 企业级文档处理API推荐
企业级文档处理API推荐




TextIn xParse文档解析是一款大模型友好的解析工具,能够精准还原pdf、word、excel、ppt、图片等十余种格式的非结构化文件,将其快速转换为Markdown或JSON格式返回,同时包含精确的页面元素和坐标信息。
支持识别文本、图像、表格、公式、手写体、表单字段、页眉页脚等各种元素,并支持印章、二维码、条形码等子类型,为LLM推理、训练输入高质量数据,帮助完成数据清洗和文档问答任务,适用于各类AI应用程序,如知识库、RAG、Agent或其他自定义工作流程。
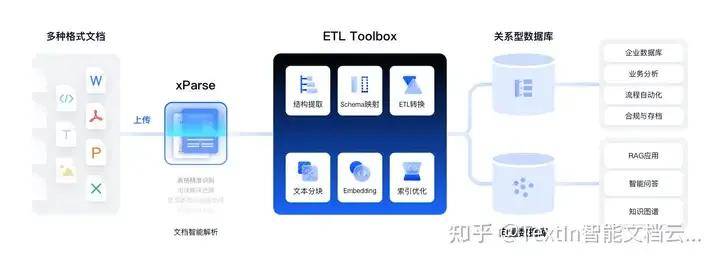
最主要的是TextIn开发者友好,提供清晰的API文档和灵活的集成方式,包括MCP Server、Coze、Dify插件,支持FastGPT、Cherry Studio、Cursor等主流平台。
主要功能
核心功能
● 多种版面元素高精度解析:精准识别标题、公式、图表、手写体、印章、页眉页脚、跨页段落,实现高精度坐标还原,并捕捉版面元素间的语义关系,提升大模型应用表现。
● 行业领先的表格识别能力:轻松解决合并单元格、跨页表格、无线表格、密集表格等识别难题。
● 阅读顺序还原准:理解、还原文档结构和元素排列,确保阅读顺序的准确性,支持多栏布局的论文、年报、业务报告等。
● 自研文档树引擎:基于语义提取段落embedding值,预测标题层级关系,通过构造文档树提高检索召回效果。
● 支持多种扫描内容:能良好处理各类图片与扫描文档,包括手机照片、截屏等内容。
● 支持多种语言:支持简体中文/繁体中文/英文/数字/西欧主流语言/东欧主流语言等共50+种语言。
● 集成强大的图像处理能力:文件带水印、图片有弯曲,都能一键解决,排除图像质量干扰。
文档解析工具具备以下能力:
√ 多模态解析能力:支持PDF(含扫描件)、Office、HTML、图像等办公文档格式,并保留原始层级结构。

√ 复杂元素提取:支持分离获取文字、标题层级、公式、手写字符、图片等信息,可将表格转换为结构化数据(如Markdown表格),并保持行列关系。

最后,文档质量决定了大模型理解的上限。当你正在构建知识库或者搭建文档审核相关的Agent,可以考虑将TextIn MCP Server嵌入到你的搭建工作流中,成为你的文档处理引擎。


















 1466
1466

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









