




大家好,我是小S,在上一篇文章中,我们成功地使用 LLaMA-Factory 对 Qwen2.5-1.5B 模型进行全参微调,并且效果还不错,让胡言乱语的模型开始说人话了,也是稍微有点小成就感了。
那么今天,我们来演示一下 Qwen2.5-1.5B Instruct 版本的全参微调咯。
Qwen2.5-1.5B Instruct版本和Base版本的区别
演示之前,我们先聊一下Qwen2.5-1.5B Instruct版本和Base版本的区别,这里放一张我跑出来的图片(使用AI真的增加了我的幸福感):
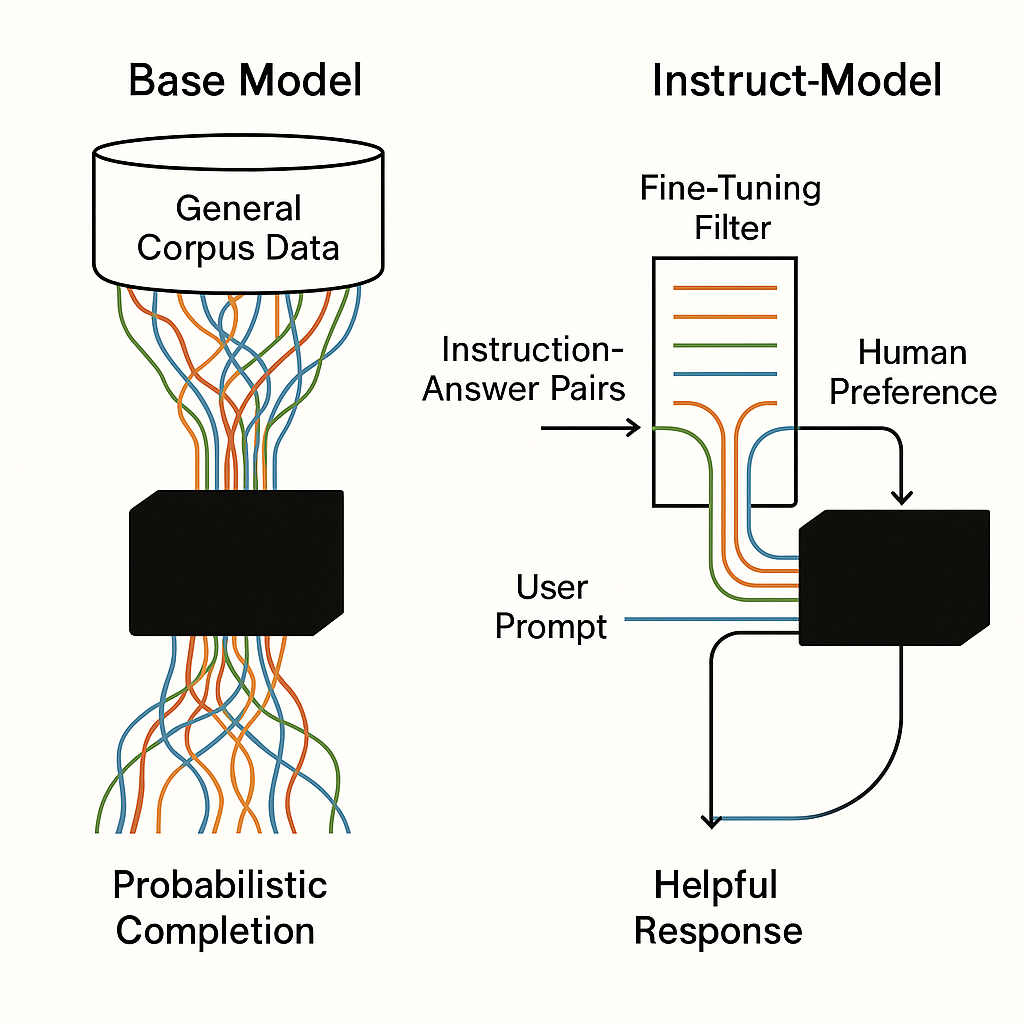
Qwen2.5-1.5B Instruct版本是基于Qwen2.5-1.5B Base版本训练而来,所以就从Base版本开始讲解啦。
Base版本:就像一个读过很多书,懂很多知识,但是是一个"社恐",你直接问它问题,它可能都不知道怎么回答,然后就出现了上一期中胡言乱语的情况了。
Instruct版本:就像是经过专业训练的个人助理(确实是受过训练了,哈哈哈哈),能够准确理解你的意图并提供准确的回复。它不仅能领会你的需求,还能主动给出有价值的建议和补充信息。
开始全参微调
OK,那么现在开始进行全参微调,还是熟悉的配方,熟悉的流程,我们直接建立一张6卡的实例(全参微调真的太吃显卡了,论性价比还得是lora微调)。
1. 创建实例
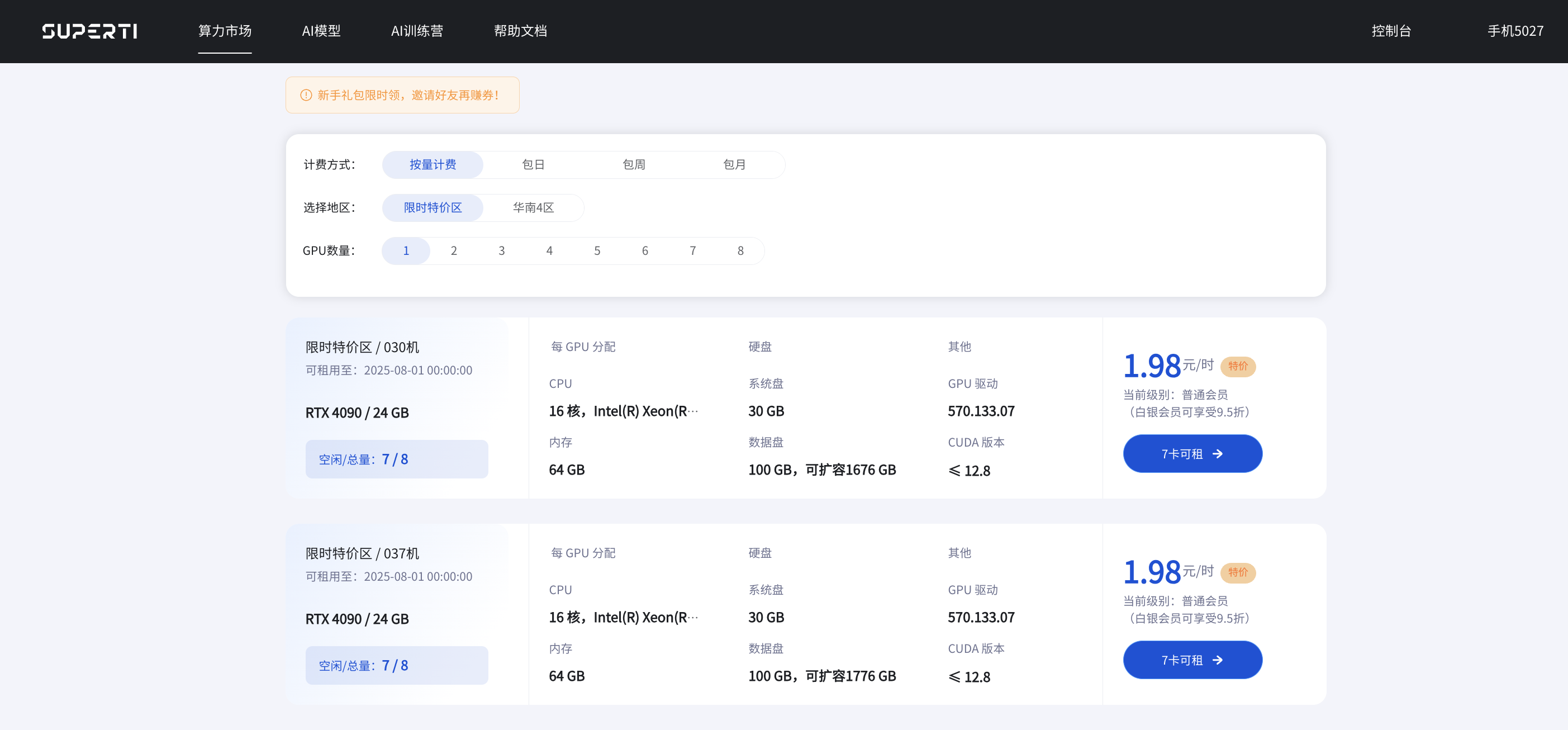
还是打开咱公司自建的AI云平台,建立一张6卡的实例,因为以前真的是被显存不足搞的有点难受,所以现在都会选择6卡,6*24g的显存,想想都舒服。
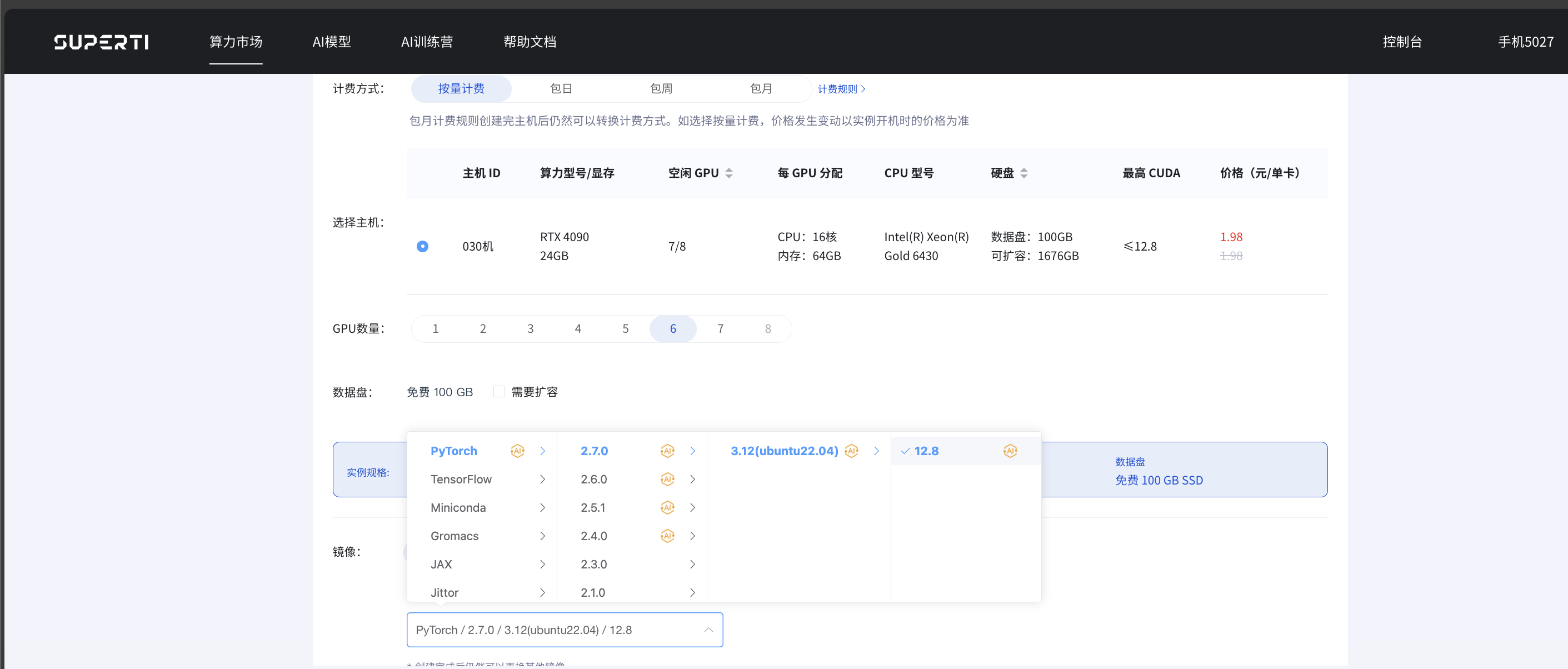
我是真的喜欢使用最新版的东西(手机推送系统必更新的那种人!),所以这里选择的是PyTorch 2.7.0。
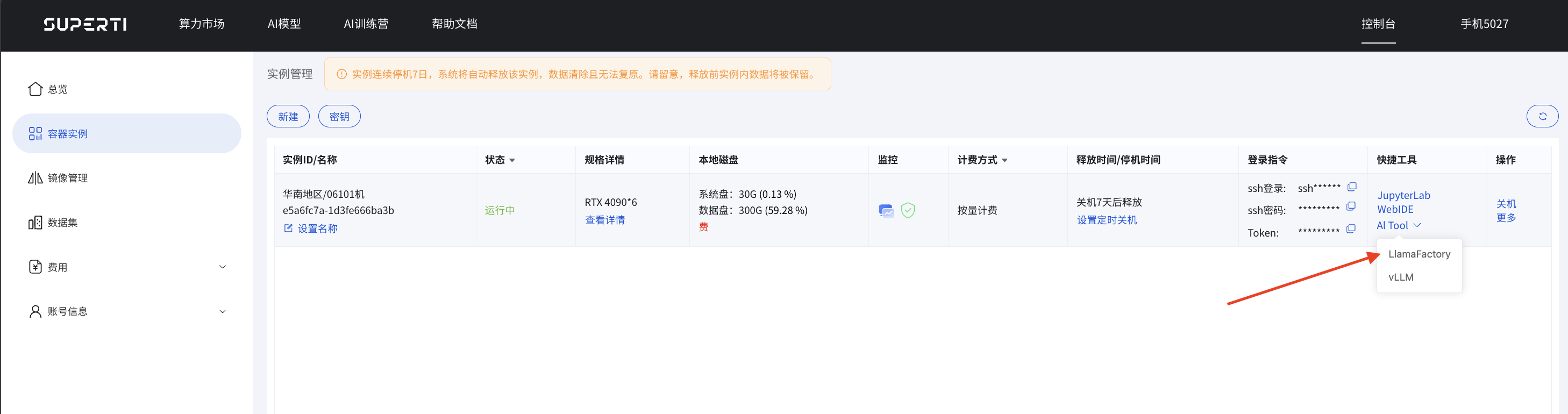
新建完实例后就可以看到LLaMA-Factory了:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 561
561

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









