



大模型无需任何额外训练,仅靠策略性权重调整便在伯克利函数调用榜单上实现了 2.7% 的性能跃升。

大语言模型训练资源与时间消耗极大,从数千张 GPU 的算力堆叠到漫长的数据清洗与对齐,每一个百分点的性能提升往往伴随着高昂的边际成本,这种现状迫使研究界寻找更高效的性能提升路径,模型汤 (Model Souping) 技术应运而生。
模型汤主张对同一架构下的多个微调模型权重进行平均,以此在不增加推理成本的前提下提升泛化能力。
然而早期的模型汤研究多采用均匀平均策略,也就是简单粗暴地将所有模型权重相加后除以模型数量,这种做法隐含了一个错误的假设:所有模型在所有任务上的贡献是等价的。
Meta SuperIntelligence Labs (Meta 超级智能实验室)、FAIR at Meta 以及伦敦大学学院的研究团队打破了这一假设。
他们提出的 SoCE (Soup of Category Experts,类别专家模型汤) 方法,将基准测试中的类别表现拆解,利用统计学中的相关性分析,精准识别各领域的专家模型,再通过非均匀加权将它们融合,这种方法将模型优化从炼丹变成了精准的配方化学。
SoCE 的成功建立在一个关键洞察之上:基准测试的性能并非铁板一块,不同类别的性能表现呈现出显著的异质性,模型 A 可能精通多轮对话,但在无关性检测上表现平平,而模型 B 可能恰好相反。
研究人员以伯克利函数调用排行榜 (BFCL) 为试验田,深入剖析了模型在不同子任务上的表现,他们计算了模型在 Java、Javascript、多轮对话、实时准确率等不同类别下的皮尔逊相关系数。
数据揭示了一个有趣的现象:某些任务之间存在极强的正相关性,例如各类多轮对话任务之间的相关系数高达 0.96 至 0.98。
这意味着一个擅长处理长上下文多轮对话的模型,通常也能很好地处理其他类型的多轮交互,这符合直觉,因为它们调用的底层能力是相似的。
另一面的数据更具价值,在多轮基础 (Multi-turn base) 与实时准确率 (Live Accuracy) 这两个类别之间,相关系数骤降至 0.07。
这个接近于零的数字表明,这两类任务代表了截然不同的能力域,一个在标准化测试中表现优异的模型,在面对用户真实场景下的 Prompt (提示词) 时,未必能保持同样的高水准。
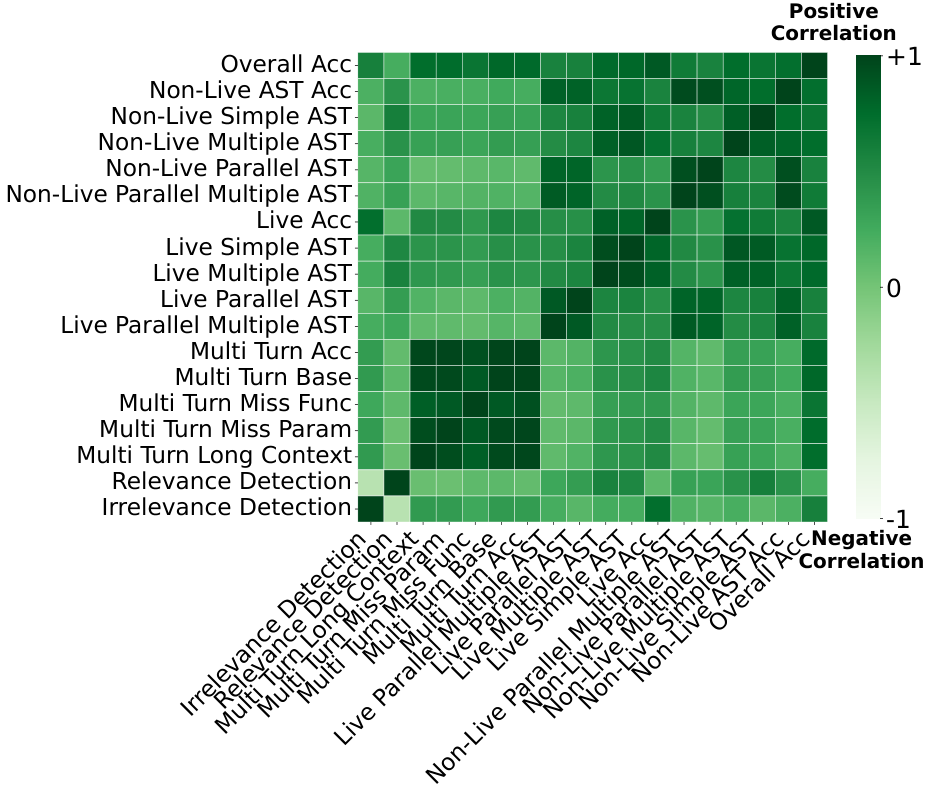
上图清晰地展示了这种相关性差异,深绿色区域代表强正相关,意味着能力高度重叠;浅绿色区域代表弱相关,意味着能力互补。
SoCE 的策略正是基于此图谱:在强相关区域中只选最强者,避免冗余;在弱相关区域中引入互补者,填补短板。
传统均匀融合就像是将果汁、牛奶和咖啡不分比例地倒在一起,结果往往平庸甚至难喝;SoCE 则像是一位精明的调酒师,它清楚每种基酒的特性,只选择口味互补的成分,并精确控制每一滴的比例。
这一过程被严谨地形式化为四个算法步骤。
第一步是全景扫描,算法计算所有候选模型在基准测试各类别对之间的皮尔逊相关系数,设定一个阈值,专门筛选那些相关性低于该阈值的类别组合,这一步排除了同质化竞争,锁定了互补潜力。
第二步是专家选拔,针对每一个被识别出的低相关类别,系统不再雨露均沾,而是根据性能排名,挑选出该领域的绝对统治者,如果模型 A 在数学任务上排名第一,它就是数学专家;如果模型 B 在代码任务上领先,它就是代码专家,只有真正的专家才有资格进入融合池。
第三步是权重寻优,这是 SoCE 与传统方法的分水岭,系统不再默认 1:1 的比例,而是在权重空间内进行网格搜索,权重的生成遵循归一化原则,总和为 1,搜索步长设定为 0.1,范围覆盖 0.1 到 0.9。
算法遍历所有可能的权重组合,计算加权后的模型在验证集上的综合得分,这个过程本质上是在寻找一个最优向量 ,它能最大化地保留各专家的长处,同时通过加权平均稀释掉各自的短板。
第四步是算术融合,当最优权重向量和专家名单确定后,最后一步仅仅是简单的线性代数运算,没有反向传播,没有梯度下降,几秒钟的加权相加,一个新的 SOTA (State-of-the-Art,最先进) 模型就此诞生。

实验结果是对这一简单逻辑最有力的背书,在竞争激烈的伯克利函数调用排行榜 (BFCL) 上,SoCE 展现了统治力。
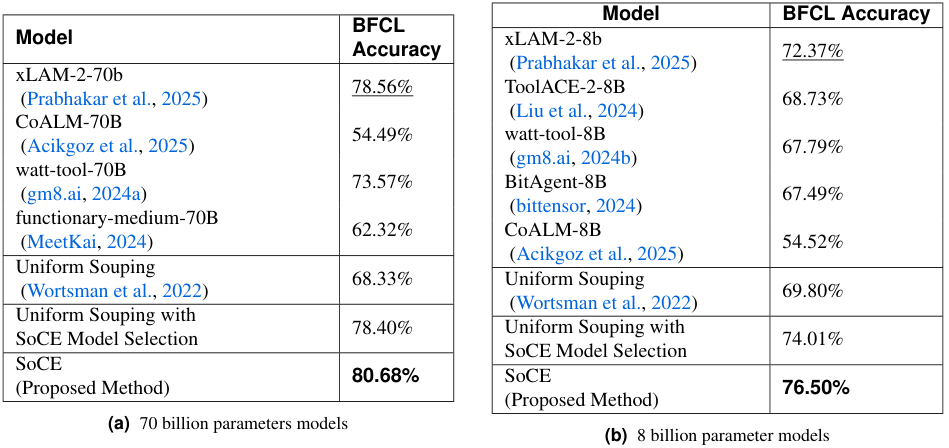
针对 700 亿 (70B) 参数的稠密模型,研究团队选择了 xLAM-2-70b-fc-r、CoALM-70B、watt-tool-70B 和 functionary-medium-70B 作为候选池,这些模型本身已是行业翘楚。
传统的均匀融合将这些模型混合后,准确率仅为 68.33%,这比最强单体模型低了整整 10 个百分点,这一数据残酷地证明了盲目平均的危害:平庸的模型权重稀释了专家模型的锋芒,导致整体智商下降。
引入 SoCE 的模型选择策略但仍保持均匀权重,准确率回升至 78.40%,这证明了剔除差生的重要性,但这还不够。
当 SoCE 的权重优化介入后,准确率跃升至 80.68%,这不仅超越了所有单体模型,也确立了该榜单的新纪录,相比 xLAM-2-70b-fc-r 提升了 2.7%,考虑到大模型在 SOTA 水平上的每一点进步都异常艰难,2.7% 的提升堪称显著。
最终的最优权重配置揭示了融合的秘密:xLAM 获得了 0.5 的权重,watt-tool 获得了 0.3,CoALM 获得了 0.2,这是一个经过精确计算的平衡,既保留了 xLAM 的通用优势,又吸收了 watt-tool 和 CoALM 在特定领域的特长。
这一规律在 80 亿 (8B) 参数的小模型上同样适用,SoCE 达到了 76.50% 的准确率,将原本的 SOTA 纪录 (72.37%) 大幅提升了 5.7%,对于资源受限的端侧模型而言,这种无需增加推理算力的性能提升极具诱惑力。
除了 BFCL,SoCE 在多语言数学推理 (MGSM) 和长上下文 (∞-Bench) 基准上也验证了其普适性。
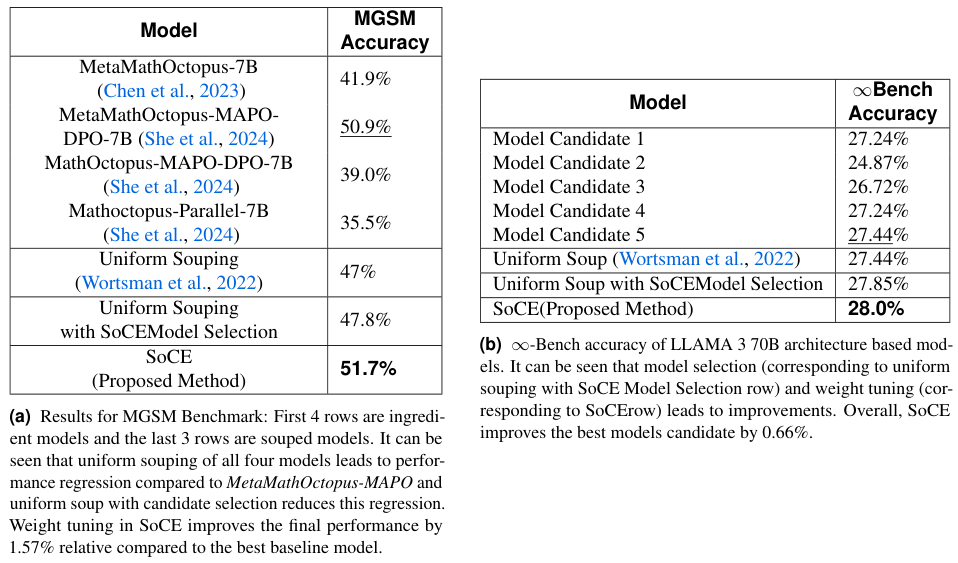
在 MGSM 测试中,简单的均匀融合再次导致了性能倒退,得分为 47%,低于最佳单体模型的 50.9%,SoCE 通过剔除弱相关且表现不佳的模型,并赋予强模型更高权重,将准确率拉升至 51.7%,成功实现了逆势翻盘。
在 ∞-Bench 上,尽管模型间的性能差异较小,SoCE 依然以 28.0% 的成绩微弱优势击败了所有对手,这表明即便在提升空间有限的场景下,精细的权重调整依然能榨取出最后一滴性能。
数据背后隐藏着更深层的变化:模型一致性的提升。
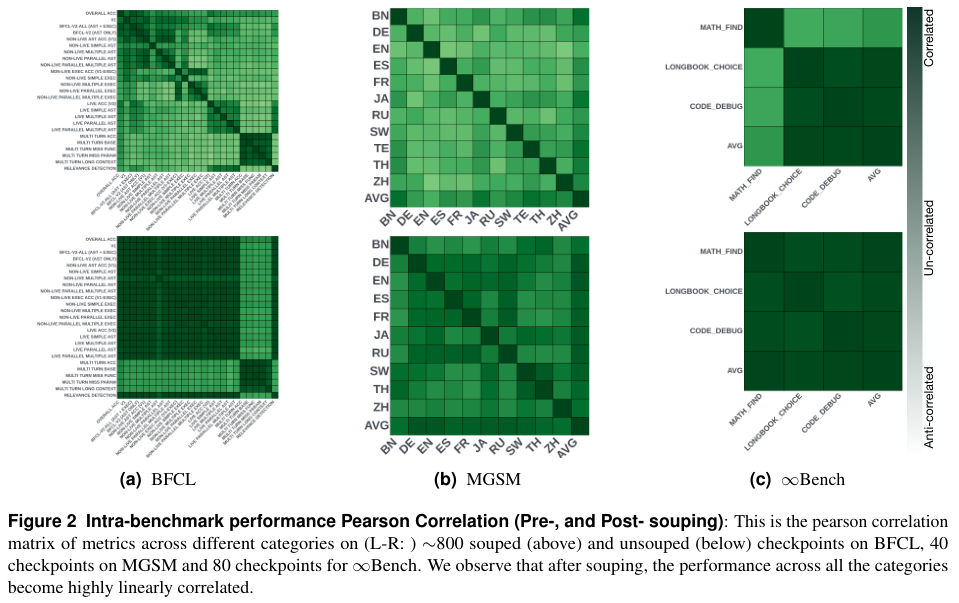
对比融合前后的皮尔逊相关矩阵,我们可以清晰地看到,融合后的模型 (Post-souping) 在不同类别间的颜色分布更加均匀,表现出更强的线性相关性。
这说明 SoCE 并非简单地拼接能力,而是促进了模型能力的内在整合,减少了偏科现象,一个在某一方面表现优异的模型,在其他方面也变得更加可靠。
为了解释这种效果并非运气,研究人员引入了博弈论中的夏普利值 (Shapley Value) 进行理论归因。
夏普利值用于衡量合作博弈中每个参与者对整体收益的边际贡献,在这里,模型是参与者,融合后的性能是收益。
分析结果显示,模型对最终性能的贡献是极不均匀的,在 MGSM 的实验中,专家模型 M1 和 M2 因为在低相关类别 (如西班牙语到英语、中文到英语) 上表现出极强的互补性,它们的夏普利值遥遥领先,构成了最佳搭档。
相反,弱模型 M4 的加入不仅贡献微薄,甚至在某些组合中拖累了平均分,其夏普利值为负或接近于零。
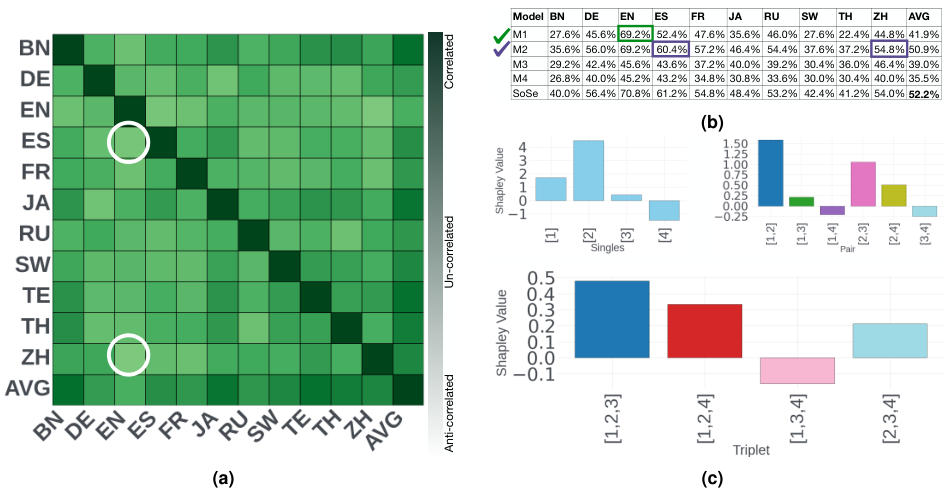
上图直观地展示了这一点,SoCE 选定的候选模型组合在夏普利值图表中占据了绝对主导地位,这从数学原理上证明了 SoCE 的筛选机制符合合作博弈的最优解:它总是倾向于选择那些能带来最大边际增益的队友。
SoCE 的出现打破了只有更强算力才能带来更强模型的迷思,它证明了现有的开源模型仓库中蕴藏着巨大的未被挖掘的价值。
在多任务学习领域,这意味着我们可以将针对特定语言微调的模型与针对特定代码微调的模型进行算术融合,直接获得一个既懂语言又懂代码的复合模型,而无需重新进行昂贵的多任务混合训练。
在数据隐私领域,这提供了一种绝佳的解决方案,不同机构可以在各自的私有数据上微调模型,然后仅交换模型权重进行融合,在不泄露原始数据的前提下共享能力。
随着前沿大模型的训练门槛不断提高,学术界和中小型开发者在算力上的劣势日益明显,SoCE 提供了一条低成本的突围之路,利用现有的 Llama 衍生模型家族 (目前已接近 15 万个),通过巧妙的组合与计算,构建出性能足以匹敌甚至超越单一闭源大模型的系统。
当然,SoCE 并非万能药,它依赖于基准测试具有清晰的子类别划分,以便进行相关性分析,对于那些混沌未分的任务,前提条件便不复存在。
目前的实验主要集中在同一预训练基座 (如 Llama 3) 的对齐模型上,不同架构或不同预训练起点的模型能否通过这种方式融合,仍是一个未解之谜。
随着融合模型数量的增加,边际收益递减的缩放定律 (Scaling Laws) 依然存在,到底融合多少个模型是性价比的拐点,需要更多的实证研究。
参考资料:
https://arxiv.org/abs/2511.13254
https://github.com/facebookresearch/llm_souping
END

















 374
374

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









