



Andrej Karpathy(安德烈·卡帕西)用一百美元和大约八千行代码,做出了一个迷你版的ChatGPT。
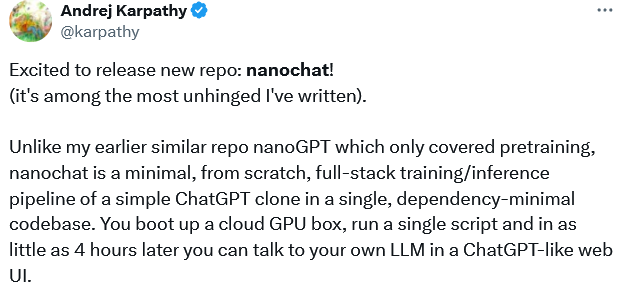
训练这个迷你版ChatGPT的项目也开源了,名叫nanochat,它把训练一个大语言模型的所有环节,从头到尾,浓缩在了一个任何人都能跑起来的代码库里。卡帕西说,这是“一百美元能买到的最好的ChatGPT”。
项目一发布,星标4k+,一觉醒来已经10k。
卡帕西这个人不简单
卡帕西的履历,就是一部浓缩的深度学习发展史。
他在多伦多大学读本科的时候,选了计算机科学和物理,还辅修了数学。也正是在那儿,他第一次撞见了深度学习,钻进了杰弗里·辛顿的课堂和研究小组。
后来他去不列颠哥伦比亚大学读硕士,研究怎么让物理模拟出来的小人自己学会控制身体。这听起来有点像游戏,但背后是严肃的强化学习问题。
真正让他声名鹊起的,是他在斯坦福大学读博的经历。他的导师,是计算机视觉领域大名鼎鼎的李飞飞。那个时候,李飞飞正因为ImageNet项目而备受瞩目,这个项目用海量标注的图片,直接引爆了深度学习在图像识别领域的革命。
卡帕西的博士论文题目是《连接图像与自然语言》,干的就是让机器既能看懂图片,又能用人的语言描述出来。这个方向,在今天就是多模态大模型的核心议题之一。
他创立并主讲了斯坦福第一门深度学习课程,代号CS231n,全称是《卷积神经网络与视觉识别》。这门课有多火?一开始一百五十个学生,两年后暴涨到七百五十人。
他甚至把课程的全部资料,包括讲义、笔记、代码,都放到了网上,完全免费。这一下就成了全球AI学习者的“圣经”之一,无数人靠着这份公开课资料,敲开了深度学习的大门。直到今天,CS231n依然是这个领域最经典的入门课程。
卡帕西不仅自己懂,还特别热衷于把复杂的东西讲明白,让更多人懂。
博士毕业后,他的第一站是OpenAI,当时这家公司刚刚成立,卡帕西是创始成员和研究科学家。他在那里继续做深度学习和计算机视觉的研究。
两年后,马斯克把他挖到了特斯拉,担任人工智能和Autopilot视觉总监,直接向马斯克汇报。他要领导一个团队,负责特斯拉自动驾驶系统里最核心的计算机视觉技术,从数据标注、模型训练到最终部署到数百万辆特斯拉汽车上。他们要面对的,是真实世界里无穷无尽的复杂路况。卡帕西在特斯拉的工作,是把AI技术从实验室推向大规模商业应用的最前线。
后来又回到OpenAI,组建小团队完成GPT-4。
离开大公司后,24年7月,他宣布成立自己的AI教育公司,叫Eureka Labs。他说,他想做一所“AI原生”学校。
他设想的学习场景是这样的:你想学物理,可以直接跟着物理学家费曼学习,每一步都有费曼亲自指导。这种一对一的大师课,在现实世界里是天方夜谭。
但现在有了生成式AI,这事儿就有了可能。在Eureka Labs的构想里,课程还是由人类教师来设计,但教学过程由AI助教来辅助和放大。AI可以不知疲倦地陪伴每个学生,提供个性化的辅导。这样一来,教育的广度和深度都能得到极大的拓展。
Eureka Labs的第一个产品,是一门叫做LLM101n的本科级别课程,目标就是指导学生从零开始,训练一个属于自己的AI。而nanochat项目,正是这门课程的压轴大戏,是整个课程的“毕业项目”。
可以说,从斯坦福的CS231n,到个人YouTube频道的AI讲座,再到现在的Eureka Labs和nanochat,卡帕西始终在扮演一个AI教育者的角色。他不仅是站在技术前沿的实践者,更是那个热衷于为后来人铺路、画图的人。
他用一百美元做了个ChatGPT
nanochat这个项目,是一个完整的、全栈式的解决方案。它包含了训练一个聊天机器人所需要的一切:分词器训练、模型预训练、监督微调、强化学习对齐、模型推理,甚至还有一个网页交互界面。所有这些,都打包在了大约八千行代码里。
卡帕西做这个项目的目的不是要挑战GPT-4,而是要建立一个“强基线”的技术栈。就是一个虽然不顶尖,但功能完整、表现稳健、足以作为参考标准的基础版本。
他想把过去几年大模型领域摸索出来的所有关键技术,用最简洁、最易读、最容易修改的方式整合在一起。
他希望这个项目能像一张清晰的地图,让学习者可以顺着它走一遍,亲手体验和理解一个大语言模型是如何从一堆原始文本数据,一步步变成一个能与人对话的AI的。
这个项目最大的亮点就是成本控制。
卡帕西把训练分成了几个档位,就像游戏里的不同难度。
最低的一档,一百美元。你可以在一个拥有八块H100显卡的服务器节点上,花大约四个小时,跑完整个流程。最终得到的模型,虽然不能解决复杂的数理问题,但已经可以进行基础的对话,能写写小故事、小诗歌,回答一些简单的问题。
如果你愿意把预算提高到三百美元,训练大约十二个小时。得到的模型在一个叫做CORE的综合评分基准上,表现就能超过OpenAI早期的GPT-2模型。
再加码到一千美元,训练四十多个小时。模型的能力就会有显著提升,可以解决一些简单的数学和代码问题,还能做选择题。
要知道,训练GPT-3这种级别的大模型,成本是以百万甚至千万美元计算的。卡帕西通过简化和优化,硬是把门槛从珠穆朗玛峰拉到了普通人也能爬的小山坡。
这对于AI领域的教育和研究意义重大。
过去,只有少数大公司有财力玩大模型游戏。其他人只能使用这些公司提供的API,模型内部的运作机制完全是个黑箱。而nanochat把整个黑箱砸开了,让预算有限的学生、研究者和独立开发者,也能亲手搭建和训练自己的模型,进行各种实验和改进。
这八千行代码里全是细节
nanochat的魅力在于它的“麻雀虽小,五脏俱全”。我们来拆解一下这八千行代码,看看卡帕西是如何把复杂的流程变得如此紧凑和高效的。
整个项目主要用Python语言和PyTorch框架编写,只有一小部分负责训练分词器的代码因为性能要求,用了Rust语言。卡帕西提供了一个叫speedrun.sh的脚本,只要环境配置好,一键下去,就能在单个8×H100的节点上,从零开始跑通全流程。
第一步,是训练分词器(Tokenizer)。
分词器是大语言模型的嘴巴和耳朵,负责把人类的文字语言,转换成模型能够理解的数字序列(tokens),再把模型输出的数字序列,翻译回人类的语言。它的好坏直接影响模型的效率和性能。
卡帕西没有直接用现成的分词器,比如Hugging Face上那些。他觉得那些要么太慢(纯Python实现),要么太臃肿复杂。为了保持nanochat的极简风格,他自己动手用Rust实现了一个。
这个分词器的训练算法和OpenAI用在GPT系列上的是一样的,都是字节对编码(BPE)。简单说,就是先在海量文本里,找到最高频出现的字节对,把它们合并成一个新的、更长的token,然后不断重复这个过程。这样就能用一个相对较小的词汇表,来高效地表示各种复杂的词汇和句子。
nanochat的词汇表大小默认是65536个。卡帕西用了20亿字符的文本数据来训练它,整个过程只需要一分钟左右。训练出来的分词器,平均能把4.8个英文字符压缩成一个token,这个压缩比相当不错。和GPT-2相比,全面占优。和GPT-4比,虽然在多语言处理上因为词汇量小而吃亏,但在专门的英文网页数据集(FineWeb)上,甚至还略胜一筹,因为它就是用这个数据集训练的。
第二步,是预训练(Pre-training)。
这是整个流程里最耗费计算资源的一步,也是模型学习通用知识的关键。预训练的任务很简单,就是“猜下一个词”。给模型一段来自互联网的文本,比如“今天天气很好,适合出去”,然后让它预测下一个词是什么,最可能的是“散步”。如果模型猜对了,就给它一点奖励,如果猜错了,就调整内部参数,让它下次猜得更准一些。
通过在海量文本上日以继夜地做这种填空游戏,模型会慢慢地学会语法、事实、逻辑、常识,甚至某种程度上的推理能力。它把整个互联网的知识,都压缩进了自己庞大的参数网络里。
nanochat使用的预训练数据,是经过精心清洗和去重的英文网页数据集FineWeb-EDU。卡帕西打包了一个一百亿token的版本。整个预训练过程,在一个8卡的GPU节点上,通过一个脚本就能启动。
模型架构上,nanochat参考了Llama,但做了很多简化。默认训练的是一个拥有20层Transformer结构、大约5.6亿参数的模型。
整个预训练过程,就像用巨大的算力,把海量的知识,慢慢地“熬”进模型里。
第三步,是中期训练(Midtrain)和监督微调(SFT)。
预训练出来的模型,我们称之为“基础模型”(Base Model)。它知识渊博,但不太会“聊天”。你跟它说话,它可能会续写你的话,而不是回答你的问题。因为它只学会了“接龙”,还没学会“对话”。
所以需要后续的微调步骤来“教”它如何成为一个聊天机器人。
中期训练,是在一个叫做smol-SmolTalk的合成对话数据集上进行的。这个阶段的目的有几个:
-
让模型学会对话的格式。比如,人类用户说的话前面要加什么标记,AI助手的回答前面要加什么标记。这些特殊的标记,在预训练阶段是没有的。
-
让模型适应对话的数据分布。聊天记录的语言风格,和互联网上的百科文章、新闻报道是很不一样的。
-
教模型一些基础技能。比如做选择题。卡帕西发现,小规模的模型很难从互联网的汪洋大海里自发学会做选择题,所以他特意混入了一些MMLU(一个大规模多任务语言理解基准)的选择题数据来训练它。
-
教模型使用工具,比如调用Python解释器来解决计算问题。
中期训练之后,是监督微调(SFT)。
这一步会用质量更高、更精挑细选的对话数据,对模型进行最后一轮打磨。理想情况下,安全训练也应该在这一步进行,教会模型拒绝回答有害问题。SFT阶段会让模型的回答风格更符合人类的偏好。
第四步,是强化学习(RL)。
如果说SFT是教模型模仿“好学生”的对话范例,那么强化学习就是让模型在实践中自己摸索,怎么回答能得到更高的“分数”。
nanochat使用了一种叫做GRPO(Group Relative Policy Optimization)的强化学习算法。
具体流程是这样的:从一个问题集里(比如小学数学题GSM8K),让模型对同一个问题生成多个不同的答案。然后用一个奖励模型(或者简单的规则,比如数学题就看答案对不对)给这些答案打分。最后,让模型多学习那些得了高分的答案,少学习那些得了低分的答案。
通过这样一轮轮的“试错-反馈-学习”,模型在特定任务上的表现会得到进一步提升。卡帕西对这个流程也做了极大的简化,去掉了传统强化学习算法里一些复杂的组件,让它变得更直接、更容易实现。
最后一步,是推理(Inference)和部署。
模型训练好了,就要用起来。nanotochat的推理引擎实现得很高效,支持KV缓存(一种加速生成速度的技术),支持工具使用(比如在一个沙箱环境里运行Python代码)。
用户可以通过两种方式和模型互动。一种是简单的命令行界面(CLI),在终端里直接对话。另一种是一个基于FastAPI框架搭建的网页界面,体验和ChatGPT非常相似。你可以在网页上和它聊天,让它写诗,让它讲故事。
至此,从一堆原始文本,到一个可以交互的聊天机器人,整个流程就完整地走完了。卡帕西把所有这些步骤都无缝地衔接在了一起,并用清晰的代码呈现了出来。
人人都能“毕业”的大模型项目
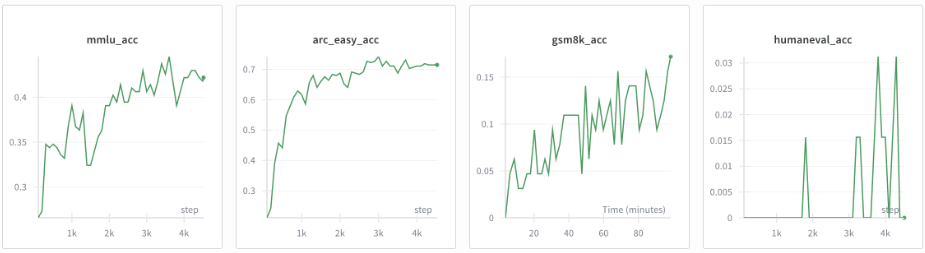
nanochat提供了一套完整的评估体系,跑完训练后会自动生成一份Markdown格式的“成绩单”,把模型在各个基准测试上的表现都列出来。
其中最核心的指标叫CORE。这是一个综合性的基准,包含了22个不同的自动补全任务,比如常识问答、阅读理解、逻辑推理等,可以很全面地衡量一个基础模型的综合能力。
结果怎么样呢?
100美元、训练4小时的默认版nanochat,在CORE分数上可以拿到0.22分。
300美元、训练12小时的版本,CORE分数可以超过0.26分。这个分数已经略高于OpenAI发布的GPT-2(XL)版本,那是一个拥有15亿参数的模型。nanochat用更少的参数和极低的成本,达到了甚至超过了前代经典模型的水平。
除了CORE分数,成绩单上还有其他几个重要指标:
-
MMLU:这是一个涵盖了五十七个不同学科的大规模多任务语言理解基准,用来测试模型的知识广度。
-
GSM8K:小学水平的数学应用题,测试模型的数学推理和计算能力。
-
HumanEval:Python编程题,测试模型的代码生成能力。
-
ARC-Easy/Challenge:科学常识问答题,测试模型的世界知识。
一个训练了24小时、成本约600美元、拥有30层transformer结构的模型,在MMLU上能拿到40分以上,在ARC-Easy上能拿到70分以上,在GSM8K上也能拿到20分以上。这个成绩对于一个不到十亿参数、完全开源、训练成本如此低廉的模型来说,相当惊人。
nanochat一发布,就在AI社区引发了热烈讨论。
有人开玩笑说:“太酷了!跑一次这个项目,我就敢把‘机器学习工程师’写在简历上了!”
这个项目的核心价值,并不仅仅是做出一个便宜的聊天机器人。
卡帕西坦言,这个项目的代码是他写得最“放飞自我”的作品之一,但结构异常清晰。他几乎是完全手写的,因为他发现现有的代码生成AI助手,比如Claude或者Codex,在这种高度定制化的、偏离了它们训练数据分布的项目上,根本帮不上忙。这八千行代码,是卡帕西本人对LLM技术栈的最佳实践的提炼和展示。
端到端完整性,为学习者提供了一个绝佳的沙盒。你可以任意修改其中的任何一个环节,比如换一个分词算法、调整模型结构、尝试新的微调数据,然后马上就能看到这些改动对最终性能的影响。这让学习和研究的反馈回路变得极短。
作为Eureka Labs课程的“毕业项目”,它完美地诠释了卡帕西的教育理念:通过动手实践,来真正理解复杂系统。它降低了门槛,让AI民主化不再是一句空洞的口号。
卡帕西也承认这个项目还有很多不完善的地方。100美元训练出来的模型,对话能力还处在“幼儿园水平”。强化学习的部分目前还比较粗糙。整个代码库还有大量的优化空间。
他把这些都看作是机会。他希望nanochat能像他之前的nanoGPT项目一样,成为一个社区共同维护和改进的工具框架。他已经搭好了一个坚实的“地基”,上面的建筑可以由社区来添砖加瓦。
100美元,也能敲开通往AGI时代的大门。
轮到你来试试了。
参考资料:
https://github.com/karpathy/nanochat
https://github.com/karpathy/nanochat/discussions/1
https://x.com/karpathy/status/1977755427569111362
https://news.ycombinator.com/item?id=45569350
https://en.wikipedia.org/wiki/Andrej_Karpathy
https://karpathy.ai
https://cs.stanford.edu/people/karpathy
https://x.com/karpathy/status/1813263734707790301
END

















 1418
1418

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









