



Meta AI发布了名为Omnilingual ASR(自动语音识别),它能转录超过1600种人类语言。

这其中,有500多种语言是历史上第一次被人工智能系统所理解和记录。
语言,是文化的载体,也是沟通的桥梁。
但在数字世界里,这座桥梁长期以来只为少数强势语言而架设。
全球七千多种语言中,只有极少数能够被计算机处理,绝大多数语言和其背后的文化,都沉默在技术的阴影之下。
自动语音识别(ASR)技术,这个旨在将声音转化为文字的工具,本应打破这种沉默,却因其对海量标注数据的依赖,反而加固了这道鸿沟。
近些年,多语言ASR的探索开始出现曙光。
Facebook的wav2vec 2.0利用自监督学习,让模型能从无标签的音频中自学语音的奥秘。
Google的USM(通用语音模型)更是将支持的语言数量推向了100种以上,一度成为该领域的标杆。
但这些系统,依然没能解决根本问题。
它们的语言覆盖范围相对于全球语言的多样性,仍是沧海一粟。
更关键的是,它们的扩展性极差,增加一种新语言,几乎等同于一次新的大型工程,需要数据专家和庞大的计算资源深度介入,普通社区用户根本无从参与。
对于数据稀缺的语言,超过30%的字符错误率(Character Error Rate, CER)更是常态,几乎不具备实用价值。
Omnilingual ASR的出现,宣告了一个新时代的到来。
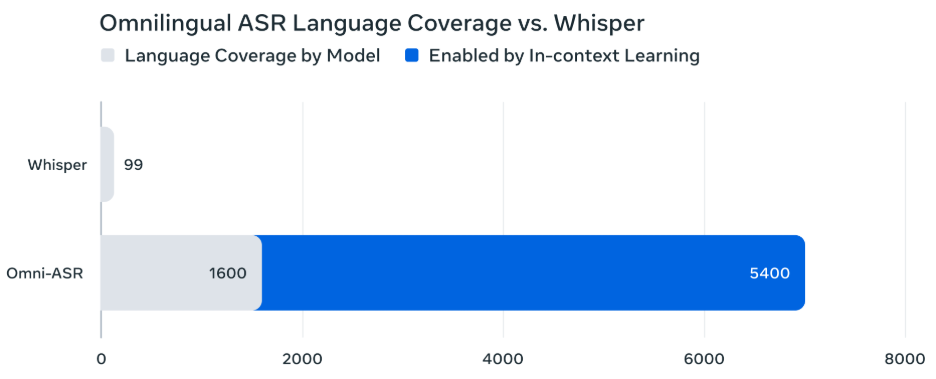
它不再是简单地增加支持语言的数量,而是从根本上改变了多语言ASR的构建范式。
它让语言的扩展,从一个需要巨大投入的中心化工程,变成了一个社区可以驱动、持续生长的生态系统。
一个模型,倾听世界千语
Omnilingual ASR的架构拥有一双能听懂世界所有声音元音的耳朵,和一个能根据上下文灵活拼写出任何语言的大脑。
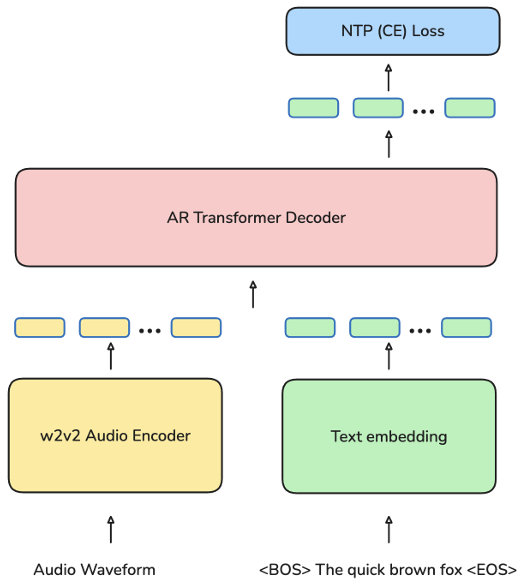
这双耳朵,就是它的编码器(Encoder)。
这个编码器基于Meta AI自家的wav2vec 2.0模型,但被前所未有地扩展到了70亿参数的庞大规模。
wav2vec 2.0的核心思想是自监督学习,它并不需要人类告诉它哪个音节对应哪个文字。
相反,它通过聆听海量的、未被标注的原始音频,自己去发现声音中潜在的结构和规律。
这好比一个婴儿,在学会说话之前,通过不断地听周围人讲话,逐渐形成了对语音最基本的感知。
Omnilingual ASR的编码器,就是在430万小时的音频海洋中进行这种聆听,其中包含了1239种不同语言的声音。
这使得它对人类语音的声学共性,有了极为深刻的理解。
这颗大脑,就是它的解码器(Decoder)。
Omnilingual ASR提供了两种解码器方案,以适应不同场景的需求。
一种是CTC(联结主义时间分类)解码器,它结构简单,在编码器之上叠加一个线性层,追求极致的推理速度,非常适合需要实时转录的场景。
根据官方报告,一个3亿参数的CTC模型在A100上处理30秒的音频,其实时因子低至0.001,快到几乎没有延迟。
另一种,则是这次技术革命的核心,一个LLM(大语言模型)风格的解码器。
它采用类似GPT的Transformer架构,逐个字符地生成文本。它不像CTC那样直接吐出结果,而是像一个作家一样,会根据已经写出的部分,去思考下一个最合适的字符是什么。
这种基于上下文的生成方式,赋予了它惊人的灵活性和准确性,尤其是在处理语法结构复杂或低资源语言时,表现远超CTC。
将强大的耳朵和智慧的大脑结合,Omnilingual ASR便拥有了理解多种语言的基础。
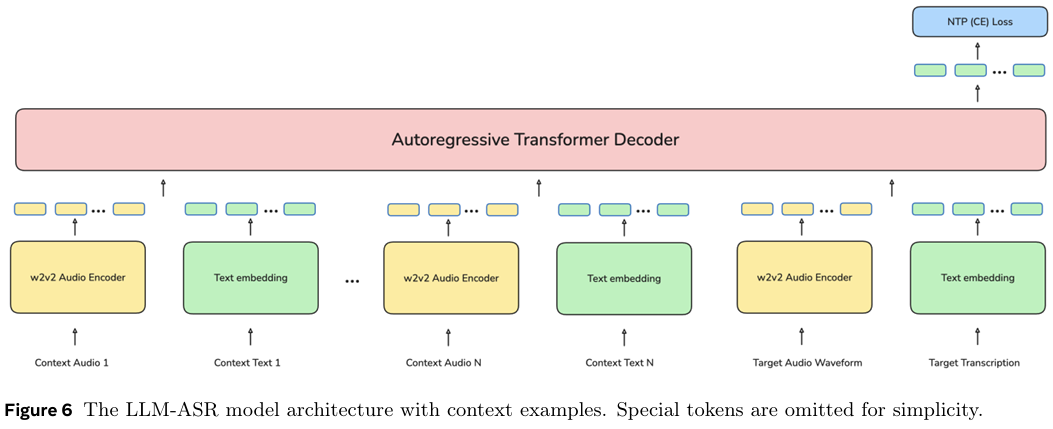
但真正让它实现对1600多种,乃至理论上5400多种语言支持的,是零样本上下文学习机制。
传统模型要学会一门新语言,必须用该语言的数据进行再训练,调整内部的亿万个参数。
而Omnilingual ASR的LLM解码器模型,完全不需要这个过程。你只需要给它提供几个范例,即几对该新语言的音频-文本样本。
在推理时,系统会进行这样的操作:将这些范例和你真正想要转录的目标音频,像穿糖葫芦一样串在一起,然后一同输入给解码器。
解码器在处理前面的范例时,会迅速领悟到这门新语言的声音和文字之间的对应关系,然后利用这种新学到的知识,高质量地转录出最后的目标音频。
整个过程,模型的权重参数没有一丝一毫的改变。
为了让这个参考过程更高效,系统还引入了一个名为SONAR的多语言多模态编码器。
它能将音频和文本都映射到一个共享的向量空间里。
当你输入一段目标音频时,SONAR会迅速在样本库中,找到与之在声音和语义上最相似的几个范例。这种智能检索,相比随机挑选范例,能将转录的准确率提升15%到20%。
仅仅需要3到5对样本,Omnilingual ASR就能对一门全新的、从未见过的语言,达到可用的转录质量。
这彻底拆除了多语言ASR技术扩展的壁垒,让语言的边界,第一次可以由社区和用户自己来定义。
数据是文化的火种
巧妇难为无米之炊。Omnilingual ASR这座技术大厦的基石,是其前所未有的训练数据集。这个数据集的构建过程,本身就是对过往数据采集模式的一次革新。
其核心是有标签语音数据集AllASR。它整合了海量的开源数据、内部语料、合作伙伴授权数据,以及专门委托采集的数据,总时长达到了惊人的120,710小时,覆盖1,690种语言。
这个规模,已经超越了以往任何一个公开的ASR数据集。
比规模更重要的,是其对待低资源语言的方式。Meta AI专门发起并构建了一个名为Omnilingual ASR Corpus的语料库,专注于那些最被忽视的语言。
团队没有采用互联网上常见的抓取模式,因为那种方式只会不断复制强势语言。
他们选择与非洲、南亚等地的本地组织合作,直接走进语言社区。
他们招募母语者作为贡献者,并为他们的劳动支付报酬。
采集方式也并非让人们朗读固定的、翻译过来的句子,而是通过开放式的提示,鼓励他们用最自然的方式进行独白,讲述自己的故事、生活和文化。
这样采集到的3,350小时,覆盖348种低资源语言的语音,是鲜活的、自然的、充满文化温度的。
更可贵的是,Meta AI将这个Omnilingual ASR Corpus以CC-BY-4.0许可协议完全开放,任何人都可以通过Hugging Face获取。
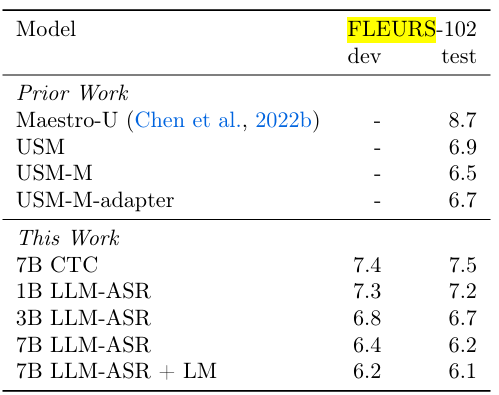
Omnilingual ASR在各项基准测试中,都展现了与它宏大愿景相匹配的硬实力。
评估ASR性能的核心指标是字符错误率(CER),这个数字越低,代表转录的准确性越高。
根据Meta AI的官方报告,其最强大的omniASR_LLM_7B模型,在超过1600种语言上都达到了当前最先进(SOTA)的水平。

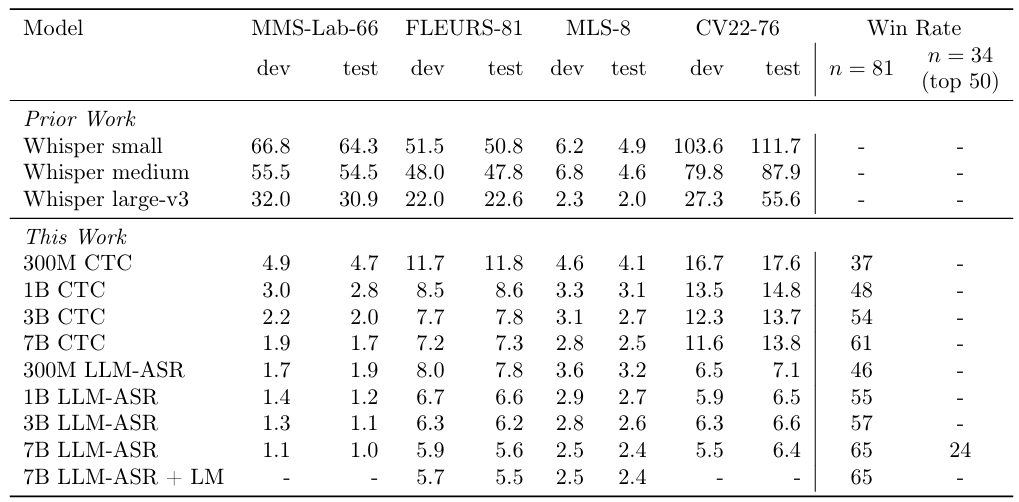
在公开的多语言基准测试FLEURS 102上,Omnilingual ASR与Google的USM等顶级模型进行了正面比较。
Omnilingual ASR的核心创新,并非仅仅是参数量或数据量的堆砌,而在于范式上的突破。
它的可扩展性是革命性的。USM和Whisper都只支持一个固定的语言集合,无法由用户自行扩展。
而Omnilingual ASR通过上下文学习,理论上可以支持任何有少量样本的语言,将上限提升到了5400种以上。
它将扩展新语言的门槛,从需要顶尖AI专家的复杂工程,降低到了普通社区成员只需要提供几段录音和文本就能完成的任务。
它的开放性是最彻底的。
模型、数据、代码全部开源,遵循非常宽松的许可协议。
这构建了一个开放的生态,邀请全世界的研究者、开发者和语言社区,共同来丰富人类的数字声音世界。
各种地方方言,少样本即可迁移。
参考资料:
https://ai.meta.com/blog/omnilingual-asr-advancing-automatic-speech-recognition/
https://github.com/facebookresearch/omnilingual-asr
https://huggingface.co/datasets/facebook/omnilingual-asr-corpus
https://ai.meta.com/research/publications/omnilingual-asr-open-source-multilingual-speech-recognition-for-1600-languages/
END

















 1171
1171

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









