




 这篇技术报告介绍了MobileViT,一个结合了卷积神经网络(CNN)和视觉Transformer(ViT)优点的模型,旨在实现轻量、高效且性能优良的图像处理。MobileViT通过transformer进行全局处理,利用CNN进行局部处理,同时引入Multi-scale sampler加速训练。相较于ViT,MobileViT减少了参数数量和优化难度,并优化了推理时延。实验表明,该模型在保持良好性能的同时,实现了更高效的计算。
这篇技术报告介绍了MobileViT,一个结合了卷积神经网络(CNN)和视觉Transformer(ViT)优点的模型,旨在实现轻量、高效且性能优良的图像处理。MobileViT通过transformer进行全局处理,利用CNN进行局部处理,同时引入Multi-scale sampler加速训练。相较于ViT,MobileViT减少了参数数量和优化难度,并优化了推理时延。实验表明,该模型在保持良好性能的同时,实现了更高效的计算。
这是苹果发表的一篇技术报告,主要是介绍了一种结合了CNN和ViT的优点的网络模型MobileViT,轻量快速又效果好。
gihub有开源:https://github.com/chinhsuanwu/mobilevit-pytorch(pytorch)
还有一个非官方的实现:https://github.com/wilile26811249/MobileViT(pytorch)
报告写得很冗余,建议只看关键部分,其它部分都是车轱辘话来回说。
ViT的优点:可以学习长距离的表征依赖;
ViT的缺点:参数多、难以优化、需要大量的数据增强和L2正则去防止过拟合。
Mao et al.[2018]认为,FLOPs并不能完全足够地去反映模型的性能,因为它没有考虑很多影响推理的因素,比如访存、并行度及平台特性。
所以作者也没有单纯去优化FLOPs,而是从三方面来考虑:轻量、泛化能力、低时延。
文章创新点:
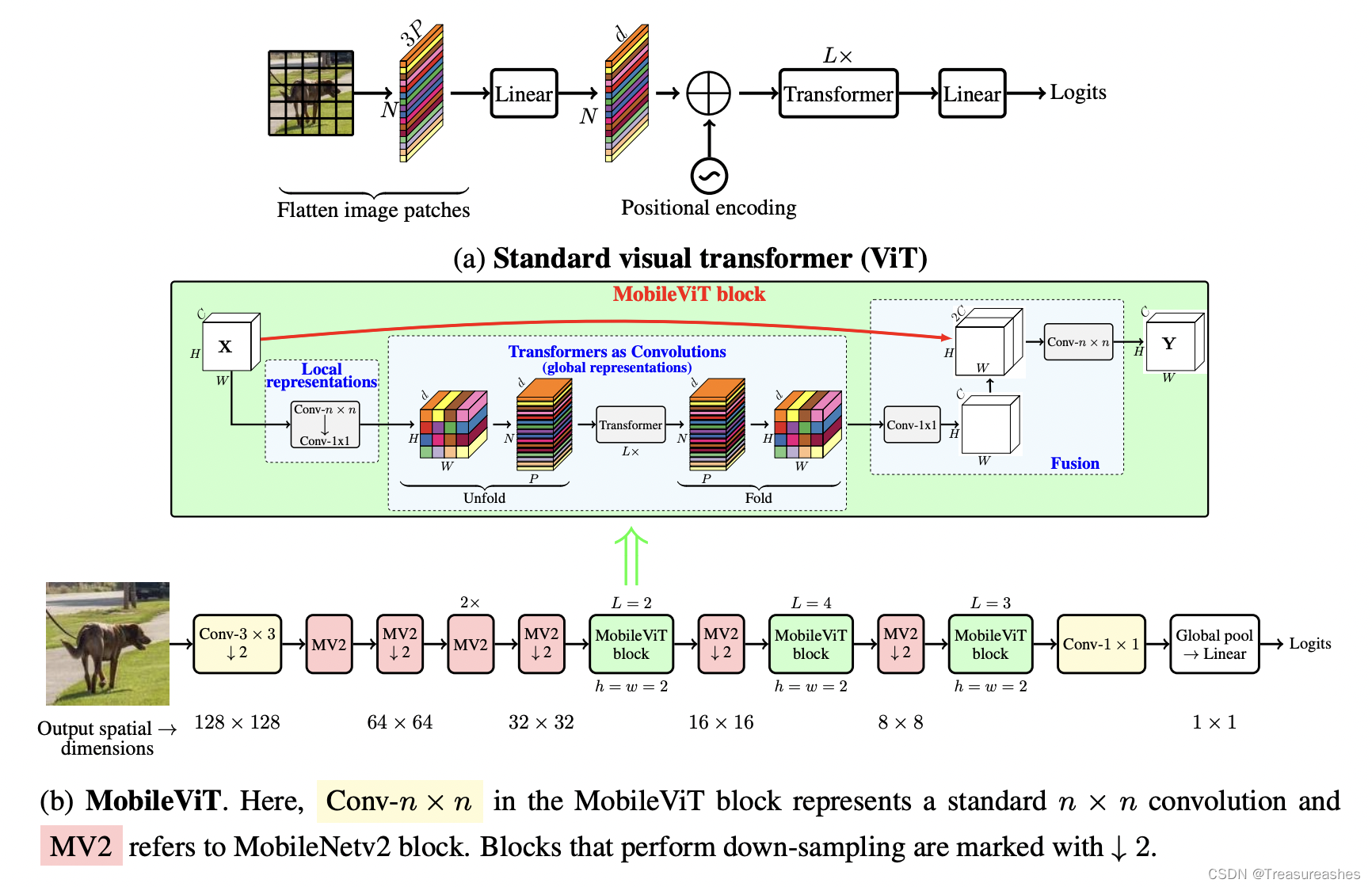
文章的主要思想是用transformer来代替convolution去进行global processing,而convolution主要是来进行local processing。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 344
344

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









