




-
DolphinDB与Python
DolphinDB可以在Python中调用,大大降低了时序数据库的使用门槛。
DolphinDB Python API实质是封装了DolphinDB的脚本语言1(也就是前面11次案例中使用到的语言)。Python代码被转换成DolphinDB脚本在DolphinDB服务器执行,执行结果保存到DolphinDB服务器或者序列化到Python客户端。
-
Python API中方法分为两类
-
不触发脚本的执行
只是将Python语言转换成DolphinDB脚本,但并不在DolphinDB服务器上执行。
-
触发脚本的执行
即将Python语言转成DolphinDB脚本语言,又在DolphinDB服务器上运行。
触发脚本执行的方法,都是table类的方法。如下:
方法名 详情 connect(host, port, [username, password]) 将会话连接到DolphinDB服务器。 toDF() 把DolphinDB表对象转换成pandas的Dataframe对象。 executeAs(tableName) 执行结果保存为指定表名的内存表。 execute() 执行脚本。与 update和delete一起使用。database(dbPath, …) 创建或加载数据库。 dropDatabase(dbPath) 删除数据库。 dropPartition(dbPath, partitionPaths) 删除数据库的某个分区。 dropTable(dbPath, tableName) 删除数据库中的表。 drop(colNameList) 删除表中的某列。 ols(Y, X, intercept) 计算普通最小二乘回归,返回结果是一个字典。 -
安装Python API模块
pip install dolphindb # 如果已安装,可以更新,因为当前他们开发迭代较快 pip install dolphindb --upgrade # 当前版本为0.1.13.8 -
连接DolphinDB数据库
-
会话session
Python通过会话与DolphinDB进行交互,就像MySQL与Python的engine一样。
建立会话之前,需要把目标服务器先打开,即服务器的端口呈开放状态。
# 创建会话,建立连接 s = ddb.session() s.connect("localhost", 8920) # # 如需用户名和密码 # s.connect("localhost", 8848, admin, 123456)如果连接成功,运行后不会返回信息。想来是遵循无消息就是最好的消息原则。
如果,连接失败,会返回错误码。
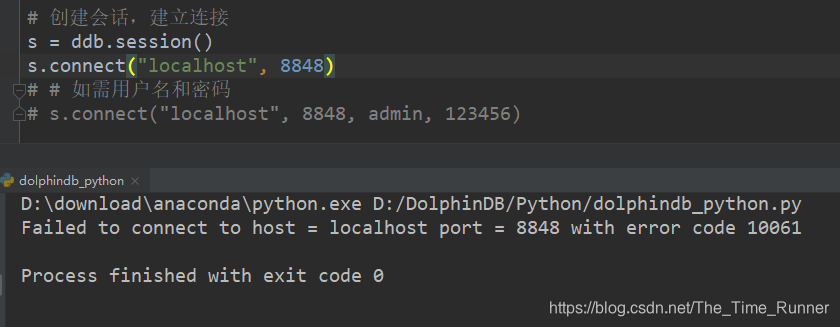
如果采用单节点部署,默认端口8848;如果采用单服务器集群部署,默认端口8920.
-
重新连接
在API使用期间,如果与服务器连接暂时中断,API会进行重新连接,并执行之前未成功运行的脚本。
重新连接会获得一个新的会话,在新会话执行之前连接未成功运行的脚本B之前,可以通过下述代码设置一个任务A,先执行完A再执行未成功运行的B。
import dolphindb as ddb s = ddb.session() s.setInitScript("initTable = streamTable(10000:0, `id`val, [INT,LONG])") currentInitScript = s.getInitScript() -
将数据导入DolphinDB服务器
DolphinDB数据库根据存储方式可以分成3种类型:
- 内存数据库
- 本地文件系统数据库
- 分布式文件系统(DFS)的数据库
关于三种类型的基本概念,参见《内存数据库、磁盘数据库、分布式数据库区别》《数据库分区、分表、分库、分片》。
本文先以本地文件系统的数据库为例。
-
把数据存入内存表
此处使用
example.csv数据,此数据官网有提供,不过下载网速较慢,各位老板如有需要,可以留言,我发给各位。 -
loadText载入到内存表
loadText方法把文本文件载入到DolphinDB的内存表种,并返回一个DolphinDB内存表对象。
>> trade = s.loadText('D:/DolphinDB/Python/example.csv') # Windows中路径需要用反斜杠,与常规Python应用不同 >> print(trade) >> print(type(trade)) <dolphindb.table.Table object at 0x000001CED8779BA8> <class 'dolphindb.table.Table'>当然,这里也可以使用ploadText,速度会翻倍。
对比载入一个840M股票数据csv文件:
方式 时间 pd.read_csv 01:02.877 loadText 00:33.288 ploadText 00:16.969 -
toDF
toDF方法把Python中的DolphinDB对象转换成pandas DataFrame对象。
>> df = trade.toDF() >> print(df) >> print(type(df)) TICKER date VOL PRC BID ASK 0 AMZN 1997-05-15 6029815 23.50000 23.50000 23.6250 1 AMZN 1997-05-16 1232226 20.75000 20.50000 21.0000 2 AMZN 1997-05-19 512070 20.50000 20.50000 20.6250 ... 13133 NFLX 2016-12-28 4388956 125.89000 125.88000 125.8900 13134 NFLX 2016-12-29 3444729 125.33000 125.31000 125.3300 13135 NFLX 2016-12-30 4455012 123.80000 123.80000 123.8300 [13136 rows x 6 columns] <class 'pandas.core.frame.DataFrame'> -
把数据导入到分区数据库
如果数据文件比可用内存大,可以把数据导入到分区数据库中。
-
创建分区数据库
分区方案:值分区;
分区字段:example.csv文件中有3只股票,使用股票代码作为分区字段。
s.database('db', partitionType= 'VALUE', partitions=["AMZN", "NFLX", "NVDA"], dbPath='D:/DolphinDB/Python/valuedb1') # 等同于下面这种分区方案设定方法 s.database('db', partitionType= ddb.settings.VALUE, partitions=["AMZN", "NFLX", "NVDA"], dbPath='D:/DolphinDB/Python/valuedb1')要点:文件路径要用/,否则数据库创建不成功,但是并不会报错
-
创建分布式分区数据库
s.database('db', partitionType='VALUE', partitions=["AMZN","NFLX", "NVDA"], dbPath="dfs://valuedbdfs")与分区数据库相比,只是存储路径
dbPath不同,这里valuedbdfs在数据节点文件夹下面。
-
其他分区方式
除了值分区(VALUE),DolphinDB还支持顺序分区(SEQ)、哈希分区(HASH)、范围分区(RANGE)、列表分区(LIST)与组合分区(COMBO)。
概念及区别详情参见《DolphinDB使用案例2:数据表分区》
-
创建分区表,并追加数据
创建数据库后,可使用函数
loadTextEx把文本文件导入到分区数据库的分区表中。如果分区表不存在,函数会自动生成该分区表,并把数据追加到表中;
如果分区表已存在,则直接把数据追加到分区表中。
loadTextEx函数返回一个包含载入元素的DolphinDB表对象。可通过toDF()函数转成pandas.DataFrame,前文有讲。# 创建分区数据库 s.database('db', partitionType= ddb.settings.VALUE, partitions=["AMZN", "NFLX", "NVDA"], dbPath='D:/DolphinDB/Python/valuedb') # 创建分区表,并载入数据 trade = s.loadTextEx('db', tableName= 'trade', partitionColumns= ['TICKER'], filePath= 'D:/DolphinDB/Python/example.csv') # 查看表行数 print(trade.rows) # 查看表列数 print(trade.cols) # 查看表结构 print(trade.schema) # 查看数据库中已经存在的表 table = s.table(dbPath='D:/DolphinDB/Python/valuedb', data= "trade")上面这段代码,每运行一次,就会发现行数(trade.rows)增多,因为如果表在分布式数据库中存在,就会把数据追加到表上。
要解决这个问题,存在两个方案:
-
数据库去重
可以先判断是否存在重名数据库,如果存在就删除,重新创建。
if s.existsDatabase(WORK_DIR+"/valuedb"): s.dropDatabase(WORK_DIR+"/valuedb")这种方式在数据库不重要的时候没问题,如果数据库是需要长期存在的,这样就太粗鲁了。
-
设置避免重复插入相同数据
创建含主键的流数据表。keyedStreamTable函数。
需要理清逻辑关系,keyedStreamTable函数是直接创建一个包含主键的表,并不能给一个已经创建好的普通表指定主键。
这就要求使用者在使用之处就做好使用规划。
-
-
把数据导入到内存的分区表中
-
loadTextEx
先有数据库,再有表,这个逻辑是不变的。
# 第一步:创建值分区内存数据库 s.database('db', partitionType= ddb.settings.VALUE, partitions=['AMZN', 'NFLX', 'NVDA'], dbPath='') # 第二步:讲数据导入内存的分区表中 trade = s.loadTextEx
DolphinDB使用案例12:Python API接口
最新推荐文章于 2025-11-20 14:30:34 发布
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 750
750

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









