







作者单位:Apple
论文:
https://arxiv.org/abs/2110.02178
代码:
GitHub - apple/ml-cvnets: CVNets: A library for training computer vision networks
1 Introduction
传统CNN易于优化且可根据特定任务整合不同网络,ViT则需要大规模的数据且更难优化,学习量大且计算量大,这是因为ViT缺乏图像固有的归纳偏差。
结合CNN和ViT的优势,为移动视觉任务建立一个轻量级、低延迟、精确率高的网络,能够满足设备的资源限制,并能在不同的任务上有很好的泛化效果。
CNN的优点:空间归纳偏置,对数据增强手段的依赖性较低
ViT的优点:全局处理
更好的性能:对于给定的参数预算,MobileViT 在不同的移动视觉任务(图像分类、物体检测、语义分割)中取得了比现有的轻量级 CNN 更好的性能。
更好的泛化能力:泛化能力是指训练和评价指标之间的差距。对于具有相似训练指标的2个模型,具有更好评价指标的模型更具有通用性,因为它可以更好地预测未知数据集。与CNN相比,即使有广泛的数据增强,其泛化能力也很差,MobileViT显示出更好的泛化能力。
更好的鲁棒性:一个好的模型应该对超参数具有鲁棒性,因为调优这些超参数会消耗时间和资源。与大多数基于ViT的模型不同,MobileViT模型使用基本增强训练,对L2正则化不太敏感。
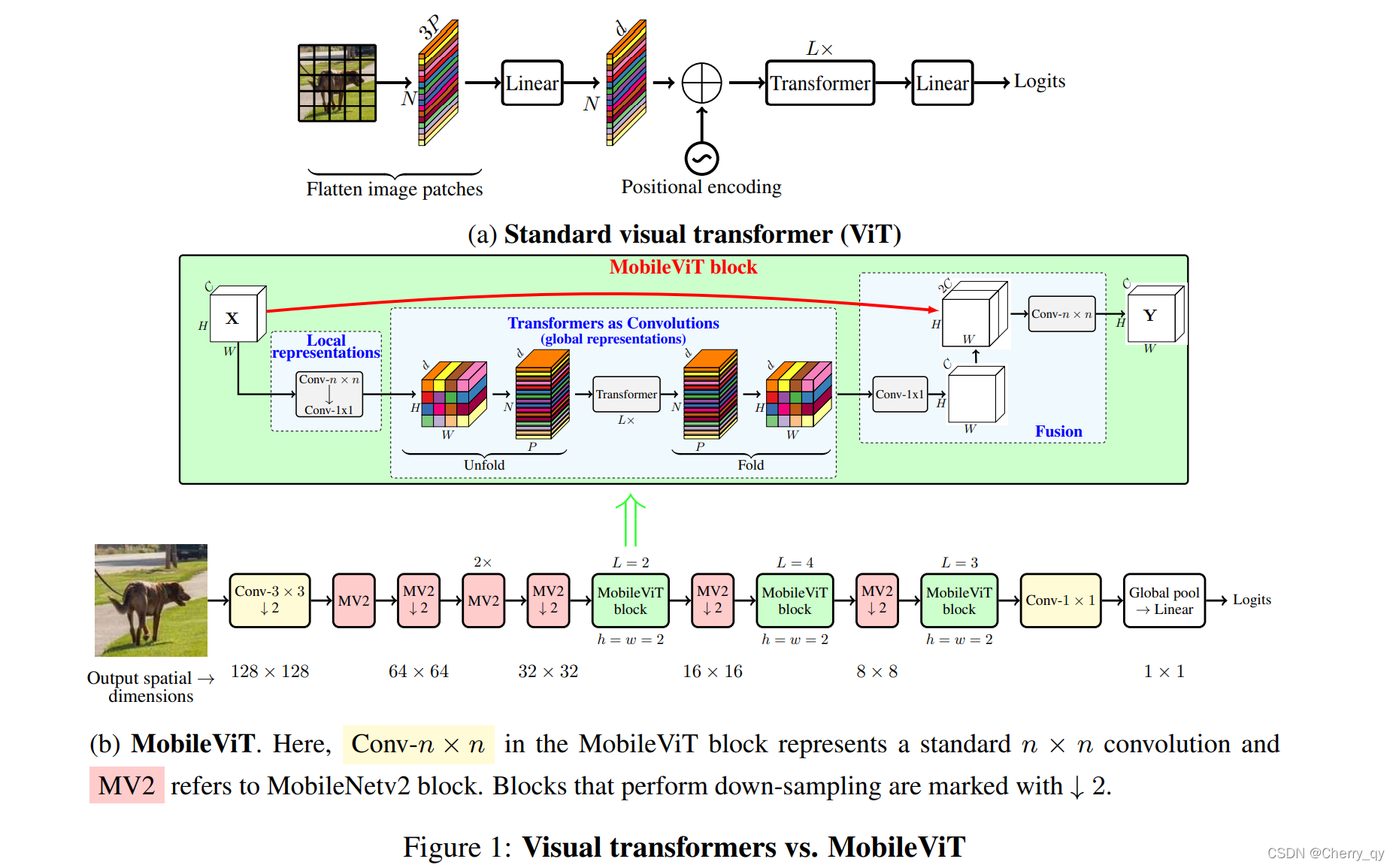
2 Architecture
2.1 网络整体架构
输入图片(HxWxC,H=32,W=32)经过一个普通卷积层(Conv3*3)输入到连续的五个MV2(MobileNet-v2块)中,当(H,W)为32*32时来到了网络的核心部分:MobileVit-Block,接着Block与MV2交叉堆叠,最后一个Block的输出通过一个Conv-1*1 + 全局池化来到了全连接层,紧接着得到最终的输出。
带有↓2标记的皆为下采样块。
n=3,h=w=2
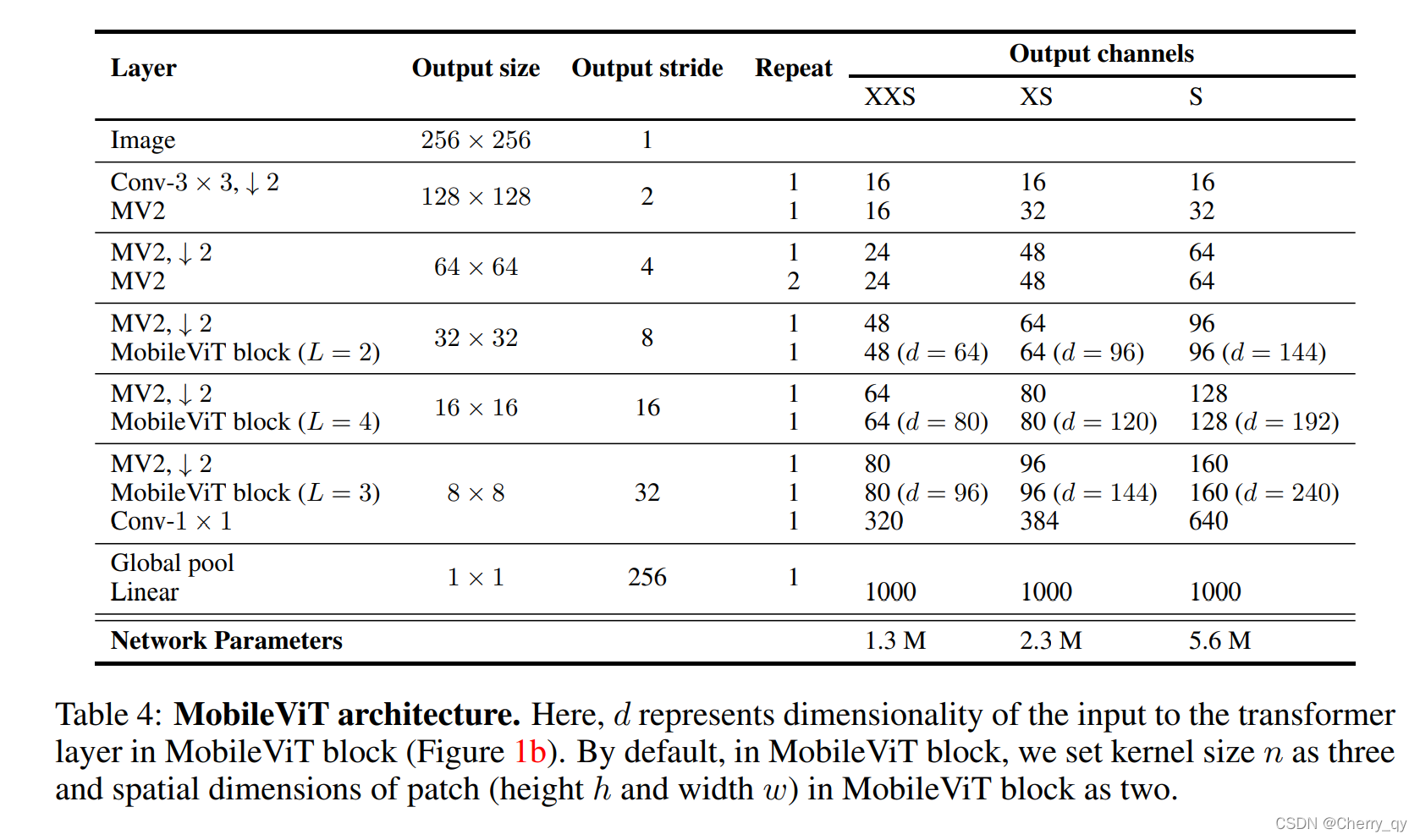
Output stride: Ratio of the spatial dimension of the input to the feature map
2.2 MV2(MobileNetV2):Inverted Residuals and Linear Bottlenecks
首先,我们将V1与V2进行对比。
MobileNet V1用深度可分离卷积提取特征,然后用
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









