




对于高专业性或企业级的知识问答应用,RAGFlow是各个开发团队的常用框架,它提供的工具链简化了从知识库搭建、向量检索到生成的RAG流水线开发。RAG这条务实的路径让LLM能实时查询私有知识库,显著提升回答相关性和可控性,避免直接调用LLM产生的知识更新慢、回答不准或数据安全风险。
构建健壮的RAG系统,尤其是企业级应用,涉及复杂组件集成与优化。如何在RAGFlow基础上实现性能优化,也成为大家关注的课题。
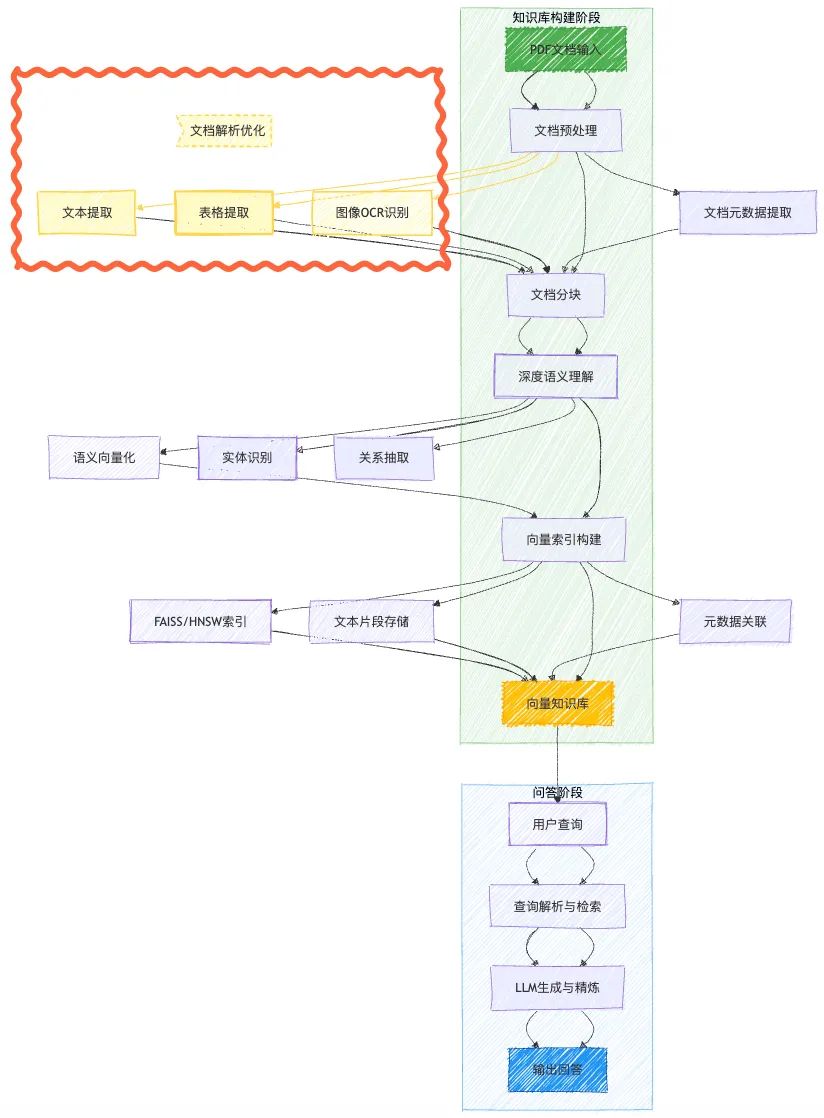
从RAG链路出发,首要关键因素即是文档解析的质量。在应用RAGFlow框架时,我们也需要首先关注解析能力,解析输出的数据是AI应用的“基础燃料”,影响后续分块、检索和最终结果,不尽如人意的解析输出将会大幅度影响RAG性能。
如下图中,对于同一份文件的连续两页目录,其中一页识别为正文,另一页识别为表格,这也导致了后续分块的错误。
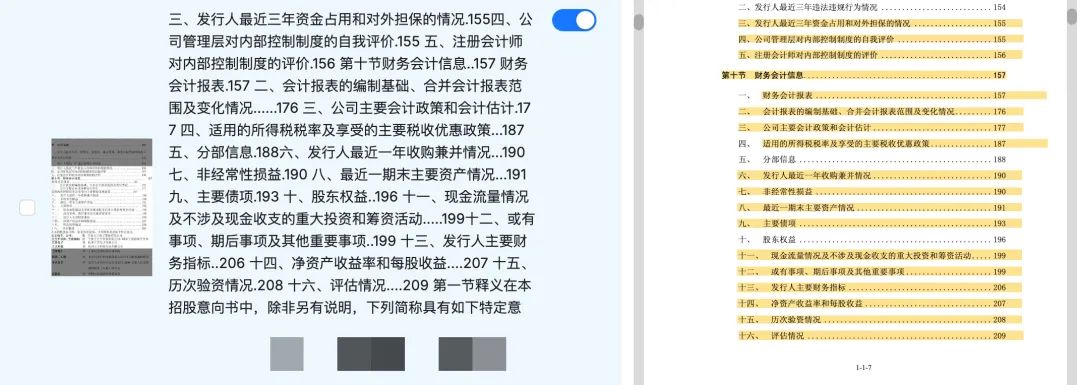
图1

图2
在实际使用中发现的解析问题还包括:
• 对学术论文等分栏文档,内容顺序存在错乱(如从左栏跳至右栏)
• 深度嵌套表格或跨页合并单元格导致数据结构丢失
• 标题层级识别错乱
• 模糊、倾斜或阴影干扰的扫描件OCR错误率较高,书籍装订区附近的文字因弯曲变形无法识别
为了优化解析效果,避免文档中的关键信息在导入知识库时就发生损耗,我们采用了自定义解析工具的策略。
本文将说明文档解析工具的类型与适用性、TextIn的性能、在RAGFlow框架下使用自定义解析的方法、实战教程与完整代码。
了解文档解析工具
简单来说,文档解析工具的核心任务是将非结构化文档(如PDF、图片、扫描件)中的文本、表格、图片等内容识别并提取出来,转化为结构化数据以供机器处理和分析。从社区或商业化、使用方法上,可以区分几种类型:
是否开源
文档解析工具可分为开源和闭源两大类,它们在开放性、可控性、成本和功能深度上存在着差异。开源工具如PyMuPDF、Marker等,商业化产品例如本文实战应用中使用的TextIn xParse。
开源产品的优势在于:1、最为显然的,用户不需要支付软件许可费用。2、高透明度,且可以根据自身需求自由修改、扩展源代码。3、活跃的开源社区可以贡献代码、修复漏洞、提供支持,加速工具的发展和问题解决。
另一方面,其劣势主要体现在:1、技术门槛高:需要具备相当的开发、运维和系统集成能力才能有效部署、配置、定制和维护,对非技术团队或资源有限的组织挑战较大。2、集成与维护负担:用户需自行解决依赖关系、环境配置、版本升级、性能调优、安全补丁等运维工作,耗费时间和人力。3、专业支持有限:主要依赖社区支持,响应速度和问题解决的专业性、保障性通常不如商业闭源产品的官方支持。4、特定场景功能不足:针对特定行业场景(例如复杂的财务表格、医疗报告结构化)的预训练模型或精细化处理能力,可能不如成熟的商业闭源产品。
商业化产品的劣势在于使用成本与低透明度(用户无法直接修改核心代码)。而优势则包括:1、开箱即用,易于集成:通常提供完善的前端界面、软件开发工具包(SDK)、清晰的文档和示例,集成相对简单快捷,使用技术门槛低。2、专业支持与服务:提供专业的技术支持、问题响应、培训服务,减轻用户运维负担。3、深度优化与特定功能:厂商投入大量资源进行核心算法研发、模型训练(尤其在特定领域如法律合同、医学文献、复杂表格识别)和性能优化,往往在精度、特定场景覆盖和功能深度上具备优势。4、持续更新与维护: 专业厂商负责产品的迭代更新、功能增强、漏洞修复和性能优化,用户无需操心底层技术细节。
API调用 vs. 本地部署
在使用方法这个维度,主要有API调用和本地化部署两类,特点如下:
API调用方法便于:1、快速启动,零运维: 无需购置、配置和管理服务器基础设施,注册账号、获取API密钥即可立即使用,大幅缩短上线时间。2、持续获取最新能力: 用户自动获得供应商发布的最新模型、功能和性能优化,无需手动升级。3、降低初始投入: 通常按需付费,避免了前期高昂的硬件和软件许可投资。
但同时,风险项在于:1、不符合部分企业的数据安全要求。2、解析速度和稳定性受网络状况影响。3、 API提供的是标准化的功能接口,功能定制相对受限。
本地部署模式能够保障:1、数据安全与合规性: 文档数据完全保留在用户自己的基础设施(如私有云、数据中心)内部处理,最大程度降低数据风险,更容易满足严格的合规和监管要求。2、性能与延迟可控: 处理过程在本地网络进行,不受公网质量影响,通常延迟更低。对于超大文件或批处理,本地资源更可控。
而其劣势体现在:1、高初始投入与运维负担: 需采购、配置和维护服务器硬件、存储、网络以及软件环境(包括可能的GPU资源),需要专业的IT运维团队。2、部署复杂,上线周期长: 安装、配置、测试和优化本地部署的解决方案需要较长时间和专业知识。3、更新滞后: 用户需要主动关注并手动执行版本升级来获取新功能和修复,过程可能繁琐且存在兼容性风险。
总体来说,最佳选择往往取决于具体需求和资源情况。这一期RAGFlow实战演示中,我们对复杂文档的解析精度有较高要求,同时考虑调用便捷程度,选择了TextIn xParse,支持直接API调用。
TextIn xParse
聊一下为何选择TextIn。
TextIn xParse文档解析是一款大模型友好的解析工具,能够精准还原pdf、word、excel、ppt、图片等十余种格式的非结构化文件,将其快速转换为Markdown或JSON格式返回,同时包含精确的页面元素和坐标信息。支持识别文本、图像、表格、公式、手写体、表单字段、页眉页脚等各种元素,并支持印章、二维码、条形码等子类型,能满足绝大部分复杂文档的解析需求。
其核心能力包括:
• 多种版面元素高精度解析:精准识别标题、公式、图表、手写体、印章、页眉页脚、跨页段落,实现高精度坐标还原,并捕捉版面元素间的语义关系,提升大模型应用表现。
• 行业领先的表格识别能力:轻松解决合并单元格、跨页表格、无线表格、密集表格等识别难题。
• 阅读顺序还原准:理解、还原文档结构和元素排列,确保阅读顺序的准确性,支持多栏布局的论文、年报、业务报告等。
• 自
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1445
1445

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









