



要成为一名出色的提示工程师,仅仅掌握“七大要素”等实践技巧是远远不够的。如同高明的剑客需洞悉剑的材质与力学,顶尖的提示工程师也必须理解其“创作”的提示是如何在大语言模型这个“数字大脑”内部掀起“思维”的涟漪。本章将深入到LLM的理论核心,从第一性原理出发,揭示提示与模型交互的底层机制。我们将探讨自回归模型的“下一词预测”本质如何被提示所引导,上下文窗口的演进带来了哪些机遇与挑战,以及提示的结构与语义如何巧妙地“指挥”模型的注意力分布,最终实现对模型行为的精妙调控。
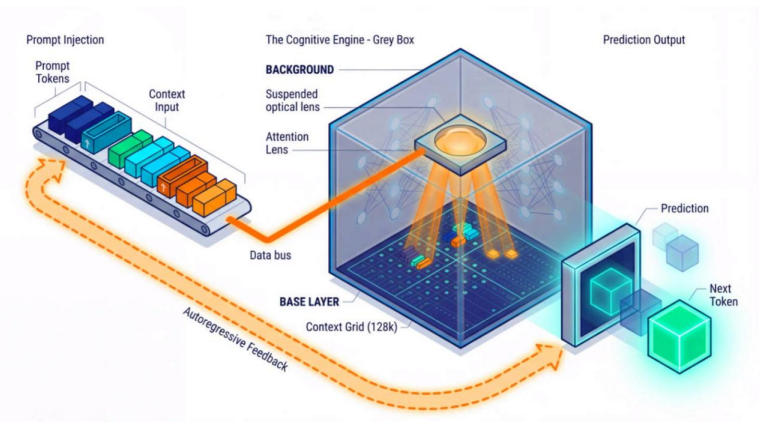
一、自回归语言模型的“下一词预测”机制如何被提示影响
从根本上说,所有主流的大型语言模型,如GPT系列、DeepSeek系列和qwen系列,其核心都是一个自回归(Autoregressive)的“下一词预测”机器。理解这一点,是理解一切提示工程技巧的基石。
自回归的本质:逐词生成的概率链条
“自回归”意味着模型的每一次输出,都依赖于它之前所有的输入(包括原始提示和它自己已经生成的部分)。其工作流程可以简化为以下循环:
接收输入:模型接收到用户提供的完整提示(Prompt)。
计算概率分布:基于提示中的每一个词(Token),模型通过其内部庞大的神经网络(通常是Transformer架构)进行计算,最终在其整个词汇表(Vocabulary)上生成一个概率分布。这个分布代表了模型认为“下一个最可能出现的词”是什么。
采样与输出:模型根据这个概率分布,通过某种采样策略(如贪心搜索、Top-k、Top-p/Nucleus Sampling等)选择一个词作为输出。
更新上下文:将新生成的这个词追加到原始输入的末尾,形成一个新的、更长的上下文序列。
循环往复:模型将这个新序列作为下一次计算的输入,再次预测再下一个词……如此循环,直到满足停止条件(如达到预设长度、生成了特殊的终止符[EOS]等)。
提示的“引力场”作用
在这个逐词生成(Token by Token)的过程中,最初的提示扮演着一个至关重要的角色——它为整个概率链条的走向设定了初始的、强大的“引力场”。提示中的每一个词、每一个标点、每一种结构,都在深刻地影响着模型在每一步预测时的概率分布。其影响机制可以从以下几个层面理解:
激活相关知识网络:当提示中包含“天体物理学”、“黑洞”等词汇时,这些词会作为“钥匙”,在模型庞大的参数矩阵中激活与这些概念相关的神经元和知识图谱。这使得在后续的预测中,与天文学相关的词汇(如“引力”、“视界”、“奇点”)被赋予更高的概率权重,而与无关领域(如“烹饪”、“时尚”)相关的词汇概率则被抑制。
塑造句法与文体结构:提示的句法结构和风格为模型的生成提供了直接的模仿蓝本。如果提示以问句形式出现,模型预测的第一个词很可能是一个引导回答的词(如“是”、“根据”等)。如果提示充满了诗意的、复杂的从句,模型后续的生成也会倾向于模仿这种文风。角色设定(Persona)之所以有效,其底层原理就在于此——通过“你是一位莎士比亚风格的诗人”这样的提示,模型会将后续的词汇选择偏向于古英语词汇和十四行诗的格律结构。
设定任务目标与约束:指令性的词汇(如“总结”、“翻译”、“生成代码”)和约束条件(如“不超过200字”、“使用JSON格式”)在模型内部被编码为一种强烈的“任务导向”。这使得模型在选择下一个词时,会优先考虑那些有助于完成该任务和满足该约束的词。例如,在被要求生成JSON时,模型在生成了一个键(key)之后,预测下一个词为冒号:的概率会急剧升高。
引导推理路径(CoT):当提示中包含“让我们一步步思考”或提供了思维链的示例时,模型实际上是在学习一种“元认知”的生成模式。它学会了在直接给出答案之前,先生成一系列用于推理和解释的中间词汇。这些中间词汇(即“思考过程”)又会成为下一步预测的上下文,从而将一个复杂的、低概率的最终答案,分解为一连串相对高概率的、逻辑连贯的中间步骤,最终提升了复杂任务的成功率。
一个形象的比喻:
想象你在一条宽阔的河流上放下一只小船,小船的最终目的地由水流决定。在这个比喻中,河流是模型内部的概率空间,水流是其预测下一个词的倾向,而小船就是正在生成的文本。
没有提示:河流漫无目的地流淌,小船随波逐流,方向完全随机。
一个简单的提示(如“讲个故事”):你相当于在河流的上游开凿了一条主航道。水流开始有了大致的方向,小船会顺着这条航道前进,但具体的路径仍然有很大的不确定性。
一个精心设计的、包含七大要素的提示:你不仅开凿了主航道,还在沿途设置了堤坝(约束)、灯塔(角色)、航标(示例)和详细的航海图(任务说明)。水流被精确地引导,小船几乎只能沿着你设计的路线航行,最终精准地抵达你期望的目的地。
因此,提示工程的本质,就是通过设计这个初始的“引力场”或“河道系统”,来确定性地影响一个基于概率的、不确定的生成过程,使其最终的输出在宏观上看起来是可控的、智能的、且符合我们预期的。我们不是在改变模型的本质,而是在巧妙地利用它的本质。
二、上下文窗口(Context Window)与 Token 分配策略:早期 2K 到现代 128K/1M 的影响
如果说自回归的“下一词预测”是LLM的心跳,那么上下文窗口(Context Window)就是其“短期记忆”的容量。它定义了模型在单次交互中能够处理的最大信息量(以Token为单位),包括输入的提示和生成的输出。任何超出这个窗口的信息,都将被模型彻底“遗忘”。这一看似简单的参数,其从小到大的演进,却深刻地改变了提示工程的范式和策略。
Token:AI世界的“原子”
在深入探讨之前,必须理解Token的概念。Token是模型处理文本的基本单位。一个英文单词通常是1个Token,而中文汉字则通常是1到2个Token。例如,句子“Prompt engineering is important”可能会被分解为[“Prompt”, “engineering”,“is”,“important”]这4个Token。上下文窗口的大小,就是用这些“原子”单位来衡量的。
2.1 历史演进:从“斗室”到“广厦”的飞跃
上下文窗口的扩张史,是一部模型记忆能力和应用场景不断解放的历史。
早期:2K-4K的“斗室”时代 (约2020-2022年) 早期的模型如GPT-3,其上下文窗口通常在2048个Token左右。这意味着模型一次只能“阅读”大约1500个英文单词。这个“斗室”般的记忆容量带来了巨大的限制:
应用受限:只能处理简短的文本,如一封邮件或几段文字。对于长篇报告、书籍或代码库的分析则无能为力。
对话遗忘:在多轮对话中,模型很快就会忘记对话的开端,导致对话缺乏连贯性。
提示工程的“压缩艺术”:当时的提示工程,很大程度上是一门“压缩的艺术”。工程师需要绞尽脑汁地缩短提示,使用各种技巧(如摘要链、Map-Reduce等)将长文本分块处理,再将结果汇总,过程极其繁琐。
中期:8K-128K的“公寓”时代 (约2023-2024年) 以GPT-4的8K/32K版本和Claude模型的100K版本为标志,上下文窗口迎来了第一次数量级的飞跃。模型从“斗室”搬进了宽敞的“公寓”。
能力解锁:模型现在可以一次性处理整篇数万字的文章、完整的PDF报告或一个中等规模的代码文件。这使得端到端的文档问答、报告摘要和代码解释等应用变得可行。
RAG的兴起:检索增强生成(RAG)技术因此大放异彩。开发者可以在提示中“塞入”更多、更丰富的检索结果作为上下文,显著提升了模型回答事实性问题的准确性。
提示策略的转变:提示工程的重心从“如何压缩信息”转向“如何组织信息”。如何在一个数万Token的上下文中,让模型准确地找到并利用所需信息,成为了新的挑战。
现代:1M+的“广厦”时代 (2025年及以后) 2024年底至2025年,以Google的Gemini 1.5 Pro、月之暗面的kimi和OpenAI的GPT-4.1为代表,上下文窗口被扩展到了100万甚至200万Token,标志着“广厦”时代的到来。模型现在可以一次性“吞下”一整本《战争与和平》、一个庞大的代码仓库,或数小时的会议录音转录稿。
“大海捞针”成为现实:著名的“大海捞针(Needle in a Haystack)”测试成为衡量长上下文模型能力的标准,即在海量无关信息中精准找到一个特定事实的能力。
全新的应用范式:
零样本代码库分析:将整个代码库作为上下文,直接向模型提问“修复这个bug”或“为这个模块生成文档”。
多文档深度分析:同时分析数十份财报、法律文件或科研论文,进行复杂的交叉对比和洞察提取。
终身AI伴侣:理论上,模型可以记录与用户一生的对话,实现真正个性化、有记忆的交互。
2.2 长上下文时代的机遇、挑战与Token分配策略
百万级别的上下文窗口并非“银弹”,它在带来巨大机遇的同时,也催生了新的挑战,并迫使提示工程师发展出全新的Token分配与优化策略。
机遇
信息保真度:无需再对原始信息进行有损压缩(如摘要),可以直接将最原始、最完整的资料喂给模型,最大限度地保留了信息的完整性和准确性。
简化工作流:过去需要复杂编排才能完成的长文本任务,现在一个简单的提示就能搞定,极大地降低了开发复杂度。
涌现新能力:在超长上下文中,模型展现出更强的跨文档推理、复杂指令遵循和细粒度分析能力。
挑战
成本与延迟:这是最现实的挑战。调用一次百万Token的API,其费用和响应时间可能是调用数千Token的数百倍。因此,“是否真的需要这么长的上下文”成为提示工程师必须首先思考的经济学问题。
“迷失在中间”:大量研究表明,模型在处理长上下文时,其注意力并非均匀分布。它们倾向于更好地回忆起位于上下文开头和结尾的信息,而容易忽略或“忘记”埋藏在中间部分的关键细节。这被称为“U型注意力曲线”。
信噪比下降:过长的上下文可能会引入大量与当前任务无关的“噪声”信息,干扰模型的判断,甚至导致其偏离核心任务。
现代Token分配与优化策略
面对上述挑战,2025年的提示工程师不再是简单地“堆砌”信息,而是成为了一位精明的“上下文建筑师”。其核心策略包括:
上下文优先级排序(Context Prioritization):这是对抗“迷失在中间”效应的最有效手段。将最重要、最核心的信息(尤其是任务指令)放置在上下文的开头或结尾。例如,一个常见的最佳实践是将任务指令放在所有背景资料的最后,作为对模型的“最终提醒”。
......基于以上所有信息,请执行以下任务:[明确、具体的任务指令]
结构化上下文(Structured Context):使用Markdown的标题、列表,或XML标签来组织长上下文,为其提供清晰的结构。这如同为一本厚书创建了详细的目录,能帮助模型更好地导航和理解不同信息片段之间的关系。
<document source="财报A">...</document><document source="新闻稿B">...</document>
指令注入(Instruction Injection):对于极其复杂的任务,可以在长上下文的中间部分,战略性地“重新注入”或“提醒”关键指令。例如,在处理完一份长文档后,可以加入一句:“提醒:请记住,你的最终目标是比较A和B的风险,而不仅仅是总结它们。”
动态上下文构建:即使拥有百万Token窗口,也并非总要用满。构建一个智能的预处理层,根据用户的具体问题,从海量知识库中动态检索出最相关的一个子集(可能几万或几十万Token),而不是无脑地将所有信息全部塞入。这是一种在能力与成本之间取得平衡的务实做法。
总之,上下文窗口从2K到1M+的演进,是LLM发展史上的一座重要里程碑。它将提示工程师从“螺蛳壳里做道场”的窘境中解放出来,但也对其提出了更高的要求——从单纯的“指令编写者”,转变为能够驾驭海量信息、洞悉模型注意力机制、并能在效果与成本间做出最佳权衡的“信息架构师”。
三、提示语义、结构与模型注意力分布的关系(定性解释)
如果说上下文窗口是模型的“短期记忆”容量,那么注意力机制(Attention Mechanism)就是其“意识”的焦点。模型在生成每一个新词时,并非对上下文中的所有信息一视同仁,而是会有选择性地“关注”那些与当前预测任务最相关的部分。理解并利用注意力机制,是提示工程从“术”到“道”的关键一步。提示的语义和结构,正是指挥模型注意力焦点流向的无形之手。
3.1 注意力机制的直观理解
注意力机制最早是为了解决机器翻译中长句子对齐问题而提出的,后来成为Transformer架构(现代LLM的基础)的核心组件。其本质可以被直观地理解为一个“相关性加权”的过程。
想象你在阅读一篇复杂的科学论文来回答一个特定问题。你不会逐字逐句地平均阅读每个词。相反,你的目光会在论文中跳跃:
首先,你会关注与问题关键词高度相关的段落。
在阅读这些段落时,你会重点关注其中的核心概念、数据和结论。
你会暂时忽略那些与当前问题无关的背景介绍或旁支细节。
LLM的注意力机制与此非常相似。在预测下一个词时,模型会为上下文中的每一个已有词(Token)计算一个“注意力分数(Attention Score)”。这个分数代表了该词对于预测下一个词的“重要性”或“相关性”。分数越高的词,其信息在模型最终决策中的权重就越大。
3.2 提示的语义如何引导注意力
提示的语义(Semantics),即词汇的选择和句子的含义,是引导注意力最直接的方式。
关键词的“磁吸效应”:任务指令中的核心动词(如“总结”、“对比”)和名词(如“财务风险”、“市场份额”)如同磁铁,会吸引模型在背景资料中寻找与之语义相近或相关的词汇。模型会给予这些被“吸住”的词汇更高的注意力分数。例如,当任务是“总结财务风险”时,文本中出现的“负债”、“现金流”、“违约”等词的注意力权重会自然升高。
上下文的语义关联:模型在训练过程中学习了海量的词汇共现模式。当提示中出现“法国”和“首都”时,模型内部关于“巴黎”的表示会被激活,并在后续生成中给予其极高的注意力。提示工程师可以利用这种关联性,通过构建一个语义连贯的上下文,来“预热”模型,使其注意力集中在特定的知识域内。
角色设定的“风格滤镜”:当提示设定了“你是一位诗人”的角色时,“诗人”这个词会作为一个强大的语义锚点,使得模型在后续生成中,对那些具有比喻、押韵、意象等诗歌属性的词汇和句式结构给予更高的关注度。
3.3 提示的结构如何“框定”注意力
如果说语义是内容上的引导,那么提示的结构(Structure)则是形式上的规训。良好的结构能帮助模型更高效地切分和理解信息,从而将注意力分配到正确的位置。
分隔符的“防火墙”作用:使用清晰的分隔符(如###、---、XML标签)在不同信息模块(如角色、背景、任务、示例)之间建立“防火墙”,是提示工程中最基础也最有效的技巧之一。这会引导模型的注意力机制在不同的模块内部进行聚焦,而不会轻易地“跨界”混淆。例如,当模型在处理<task>标签内的指令时,它的注意力会主要集中在该标签内部,同时参照<context>标签内的内容,而不会被<example>中的具体文本所干扰。
标题与列表的“大纲效应”:使用Markdown的标题(#, ##)和列表(-, *)来组织长篇的背景资料,相当于为模型提供了一份内容大纲。当任务指令涉及到某个特定的标题时,模型的注意力会自然地集中在该标题下的段落,而忽略其他章节。这极大地提升了在长上下文中信息检索的效率和准确性。
指令位置的“首尾效应”:如前文所述,由于模型注意力分布的“U型曲线”特征,位于提示开头和结尾的指令通常会获得最高的天然注意力权重。因此,将最重要的任务指令放在结尾,相当于在模型即将做出决策的最后一刻,用最响亮的声音“提醒”它核心目标是什么,从而最大化地框定其最终的注意力焦点。
示例的“模板匹配”:Few-Shot示例的结构,为模型的注意力提供了一个清晰的“模板”。模型在处理新任务时,会尝试将新的输入与示例中的输入进行“对齐”,并模仿示例中“输入->输出”的注意力流动模式。例如,如果示例展示了从一段文本中提取人名和地名,模型在处理新文本时,其注意力就会被引导到类似的实体词上。
定性总结
我们可以将提示的语义和结构与模型注意力分布的关系,定性地总结为一种“引导与塑造”的关系。
|
提示的语义通过内容上的相关性,“引导”注意力的流向,使其聚焦于特定的知识和概念;而提示的结构则通过形式上的组织,为注意力的流动“塑造”出清晰的边界和路径,防止其发散和混乱。 |
一个优秀的提示工程师,就像一位电影导演。他通过剧本(语义)告诉演员(模型)故事的核心是什么,应该表达何种情感;同时,他又通过分镜和场面调度(结构),精确地控制摄像机(注意力)的焦点应该落在何处,何时应该给特写,何时应该用全景。只有当内容和形式完美结合,才能最终拍出一部符合预期的、精彩的“电影”(输出)。
自我批判与反思(Self-Critique and Reflection):探测模型的“不确定性”
通过提示引导模型对其自身的输出进行评估,可以揭示其内部的“置信度”和对问题边界的认知。
调试价值:当模型给出一个看似确定的答案时,要求它进行自我批判,可能会暴露其背后的“不自信”。这对于防止“一本正经地胡说八道”(即幻觉)至关重要。
提示策略:
“在给出答案后,请列出你所做的任何关键假设。”
“请指出你的回答中可能存在的不确定性或争议点。”
“请从一个批判者的角度,审视你刚才的回答,并提出改进意见。”
示例:
问题:“2030年,人类会登陆火星吗?”
一个带有反思的回答:“……综上所述,人类很有可能在2030年左右实现载人登陆火星。然而,需要指出的是,这个预测基于几个关键假设:1)SpaceX的星舰项目能按计划成功;2)NASA的预算能持续获得支持;3)不会出现重大的技术或安全挫折。 任何一个环节的延迟都可能将这个时间点推后数年。”
这段加粗的反思,清晰地向我们展示了模型做出预测的逻辑依据和风险边界,其可信度远高于一个简单的“是的,会”的回答。
3.4 总结:从“黑箱”到“灰箱”
提示可解释性并非要将LLM这个“黑箱”变成完全透明的“白箱”,这是不现实的。它的目标,是通过结构化的交互设计,将其从一个完全不可知的“黑箱”,转变为一个其内部逻辑和状态可以在一定程度上被观察和理解的“灰箱”。
对于提示工程师而言,这意味着在设计提示时,需要超越“我想要什么”的简单思维,而是要思考“我如何才能知道模型是否真正理解了我的意图,以及它得出答案的路径是否可靠?”。将CoT、结构化输出、自我反思等可解释性技术融入提示设计中,不仅是提升复杂任务性能的法宝,更是构建可信、可靠、可维护的AI应用的基石。它让调试不再是盲人摸象,而是有迹可循的科学诊断过程,从而极大地提升了提示工程的效率和成功率。
四、提示工程的认知科学基础
理解提示工程,不能仅仅停留在技术层面,更需要深入到认知科学的底层原理。大型语言模型虽然是基于统计学习的数学模型,但其行为模式在许多方面与人类的语言理解和生成过程有着惊人的相似性。通过借鉴认知科学、心理语言学和神经科学的研究成果,我们可以更深刻地理解"为什么某些提示有效,而另一些无效",并从中提炼出更具普适性的设计原则。
4.1 启动效应与提示的"认知框架"
启动效应(Priming Effect)是认知心理学中的一个经典现象:当人们接触到某个刺激(如一个词、一张图片)后,会在短时间内对与之相关的概念更加敏感,处理速度更快,判断也会受到影响。例如,如果先让被试者阅读一段关于"老年"的文本,他们随后走路的速度会不自觉地变慢。
这一现象在LLM中同样存在。提示的开头部分,尤其是角色设定和背景信息,实际上是在为模型设置一个“认知框架”(Cognitive Frame)或“心理图式”(Schema)。这个框架决定了模型在后续处理中会优先激活哪些知识、采用哪种推理模式、以及使用什么样的语言风格。
实践启示:
框架的一致性至关重要:如果提示的开头设定了一个“科学严谨”的框架,但后续的任务指令却要求“发挥想象力,天马行空”,这种框架冲突会导致模型的输出质量下降。
利用正向启动:在提示中提前植入与期望输出相关的关键词和概念。例如,如果希望模型生成一篇“富有同理心”的文章,可以在背景中加入“理解他人感受”、“换位思考”等词汇,这会启动模型内部与同理心相关的语义网络。
避免负向启动:不要在提示中过多提及你不想要的内容。例如,说“不要写得太学术“反而可能启动“学术”相关的语义,不如直接说“请用通俗易懂的日常语言”。
4.2 工作记忆与上下文窗口的认知负荷
人类的工作记忆容量是有限的,心理学家George Miller在1956年提出的经典理论认为,人类一次只能在工作记忆中保持大约7±2个“组块”(chunks)的信息。当信息量超过这个阈值,认知负荷过高,理解和推理能力就会急剧下降。
LLM的上下文窗口,在某种意义上类似于人类的工作记忆。虽然技术上模型可以“看到”整个上下文窗口中的所有Token,但研究表明,模型对信息的注意力分布是不均匀的,且存在“迷失在中间”(Lost in the Middle)现象:对于非常长的上下文,模型往往对开头和结尾的信息更敏感,而对中间部分的信息关注度下降。
实践启示:
信息的“组块化”:将大量的背景信息组织成清晰的、有逻辑层次的"组块",并使用标题、编号、分隔符等视觉和结构化手段来强化这种组织。这类似于帮助人类减轻认知负荷的方法。
关键信息的位置优化:将最重要的信息放在提示的开头或结尾,避免埋没在冗长的中间部分。
渐进式信息呈现:对于极其复杂的任务,不要试图在一个提示中塞入所有信息。可以采用多轮对话的方式,逐步引入信息,让模型的"工作记忆"始终聚焦在当前最相关的部分。
4.3 元认知与“思考时间"的深层价值
元认知(Metacognition)是指“对认知的认知",即个体对自己思维过程的意识、监控和调节能力。一个具备良好元认知能力的学习者,会在解决问题时主动问自己:“我真的理解这个问题了吗?"、“我的这个思路有没有漏洞?"、“有没有更好的方法?"
前文提到的“思考时间"(Thinking Time)要素,本质上是在激发LLM的“元认知"能力。通过要求模型“先思考,再回答",我们实际上是在引导模型进行一种自我监控和自我调节的过程。在这个过程中,模型会:
澄清问题:重新表述问题,确保理解正确。
激活相关知识:搜索内部的知识网络,找到与问题相关的概念和规则。
生成候选方案:提出一个或多个可能的解决路径。
评估与选择:评估每个方案的合理性,选择最优的一个。
执行与验证:按照选定的方案执行,并在过程中检查是否出现错误。
实践启示:
显式的元认知提示:在提示中加入元认知的引导语,如“在回答前,请先问自己以下三个问题:1) 我是否完全理解了问题? 2) 我需要哪些信息? 3) 最合理的解题思路是什么?"
分阶段的思考框架:为复杂任务设计一个明确的思考框架,如“理解-分析-综合-评估-输出",并要求模型在每个阶段都输出其思考内容。
自我批判机制:在生成初步答案后,要求模型“扮演一个批判者的角色,找出刚才答案中可能存在的三个问题",然后基于这些批判进行修正。这种"自我对话"能显著提升输出的质量和鲁棒性。
4.4 语言的“具身性"与多模态提示的优势
认知科学的具身认知(Embodied Cognition)理论认为,人类的思维不仅仅发生在大脑中,而是深深根植于身体的感知和运动经验之中。我们对抽象概念的理解,往往是通过具体的、感官的隐喻来实现的。例如,我们说“温暖的友谊"、“沉重的责任"、“光明的未来",这些都是将抽象的情感和概念映射到身体的温度、重量和视觉感受上。
虽然LLM没有身体,但其训练数据中包含了大量描述感官经验的文本。因此,使用具象化、感官化的语言,往往比抽象的、学术化的语言更能激发模型的“理解"。
更进一步,在2025年的多模态时代,我们可以直接向模型提供图像、音频等非文本信息。这些信息携带了文本难以表达的丰富细节(如一张脸的表情、一段音乐的情绪),能够为模型提供更“具身"的上下文。
实践启示:
使用具象化的比喻和例子:在解释抽象概念时,尽量使用生动的、可视化的比喻。例如,解释“区块链"时,不要只说“分布式账本",而是说“想象一个账本,它的每一页都被复印了成千上万份,分发给不同的人保管,任何人想要篡改其中一页,都会被其他人的副本揭穿"。
多模态信息的战略性使用:当任务涉及视觉、空间或情感等难以用文字精确描述的内容时,直接提供图片或音频。例如,要求模型分析一幅画的艺术风格,与其用千言万语描述,不如直接上传图片。
跨模态的一致性:在多模态提示中,确保文本指令与图像/音频内容是一致的、互补的,而非矛盾的。
通过将认知科学的洞察融入提示工程实践,我们不仅能提升提示的有效性,更能建立起一套更具理论深度和普适性的方法论,使提示工程真正成为一门“科学"而非仅仅是“技艺"。
本指南共计分为“提示工程概述、大模型与提示交互机制、发展生态与典型工具/论文简述、高级提示工程技术、特定场景应用实践、评估与优化、前沿趋势与未来展望”七大部分内容。上述文章仅为「大模型与提示交互机制」的部分内容摘选。
完整版指南,请扫描下方二维码下载。


















 1121
1121

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









