







图数据库为何不能只存不算?
有相当一段时间没有更新这个系列了,今天在高铁上,正好有些时间可以慢下来(对,在高铁上慢下来, time is an illusion, space is an illusion, speed is also an illusion, only time-space continuity matters……)思考一下现在的一些对于行业、技术、认知与发展方向的感悟。本知识点事关数字化转型、事关图数据库的价值场景、事关正本清源。
先从一个业界有代表性的看法出发:图数据库只存不算。
这个看法从互联网到金融行业受众还颇广。基于现状来看,有相当一部分的“图数据库”根本和图数据库没有太多关系,完全就是一套图谱应用系统。上层是一些可以交互操作的 Web 端可视化界面(还很卡顿),底层完全是传统的数据库或开源大数据框架 ——— 表面上和数仓还挺兼容,但是完全没有任何图数据库应该有的能力,主要表现在几个方面:
-
图谱可视化层面的交互:只能浅层操作,一层层、一个一个点地展开。
-
任何深度计算、复杂路径计算、全量路径计算都不支持,或只能局部计算、不完全计算,或通过实现批处理的方式预计算。
-
图算法支持非常少:因为底座不支持,上面也没有办法支持。比如那些依赖 Apache Spark GraphX的,能支持的图算法有 10 个顶天了。
-
性能差:所谓只存不算,说的就是数据能存进去,但是算不动。任何深度下钻、穿透都无法以高性能、实时-交互式来进行。
这不禁让人想起了两个 jokes:
-
时序流式地理空间图谱文档关系流批一体嵌入式多模HTAP湖仓一体存算分离自主可控智能自治AI向量全文检索云原生可编程超融合分布式单机一体化serverless数据库--皇帝数据库。
-
海外只要一开源,国内就自研成功,现在已经进阶到,海外只要一发布产品(不管是否开源),国内就立刻自研成功,而且是 30 家立刻涌现的了力度。果然我们这片热土上对于相对论掌握得最好,什么时间沉淀,都是虚妄。
除了上面的笑话。为什么会出现图数据库只存不算,跟厂家作恶、误导客户等乱象息息相关。 那些用关系型数据库做底座的号称是图数据库的例子,当然是只能存不能算。SQL 以及所有的大数据框架,最擅长的无外乎对于表数据的行化或列化处理,分布式改造后,很擅长离散的数据的存储及访问——唯独不擅长对关联数据进行分析、不擅长网络化分析、不擅长深度下钻、不擅长归因分析... ...。 某云的基于 PostgreSQL 的“图数据库”实现,深度下钻竟然宣称用 SQL 去实现,你咋不上天呢? 举个例子:从工商数据集里面某家核心企业出发,找到它的全部对外持股、投资路径,以及被投公司,过滤掉任何持股比例低于 5%的投资,不允许设定深度限制,返回全部结果。试试用 SQL 写出来?个中奥妙,除了程序员能体会,领导们与业务人员感受到的就是一个字:慢!还有复杂度高、不可解释,试想几百几千行 SQL 代码扔给你,没人解释得清楚,这种黑盒化非常不靠谱。
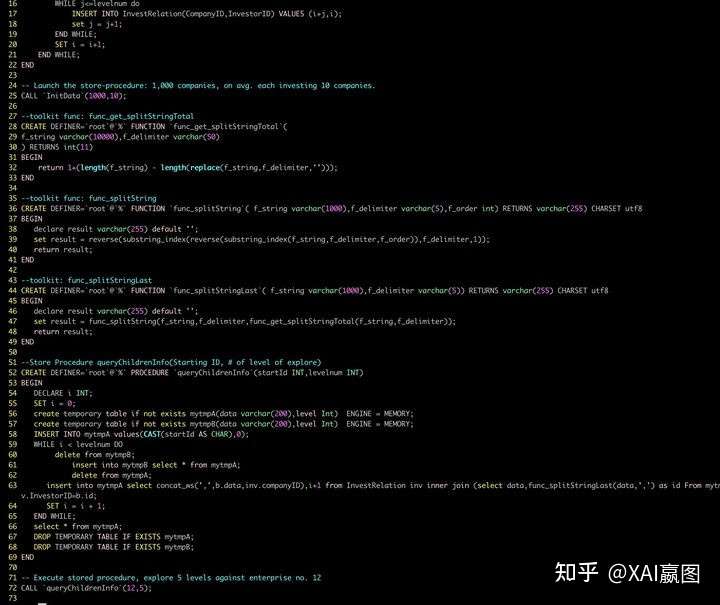
添加图片注释,不超过 140 字(可选)
图数据库上,通过图查询语言来实现下钻穿透:

图查询语言一句话深层穿透(全量)投资网络
上面的图查询语句的逻辑,即便是业务人员也可以理解和实现。非常符合人类的自然语言的特点。
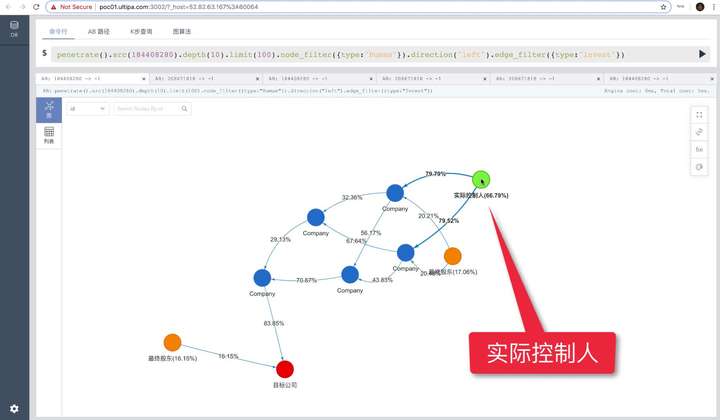
添加图片注释,不超过 140 字(可选)
因为人的思维方式就是层层下钻、抽丝剥茧,上面的语句就是实现了人类的思考与分析方式:
-
从公司 “ABC” 出发
-
沿持股路径遍历,选择持股比例 5%以上的路径
-
穿透 30 层(可调节)-- 递归下钻,这个地方是 SQL 完全不具备的能力,图数据库独有
-
找到最终的被投公司
-
整体的路径返回(包含全部投资、被投公司与持股比例等全部的实体、关联关系等相关信息)
回到说:图数据库不能只存不算。只存的话,用任何其它数据库都可以。数据库必须具有算力,而图数据库的算力的特点就是深度下钻的能力,如果没有这个能力,却要自称图数据库,就一定是骗局。业界这类的公司并不少见—— 把知识图谱应用当图数据库卖给客户,半卖半送,买得越多,业务抱怨越多,科技的烂尾越多。但凡有图思维的方式,在接触图数据库厂家之时就应该有一个更准确的、深入的判断逻辑。
那么什么样的图数据库产品是靠谱的呢? 如下几点,有层层嵌套的关系,注意细节:
-
是否自研图计算引擎部分:因为图不能只存不算,计算部分就非常重要,要说得清楚架构逻辑。传统数据库的架构只有存储引擎,并没有计算引擎,因此在图查询时效率极差。而开源的图计算引擎,多数人一定白嫖像Apache Spark+GraphX这类框架,框架的缺陷都会被集成方直接继承(比如效率差、硬件资源利用率低、ETL 时间长、图算法种类少等)。
-
是否可以对海量数据进行下钻分析:这个部分不是只能对点、边进行存储与访问,是要进行网络化的分析!
-
是否可以实时化的分析:是否可以支持不同类型的数据应用场景,特别是需要频繁数据更新的场景(这一条让很多基于开源大数据框架攒出来的所谓图数据库原形毕露)-- 相关数据更新前后,同一个下钻操作的结果必然变化,没有变化的就是骗子。所谓 HTAP架构,就是要支持这种操作,这是要在压测和实际应用中体现的,而不是 PPT 汇报材料里面胡乱吹的。
-
是否支持丰富的图算法:是否可以扩展图算法、是否可以定制图算法、是否提供可编程接口。
-
凡是忽悠客户所有数据都入图的:都是不求甚解的。把图当数仓用,不是不可以,现在全球范围内,没有任何一家有完备的图数仓技术。尽管未来 10 年的大趋势,随着 GQL 国际标准年底出台,GQL 会逐步取代 SQL(SQL 向 GQL 迁移)——但现阶段的基础架构注定会与图共存、互补。而图的优势,在现阶段不是替换数仓或核心系统,而是部分数据入图进行关联分析来服务各类业务场景(风险、营销,等等)。入图的数据可以被进一步压缩(节省存储空间),而不需要像数仓或大数据框架中那种--数据被放大无数倍... 实为资源浪费。
最后,再补充点儿关于分布式的问题,前面的知识点中已经涉及过相关的内容,下面来点儿不一样的思路。
-
在不需要水平分布式的时候,别瞎分布:分布式对于图意味着 10 倍更为复杂的架构设计,和 10 倍以上的性能下降—— 回到只存不算的问题,分布式唯一的优势,对于图查询与分析模式而言,就是只有在存的时候有优势,而在真正计算的时候,一定是更慢!
-
凡是鼓吹全自动切图、切片的:基本上都是骗子。对这个有疑惑的朋友,建议看看前面几个知识点中提到的论文。在此不再赘述。
-
别瞎分布,但是可以“人工智能”分布式:就是在业务逻辑层面进行分图分布式。先有人工,后有智能。否则都是一本正经的胡说八道。
-
任何违背物理学规律、数学规律、宇宙法则的分布式系统都是骗局——比如,用最小内存的机器、最低配置的服务器,来满足最硬核的业务场景。比如 100 台低配 4 核 8G 内存的机器,来搭建一个巨大的分布式图数据库。这种当然是只存不算,浪费弹药。坦白的说,敢去承建的厂家,应该拿诺贝尔化学与心理学奖。就服你们。
说了些满满的正能量的东西,还有很多有意义的思考与实践,比如:
-
如何避免从集中式到分布式的架构转换中丧失太多性能(所谓只存不算)?
-
如何把集中式与分布式的优点综合利用起来,规避两者的各自缺点(很难,但是很有意义)
-
图数据库应该有的样子是什么?能存能算肯定是一个基本点;再其次如果能支持可伸缩的存算能力就是锦上添花了(对有些业务方来说甚至是雪中送炭)。


















 877
877

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









