4 迭代精炼模型:扩散模型 (Diffusion Models)
多目标优化(Multi-Objective Optimization)
实验卡是科学实验标准化的实现工具,确保每次实验可复现。内容包括:
4. 生成式轨迹模型概论
生成式轨迹模型,旨在从给定的、可能不完整或高维的输入信息中,学习并采样出符合任务要求和动力学约束的动作序列分布。在机器人学中,这一问题具有根本性的挑战:对于一个给定的任务(例如,从桌上“拿起杯子”),其解空间本质上是**多模态(Multi-modal)**的。机器人可以从左侧抓、从右侧抓、抓手柄或抓杯身,这些都是同样有效的“专家”轨迹。

4.1 概念框架与模型家族

4.1.1 隐式密度模型:条件生成对抗网络 (cGAN)

4.1.2 潜在变量模型:条件变分自编码器 (CVAE)


4.1.3 精确密度模型:条件流模型 (Conditional Flow Models)

4.1.4 迭代精炼模型:扩散模型 (Diffusion Models)


4.2 条件采样与约束注入技术
在机器人轨迹生成及规划中,条件采样与约束注入技术扮演着至关重要的角色。条件采样允许模型在给定的条件下生成符合要求的轨迹,而约束注入则确保这些轨迹符合实际操作中的物理和安全约束。通过这些技术,可以确保生成的轨迹不仅满足任务要求,还能够有效规避碰撞和物理限制。以下将详细推导并分析几种常用的条件采样与约束注入方法,包括状态约束、碰撞约束的嵌入方法、实时约束适配与修正策略、以及采样效率与实时性优化手段。
4.2.1 状态约束、碰撞约束的嵌入方法
在生成轨迹的过程中,状态约束和碰撞约束是最基础且最重要的约束类型。状态约束通常限制机器人在给定任务中必须遵守的物理参数(如位置、速度、加速度等),而碰撞约束则确保机器人在运动过程中避免与环境中的障碍物发生碰撞。我们通过严格的数学推导,探讨如何将这些约束有效地嵌入轨迹生成模型。
1. 状态约束的嵌入方法
状态约束涉及到对机器人的各类状态变量进行约束,比如位置约束、速度约束、加速度约束等。这些约束通常以不等式的形式出现,如:


2. 碰撞约束的嵌入方法

4.2.2 实时约束适配与修正策略
在实际应用中,环境是动态变化的,障碍物可能移动,任务要求可能随时变化。因此,在轨迹生成过程中,需要实时适配新的约束条件,并对现有轨迹进行修正。为了保证机器人在复杂环境中的实时性和鲁棒性,实时约束适配与修正策略显得尤为重要。
1. 约束动态更新
在轨迹生成的过程中,新的约束条件可能随时加入。比如,障碍物的移动可能导致新的碰撞约束,而外部任务需求的变化可能引入新的状态约束。因此,需要设计能够动态更新约束的机制。可以通过以下方法进行约束的动态更新:
-
增量式约束优化:每当约束条件发生变化时,可以对目标函数进行增量式更新,而不是从头开始计算新的轨迹。例如,在每次更新约束时,仅优化受影响的部分轨迹,避免了整个轨迹的重新生成,从而提高了计算效率。
-
在线规划与重规划:当新的约束加入或环境发生变化时,可以触发重规划机制。常见的重规划方法包括基于采样的快速扩展随机树(RRT)和RRT*算法,在新的约束条件下重新规划轨迹。
2. 局部修正与反馈控制
当机器人在执行过程中遇到实时的偏差或扰动时,需要通过局部修正和反馈控制来修正轨迹。通过实时的感知数据,机器人能够估计自己的当前状态,并在此基础上修正轨迹。具体地,可以使用以下技术进行局部修正:
-
状态估计与校正:使用卡尔曼滤波或粒子滤波等技术对机器人状态进行实时估计。在每个时间步,基于当前估计的状态,对生成的轨迹进行局部修正,确保机器人始终保持在可行轨迹上。
-
增量式控制与规划:通过增量式的轨迹修正策略,例如基于PID控制器的路径跟踪,实时调整机器人的轨迹,确保其满足实时的约束条件。
4.2.3 采样效率与实时性优化手段
在轨迹生成中,尤其是在大规模问题和动态环境下,采样效率和实时性是非常关键的。为了提高采样效率,并满足实时性要求,需要设计高效的采样策略和优化手段。
1. 重要性采样与策略优化

2. 并行化与GPU加速
为了在复杂环境中实现高效的轨迹生成,可以采用并行化和GPU加速方法。通过将采样任务分配到多个处理器或计算节点上,可以显著提高采样效率。在实际应用中,可以利用GPU加速矩阵运算、梯度计算等任务,从而提高计算速度。
3. 增量式优化与局部调整
增量式优化方法可以提高生成轨迹的实时性。在每次更新时,只对当前轨迹的部分进行调整,而不是重新计算整个轨迹。增量式优化方法的实现可以通过局部调整策略来快速适应环境变化,确保轨迹生成的实时性和准确性。
4.3 生成模型与控制器的融合模式
在实际机器人轨迹生成中,单一的生成模型往往无法直接满足复杂动态环境下的实时性与准确性要求。为了提高轨迹生成的稳定性与效率,生成模型与控制器的协同工作成为一个关键的解决方案。生成模型主要负责提供候选轨迹,而控制器则负责基于环境反馈调整轨迹,确保机器人能够高效、安全地执行任务。本文将详细探讨生成模型与控制器融合的不同模式,重点关注生成模型作为建议器的工程模式、轨迹置信度评估与安全筛选器、以及异常恢复与在线微调机制。
4.3.1 生成模块作为建议器的工程模式
在很多机器人应用中,生成模型被设计为轨迹生成过程中的建议器(Advisor)。此时,生成模型的任务是生成多个候选轨迹,而控制器则负责基于环境感知与约束条件来选择、执行并调整最终轨迹。生成模型和控制器之间的协同工作通常按照以下步骤进行。
1. 生成轨迹的候选空间
生成模型的目标是为控制器提供一个多样化的候选轨迹集。通过从环境与任务特征中提取信息,生成模型能够生成符合要求的轨迹。生成的轨迹集通常通过条件采样或优化方法得到。这些轨迹在多样性上进行设计,以满足不同任务需求和环境条件。生成模型如扩散模型、变分模型或流模型等都可以用于此类任务。
在机器人应用中,生成模块不要求生成的轨迹完全满足可执行性,而是侧重于提供一组候选解。在动态环境下,机器人可以根据实际情况从这些候选轨迹中选择最优路径。因此,生成模块的首要任务是保证轨迹的多样性和候选集的充足性,而不是严格要求每条轨迹都能直接执行。
2. 建议与执行的反馈回路
生成模型提供候选轨迹后,控制器会根据实时状态和环境感知对每条轨迹的执行可行性进行评估。控制器的主要职责是根据传感器数据对生成轨迹进行调整,确保轨迹能够在不断变化的环境中高效、安全地执行任务。
在实际应用中,控制器会对生成的轨迹进行以下几种处理:
-
平滑与修正:若生成的轨迹存在急转弯、速度突变等不符合物理限制的情况,控制器将采用平滑技术或在线优化算法进行修正。例如,基于控制理论的平滑方法可以调整轨迹的速度变化,使其符合系统的动力学约束。
-
动态约束处理:控制器会根据实时的环境感知,更新状态约束(如位置、速度限制)和碰撞约束,确保轨迹的安全性。如果生成的轨迹会导致碰撞或不符合安全标准,控制器会立即修正或选择其他可行轨迹。
-
实时适应:当环境变化导致生成的轨迹不可行时,控制器将根据新获得的感知数据选择新的轨迹或重新生成轨迹,确保机器人能够顺利完成任务。
这一过程的核心是生成模块专注于轨迹候选的生成,而控制器则在执行层面进行实时反馈和调整。两者的协同作用使得系统既能提供多样化的轨迹方案,又能在执行时保证适应性和安全性。
4.3.2 轨迹置信度评估与安全筛选器
生成模型通常会输出多个候选轨迹,这些轨迹可能在执行时面临不同的风险与挑战。因此,对生成的轨迹进行置信度评估和安全筛选是确保轨迹可执行性与安全性的关键步骤。置信度评估与安全筛选器的任务是对轨迹进行评分和筛选,确保所选轨迹不仅符合执行条件,也能够满足安全性要求。
1. 置信度评估的理论框架
轨迹的置信度评估旨在量化每条轨迹的执行风险,并对其进行评分。常见的评估方法包括基于模型的不确定性度量和基于执行条件的置信度评分。


2. 安全筛选器的设计
在生成多个候选轨迹后,安全筛选器的任务是根据置信度评估筛选出最安全的轨迹。在实际应用中,安全筛选器通常会执行以下步骤:
-
碰撞检测:对每条轨迹进行碰撞检测,剔除与环境中的障碍物发生碰撞的轨迹。
-
稳定性检查:通过动力学模型评估轨迹的稳定性,剔除可能导致机器人失稳的轨迹。
-
可执行性评估:根据任务要求(如时间限制、能耗等)评估轨迹的可执行性,剔除不符合要求的轨迹。
安全筛选器的核心目标是快速且高效地评估所有候选轨迹的安全性,确保所选轨迹既能满足任务需求,又能保证安全性和稳定性。
4.3.3 异常恢复与在线微调机制
在动态环境中,机器人在执行任务时难免会遭遇各种异常情况,如传感器故障、环境变化或不可预见的障碍物。为了确保机器人在这些情况下能够继续有效执行任务,异常恢复和在线微调机制显得尤为重要。异常恢复机制旨在实时修正轨迹,保证机器人能在出现异常时快速恢复任务执行。
1. 异常恢复的理论框架
异常恢复机制的目标是通过实时监控与检测,快速识别异常情况并调整轨迹。常见的异常包括传感器故障、机器人与障碍物发生碰撞或环境变化引发的误差等。为了应对这些异常,恢复机制通常采用以下策略:
-
实时监控与检测:通过传感器数据和环境变化实时监控机器人的状态,并检测潜在的异常。一旦发现异常,立即采取措施进行恢复。
-
局部修正:采用局部优化算法对当前轨迹进行修正。例如,基于模型预测控制(MPC)的方法可以在异常发生时,通过计算新的控制输入来修正轨迹。
2. 在线微调机制
在线微调机制的目的是在执行过程中根据实时反馈数据对生成轨迹进行微调。具体步骤包括:
-
实时感知数据更新:通过传感器实时更新环境数据,判断是否存在新的障碍物或环境变化。
-
轨迹再规划:在感知数据更新后,使用局部轨迹优化方法对当前轨迹进行微调。例如,可以使用实时优化算法对轨迹进行局部修正,确保机器人始终沿着优化后的轨迹执行。
-
执行反馈:通过反馈控制机制,调整机器人的运动,确保其始终沿着优化后的轨迹执行。
在线微调机制确保了机器人能够适应动态变化的环境,并在面临突发情况时迅速恢复任务执行。
5 扩散与概率运动规划实战配方
在现代机器人控制与路径规划任务中,扩散模型与概率运动规划方法已经展现出了强大的能力,尤其是在复杂且动态的环境中。通过合理的模型结构设计、损失函数的构建以及训练策略的选择,可以显著提升机器人在实际环境中执行任务的性能与鲁棒性。本章将深入讨论如何结合扩散模型与概率运动规划方法,尤其是如何设计合适的损失函数、正则化项、训练策略以及多目标优化与对抗性训练方法,以提升模型的效果和可靠性。
5.1 模型结构细节与损失设计
在扩散模型与概率运动规划中,模型结构的设计与损失函数的优化直接影响轨迹生成的质量和执行效果。生成轨迹的优化过程通常需要在多种约束条件下进行,同时确保轨迹具有平滑性、物理可行性与安全性。设计合理的损失函数能够帮助模型在训练过程中有效地学习如何生成高质量的轨迹。
5.1.1 条件损失、重建损失与正则化项
条件损失(Conditional Loss)

重建损失(Reconstruction Loss)

正则化项(Regularization Term)

5.1.2 多目标与对抗性数据的训练策略
多目标优化(Multi-Objective Optimization)
在实际的轨迹规划任务中,机器人往往需要在多个目标之间进行权衡,例如最短路径、最低能量消耗和最快时间等。多目标优化的目标是同时考虑多个目标函数,使得生成的轨迹能够在多个方面达到最优。为此,损失函数通常被设计为多个目标函数的加权和。例如,对于路径长度、能量消耗和时间最短的优化问题,总损失函数可以写作:
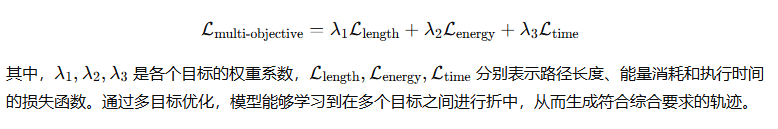
对抗性训练(Adversarial Training)
对抗性训练是一种通过引入扰动数据来提升模型鲁棒性的方法。在轨迹生成任务中,模型可能会受到各种扰动的影响,例如传感器误差、环境变化或未建模的动态因素。对抗性训练的基本思想是训练一个生成器(如扩散模型)和一个判别器,通过博弈式优化使得生成器生成的轨迹更加鲁棒。
在轨迹生成的对抗性训练中,生成器的目标是生成逼真的轨迹,而判别器的目标是区分真实轨迹与生成轨迹。通过对抗性训练,生成器能够在面对各种扰动时生成更鲁棒的轨迹。对抗性损失可以定义为生成器与判别器之间的博弈损失:

5.2 训练数据管线与数据增强技巧
在扩散模型与概率运动规划的训练中,数据管线的构建和数据增强方法的设计对于模型的性能和泛化能力至关重要。训练数据不仅需要覆盖任务空间中的典型轨迹,还需充分考虑边缘场景和稀有情况,以保证模型在动态复杂环境中具有鲁棒性。本节将深入推导训练数据构建与增强方法的原理,分析示范数据的合成、质量控制机制,以及稀有场景的采样增强与权重重校正的理论基础和实现方法。
5.2.1 示范数据的合成方法与质量控制
示范数据是训练生成模型的核心,它为模型提供了目标轨迹的参考。示范数据的构建通常依赖于以下两种来源:一是通过机器人控制器生成的高质量轨迹,二是通过仿真环境或专家演示获得的轨迹。为了保证训练数据的有效性,需要对示范数据进行严格的质量控制和合理的合成。
示范数据的合成方法

在实际构建过程中,常用方法包括:
-
控制器生成:使用已知控制器(如 MPC、RRT* 或优化控制器)在不同任务和环境条件下生成轨迹。此方法保证轨迹满足动力学约束、碰撞约束以及任务约束。
-
仿真采样:通过物理仿真环境生成轨迹,可以在多种初始条件和扰动下采集轨迹数据,确保数据分布覆盖真实环境的多样性。
-
专家演示:通过人工操作或远程控制机器人生成示范轨迹,能够在复杂环境下捕捉非线性决策策略。
质量控制机制
示范数据的质量直接影响模型训练效果。质量控制的核心目标是保证轨迹的可执行性、稳定性以及对任务的适应性。具体措施包括:

通过以上质量控制机制,示范数据不仅满足物理约束和任务要求,还保证了数据的多样性,为生成模型的训练提供了稳定可靠的基础。
5.2.2 稀有场景的采样增强与权重重校正
在实际环境中,一些极端或稀有场景的出现频率低,但其对机器人安全和任务完成具有关键影响。因此,需要设计数据增强方法以提高模型在稀有场景下的鲁棒性,并通过权重重校正确保训练过程的有效性。
稀有场景采样增强

通过稀有场景采样增强和权重重校正,可以系统性地改善模型在极端或边缘条件下的表现,同时保持对常规场景的高效泛化能力。这一策略在机器人运动规划中,尤其在动态复杂环境和高风险任务下具有重要作用。
5.3 评测指标与破坏性测试模板
在扩散模型与概率运动规划中,仅仅依靠训练损失的下降和直观轨迹效果并不能全面衡量模型的能力。必须建立科学的评测指标和破坏性测试模板,对模型在复杂、动态及极端环境下的性能进行严格量化。评测体系应包括多样性度量、鲁棒性曲线、失败分类、可重复性实验卡与对比基线设计,以确保评估结果既精确又可复现。
5.3.1 多样性度量、鲁棒性曲线与失败分类
轨迹多样性度量
轨迹多样性不仅衡量模型生成多个候选轨迹的变化范围,也反映了模型在面对不确定环境时的选择余地。设生成轨迹集合为:

理论依据:多样性度量的目标是避免模式坍缩(mode collapse),确保生成模型不会在训练集中仅学习有限的轨迹模式。这对动态环境适应和极端场景应对至关重要。
鲁棒性曲线

失败分类
在破坏性测试中,仅统计成功/失败是不够的,需要进一步对失败类型进行分类。设失败事件集合为:

5.3.2 可重复性实验卡与对比基线设计
可重复性实验卡
实验卡是科学实验标准化的实现工具,确保每次实验可复现。内容包括:

理论依据:实验可重复性依赖于确定性控制理论(Deterministic Control),通过固定初始条件和扰动序列,确保实验结果可复现。
对比基线设计
评估扩散轨迹生成模型需设计合理的对比基线,包括:
-
经典规划算法
-
RRT、PRM、MPC
-
用于基线性能对比,如规划速度、成功率、路径长度
-
-
生成模型基线
-
CVAE、GAN轨迹生成方法
-
对比生成多样性和轨迹质量
-
-
随机策略基线
-
随机采样生成轨迹
-
对比模型相对于随机探索的优势
-



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









