



为什么你的智能体总是不稳定?
Google Cloud AI团队发布了最大化智能体设计成功率的数学推演。

通过统一的概率框架将AI智能体设计从经验主义的炼金术提升为可量化的系统工程,揭示了多智能体协作本质上是对成功概率的动态搜索。
数学重构:将直觉转化为工程定律
我们见证了从简单的文本生成到能够自主规划、调用工具的AI智能体的飞跃。
现在的开发者手中通过各种框架捏造着形态各异的智能体,有的基于ReAct回路,有的依赖复杂的图结构,还有的试图组建多智能体团队。
大家都在凭借直觉行事,通过不断的试错来调整提示词、修改流程,试图让这些智能体在处理复杂任务时更聪明、更稳定。
这种开发模式像极了早期的炼金术,充满了经验主义的色彩。
我们知道加点这个提示词会好用,改个那个参数会变傻,但没人能精确地说出为什么,更无法量化不同架构之间的取舍。
Google Cloud AI的研究团队试图为整个智能体领域建立一套统一的度量衡。他们提出,无论智能体的架构多么花哨,其本质都可以被抽象为一个概率过程。
智能体的核心目标非常纯粹,就是在给定初始上下文的情况下,最大化执行一系列特定动作的概率,从而达成预定目标。
这听起来简单,一旦将其通过马尔可夫链的数学形式表达出来,我们就能看清那些隐藏在代码背后的真相。
这套框架不仅解释了为什么ReAct会陷入死循环,更揭示了多智能体系统(Multi-智能体 Systems)之所以强大的数学原理——它们引入了全新的自由度,让系统有了在运行时动态优化成功率的能力。
我们不再需要盲目地调整提示词,可以像工程师调节控制杆一样,精准地操作智能体的概率模型。
在数学的视角下,智能体的操作过程就是一条由概率连接而成的锁链。
每一步操作都不是确定性的,而是基于当前的上下文(Context)和上一步的状态(State),以一定的概率选择下一个动作(Action)。
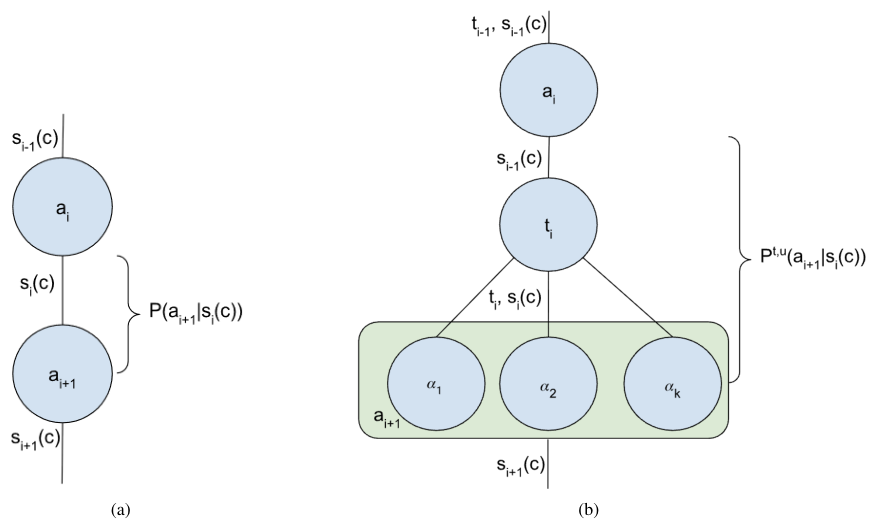
这就是所谓的马尔可夫链。
以最经典的ReAct模式为例,它本质上是一个思考-行动的循环。模型先生成一个想法(Thought),然后基于这个想法执行一个动作(Action),最后观察结果并更新状态。
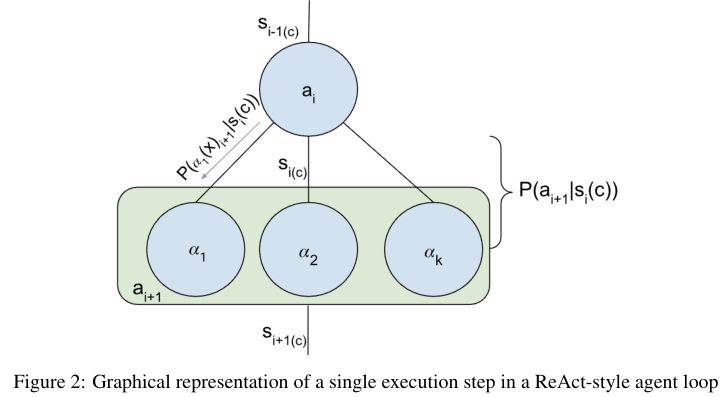
ReAct架构虽然优雅,却存在致命的数学缺陷。
它本质上是一个随机游走(Random Walk)的过程。
智能体在巨大的动作空间中漫步,每一步都面临着概率发散的风险。
如果所需的动作序列很长,或者每一步的可选动作很多,最终成功走完全程的概率就会指数级下降。
缺乏约束的随机游走容易导致不收敛,也就是我们常见的智能体陷入死循环,或者在幻觉中越走越远。
这正是当前单体智能体难以处理超长复杂任务的根本原因:概率链条越长,累积误差越大,最终成功的可能性就被稀释得微乎其微。
自由度:掌控智能体的控制杆
为了解决随机游走带来的概率衰减问题,我们需要更多的手段来干预概率链条。
Google的研究人员引入了一个极其精彩的概念——自由度(Degrees of Freedom)。
在工程学中,自由度代表了系统可以独立变化的参数数量。
在智能体设计中,自由度就是开发者手中可以调节的旋钮和控制杆。拥有的自由度越多,我们优化系统性能的空间就越大。
我们将目光投向控制流(Control Flow)架构。
与ReAct的自由散漫不同,控制流架构通过预定义的图(Graph)或状态机,限制智能体在每一步的活动范围。
这种做法直接切断了大部分错误的路径。通过人为地划分任务,我们将一个巨大的、低概率的长链条,拆解成了多个短小的、高概率的子链条。
在控制流架构中,开发者不仅可以优化初始提示词,还可以针对图中的每一个节点定制提示词,甚至为不同的节点配备不同的模型工具。
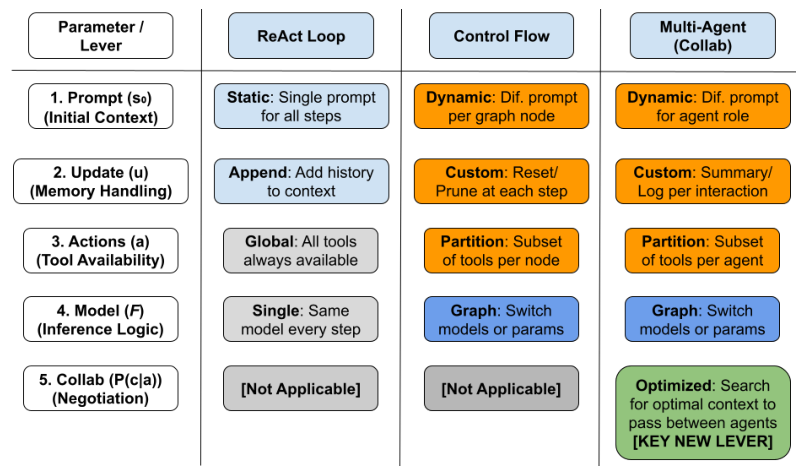
ReAct模式的大部分控制杆都是锁定状态(Static/Global),而控制流模式将它们一一解锁(Dynamic/Partition/Switch)。
控制流虽然强大,但它依然依赖于开发者预先定义的规则。所有的路径划分、节点设计,都需要在运行前写死。这意味着系统的上限被锁死在了开发者的认知边界内。
真正的质变发生在多智能体系统(Multi-智能体 Systems, MAS)。
多智能体系统不仅仅是让几个智能体在聊天群里对话那么简单。在概率框架下,它引入了一个前所未有的自由度——协作概率。
在单体智能体中,上下文是由环境被动提供的。但在多智能体系统中,上下文是由其他智能体主动生成的。这意味着系统拥有了动态搜索最佳上下文的能力。
当两个智能体进行协作或谈判时,它们实际上是在通过不断的交互,寻找一个能让整体成功概率最大化的中间状态。
我们可以把这看作是在高维概率空间中的一次联合搜索。
智能体A并不直接执行任务,而是通过生成上下文来调整智能体B的状态,直到智能体B处于一个极高成功率的局部最优解中。
这种机制不需要重新训练模型,也不需要人工硬编码规则。它利用模型本身的推理能力,在运行时动态地对齐任务需求。
这就是为什么多智能体系统往往能解决单体智能体无法处理的难题。
通过将大任务拆解,并允许智能体之间进行上下文的协商,我们实际上是在用计算换取概率。我们在运行时消耗更多的推理资源,来换取一条通往目标的更确定性的路径。
下表详细总结了从ReAct到多智能体协作,开发者手中的控制权是如何一步步扩大的。
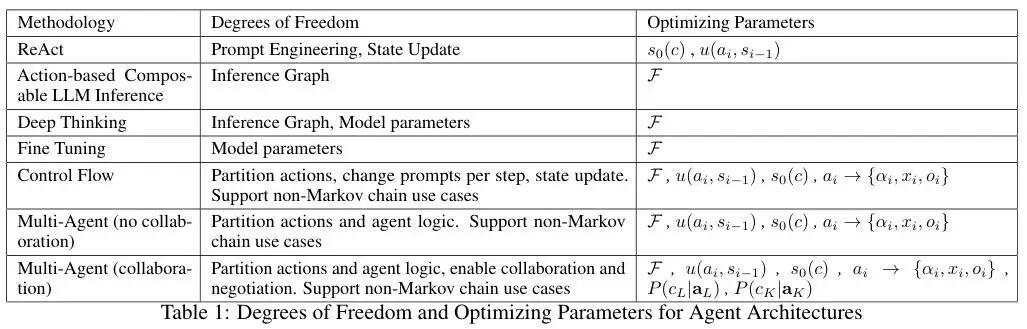
协作的本质:用计算换取确定性
多智能体协作引入的P(cL|aL)和P(cK|aK)就像是概率链条上的润滑剂和纠偏器。
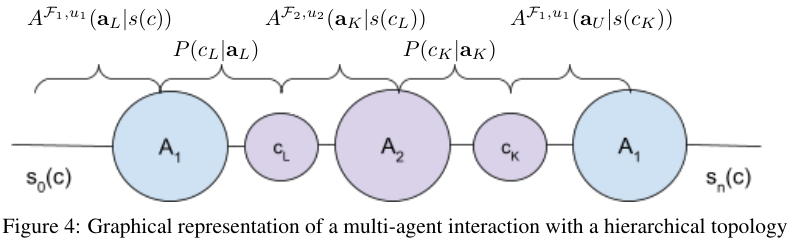
想象一个分层级的任务处理流程。智能体1(比如是一个项目经理)并不直接写代码,它的动作是生成一个指令给智能体2(程序员)。这个指令构成了智能体2的上下文。
如果智能体2发现指令模糊不清,它不会像单体智能体那样强行瞎猜(这会导致概率崩塌),而是会反馈一个上下文给智能体1。这个过程可以循环往复。
在这个交互图中,紫色的连接部分P(cL|aL)和P(cK|aK)是这一架构的灵魂。它们代表了智能体之间的沟通质量。
这种沟通本质上是一种无需人工干预的提示词工程自动化。智能体1在不断尝试修改给智能体2的Prompt,直到智能体2的成功率达到阈值。
我们常说的谈判或协作,在数学上就是对这两个概率项的优化搜索。
通过允许多次交互,系统探索了动作空间中那些隐藏的路径,找到了一条在静态视角下看不见的成功捷径。
这种搜索能力赋予了系统极强的鲁棒性。
即使面对未曾见过的任务,只要智能体之间能够通过沟通对齐认知,它们就有可能动态构造出解法。
这也是为什么智能体-to-智能体 Protocol (A2A) 这样的协议标准变得如此重要,因为它们规范了这种概率交换的通道。
并不是只有收益:协作的代价
天下没有免费的午餐,概率的提升是以资源消耗为代价的。
多智能体系统虽然能显著提高复杂任务的成功率,但如果不加节制地引入协作,会导致严重的效率问题。
每一次智能体之间的握手、谈判,都意味着网络延迟、Token消耗和计算成本的增加。
因此,Google的团队提出了一个修正后的目标函数。
我们不能仅仅追求成功率的最大化,必须同时考虑协作成本(Collaboration Costs)。
新的目标函数引入了一个正则化项:
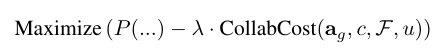
这里的CollabCost代表了包括延迟、Token费用、系统复杂度在内的综合成本,而λ是一个超参数,用来调节我们对成本的敏感度。
这个公式是工程实践的指导原则。它提醒设计者,在追求高智能的同时,必须对系统的啰嗦程度进行惩罚。
如果一个简单的任务可以通过单体ReAct快速解决,系统就不应该启动复杂的多智能体谈判流程。
优秀的智能体架构应当具备自适应能力,根据任务的难度动态调整λ的权重,或者在设计阶段就根据应用场景权衡好这个天平。
这实际上是在寻找高概率与高效率之间的甜点。
一个设计精良的系统,应该是在保证任务完成率可接受的前提下,尽可能减少不必要的智能体交互。
长期以来,智能体开发严重依赖开发者的直觉和反复调试。我们知道Model Context Protocol (MCP) 好用,知道CoT(思维链)能提升逻辑,但这些知识点是零散的。
Google Cloud AI的这篇论文将这些散落的珍珠串成了一条项链。
通过引入概率链、自由度、协作概率和协作成本这些概念,他们为智能体设计搭建了一套严密的逻辑大厦。
它为未来的自动化设计指明了方向。
既然智能体的运作可以被量化为数学公式,那么我们完全可以设计出算法,自动搜索最优的智能体拓扑结构,自动平衡成功率与成本,甚至让智能体在运行时自我进化。
参考资料:
https://arxiv.org/pdf/2512.04469

















 831
831

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









