



当整个AI行业还在为大模型的“暴力美学”欢呼时,NVIDIA却悄悄掀起了一场“静默革命”。就在8月18日,这家芯片巨头发布了Nemotron Nano 2 9B模型——一个仅有90亿参数,却能在边缘设备上实现高精度推理的“小巨人"。更令人震惊的是,这个模型不仅性能媲美大参数量竞品,还带来了一个颠覆性的概念:“思考预算”。
当AI学会“精打细算”:思考预算的诞生
想象一下,你正在和AI客服对话,它不是立刻回答你的问题,而是先“思考”一番。这个思考过程可能是几毫秒,也可能是几秒,取决于问题的复杂程度。现在,NVIDIA给了你一个“遥控器”,可以精确控制AI思考的时间长短——这就是“思考预算”(Thinking Budget)。
NVIDIA官方技术报告显示,这种思考预算机制通过在模型输出中出现<|im_end|>标签后停止思考,直接给出答案。这就像给AI设定了一个“脑力消耗上限”,在不显著影响准确性的前提下,减少不必要的token生成。实测数据显示,这种选择性截断策略能将推理成本降低高达60%。
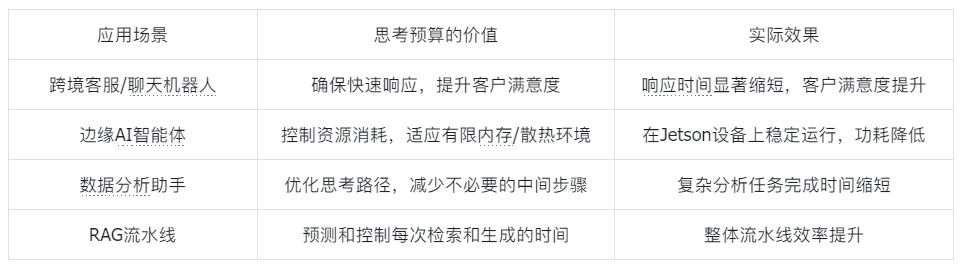
思考预算的实际应用场景
混合架构的“黄金配比”:Transformer与Mamba的完美联姻
Nemotron Nano 2 9B的核心秘密在于其独特的混合架构——将Transformer与Mamba-2巧妙结合。这就像给AI装上了双核大脑:一个负责全局视野,一个专注局部精算。
根据NVIDIA官方技术报告,其技术架构具体参数如下:
-
总层数:62层(压缩后为56层)
-
架构分布:6个自注意力层 + 28个FFN层 + 28个Mamba-2层
-
隐藏维度:5120
-
FFN隐藏维度:20480
-
注意力机制:分组查询注意力(GQA),40个查询头,8个键值头
-
Mamba配置:8组,状态维度128,头维度64,扩展因子2,卷积窗口大小4
这种架构设计的精妙之处在于:大部分层采用Mamba-2选择性状态空间模块,以线性时间运行,每个token保持恒定的内存占用,不会累积增长的KV-cache;而在这些Mamba层之间,穿插着少量的注意力“岛屿”,保留了Transformer在内容驱动的全局跳转方面的优势。
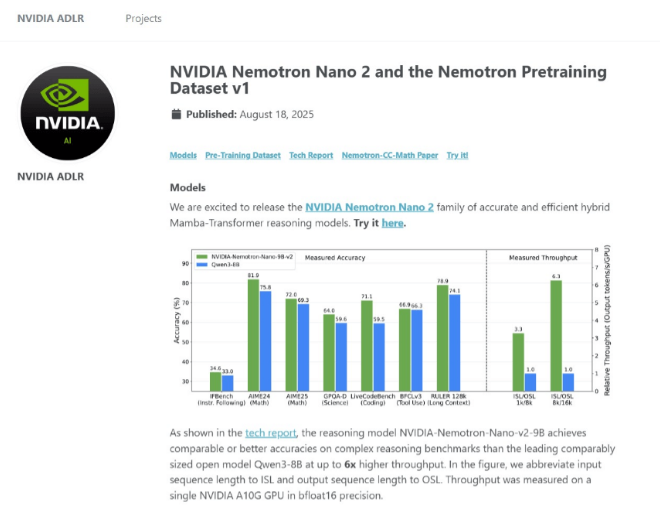
性能对比数据(来自Hugging Face官方模型卡片):

从数据可以看出,Nemotron Nano 2 9B在保持与更大模型相当准确率的同时,实现了高达6.3倍的吞吐量提升,这得益于其混合架构的精妙设计。
从12B到9B:模型压缩的“瘦身艺术”
Nemotron Nano 2 9B的诞生过程本身就是一部瘦身史诗。它从一个12B参数的基础模型(NVIDIA-Nemotron-Nano-12B-v2-Base)开始,经过一系列复杂的压缩和蒸馏过程,最终瘦身为9B参数版本。
压缩过程的技术细节:
-
神经架构搜索(NAS):扩展Minitron模型压缩框架,在内存预算内寻找最佳架构
-
组合剪枝:同时优化多个维度:
深度:从62层减少到56层
嵌入通道:优化通道数量
FFN维度:调整前馈网络维度
Mamba头部:优化Mamba层的头部配置
-
知识蒸馏:使用基于logits的知识蒸馏技术,以原始12B模型为"教师",恢复剪枝过程中损失的性能
整个压缩过程的目标是让模型能够在NVIDIA A10G GPU(22 GiB显存)上运行128k上下文推理,同时为vLLM等框架留出5%缓冲区,为视觉编码器留出1.3 GiB空间。
压缩前后的性能对比(来自官方技术报告):
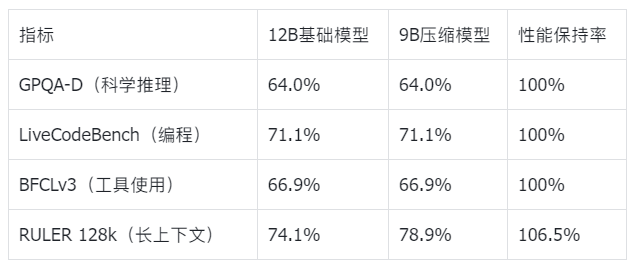
令人惊讶的是,经过压缩后的9B模型在大多数任务上保持了接近原始12B模型的性能,而在某些任务(如长上下文理解)上甚至超越了原有性能。这证明了NVIDIA压缩技术的卓越效果。
技术对比:Nemotron Nano 2 9B vs 竞品
为了更全面地评估Nemotron Nano 2 9B的竞争力,我们将其与当前市场上几款主流的边缘AI模型进行了详细对比。
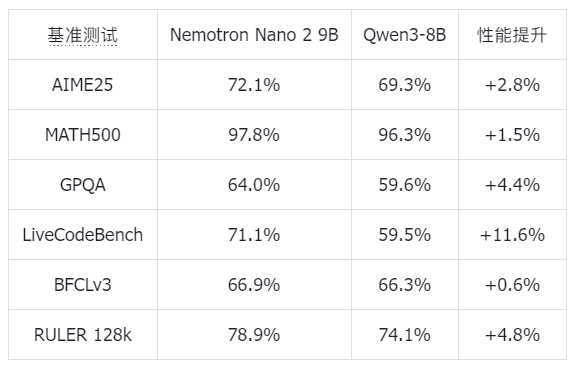
基准测试对比(来自Hugging Face官方模型卡片):
部署特性对比
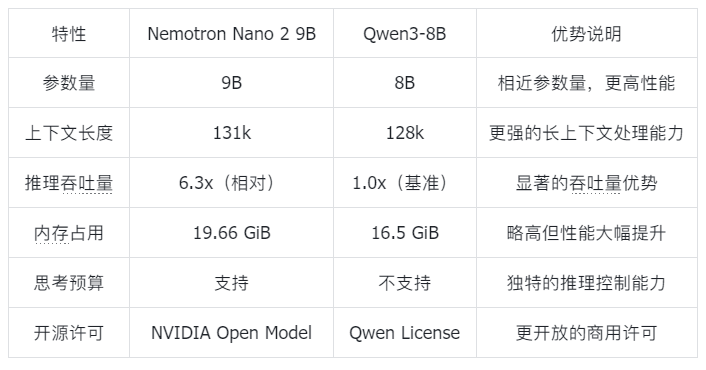
从对比数据可以看出,Nemotron Nano 2 9B在各项基准测试中均领先于同类模型,特别是在编程能力(LiveCodeBench提升11.6%)和长上下文任务(RULER 128k提升4.8%)上表现突出。其独特的思考预算功能更是其他模型所不具备的差异化优势。
根据权威市场研究机构Markets and Markets的报告,全球边缘AI硬件市场正迎来爆发式增长。报告显示:
边缘AI市场预测数据:
-
2025年市场规模:261.4亿美元
-
2030年市场规模:589亿美元
-
年复合增长率:17.6%
-
主要驱动力:5G技术普及、IoT设备增长、实时数据处理需求
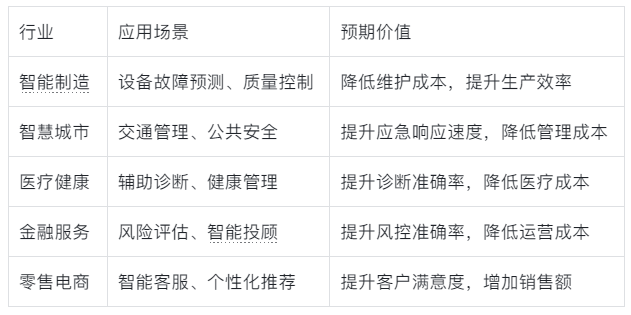
这一快速增长的市场为Nemotron Nano 2 9B这样的边缘AI模型提供了广阔的应用空间。特别是在中国这样制造业大国和互联网市场,边缘AI的应用前景尤为广阔。
国内应用场景
混合架构的创新之处
Nemotron Nano 2 9B的混合架构代表了AI模型设计的一个重要创新方向。传统Transformer架构虽然在处理全局依赖关系方面表现出色,但其计算复杂度随序列长度呈二次方增长,在处理长序列时效率低下。而Mamba架构则通过选择性状态空间机制,实现了线性时间复杂度,更适合处理长序列。
架构创新的技术细节:
-
Mamba-2层:占总层数的约45%,负责处理序列的局部依赖关系,具有线性时间复杂度和恒定内存占用。
-
注意力层:虽然只占总层数的约10%,但 strategically 分布在整个网络中,负责捕捉全局依赖关系。
-
FFN层:提供非线性变换能力,增强模型的表达能力。
这种“稀疏注意力+密集Mamba”的设计,既保持了Transformer处理全局依赖的能力,又获得了Mamba处理长序列的高效性。根据NVIDIA的技术报告,这种设计在保持模型性能的同时,将推理速度提升了6倍。
Nemotron Nano 2 9B的训练过程也体现了多项创新:
-
大规模预训练:使用20万亿token的数据进行预训练,采用FP8精度训练配方。
-
多阶段后训练:结合监督微调(SFT)、组相对策略优化(GRPO)、直接偏好优化(DPO)和强化学习人类反馈(RLHF)。
-
专门的数据集:包括数学、代码、多语言、推理等多个领域的专门数据集。
-
思维预算训练:约5%的训练数据包含故意截断的推理轨迹,为思维预算功能打下基础。
从模型到应用的完整链路
Nemotron Nano 2 9B的实用性不仅体现在其技术指标上,更体现在其完整的部署生态上。NVIDIA提供了从模型训练到部署的完整工具链。
部署方式:
-
NVIDIA NIM:作为推理微服务提供,针对高吞吐量和低延迟进行优化。
-
vLLM部署:支持通过vLLM进行本地部署,提供高性能推理能力。
-
云端API:通过build.nvidia.com提供API访问服务。
部署示例代码(来自官方文档):# 启动vLLM服务器vllm serve nvidia/NVIDIA-Nemotron-Nano-9B-v2 --trust-remote-code --mamba_ssm_cache_dtype float32
# Python客户端实现思考预算控制from typing import Any, Dict, Listimport openaifrom transformers import AutoTokenizer
class ThinkingBudgetClient: def __init__(self, base_url: str, api_key: str, tokenizer_name_or_path: str): self.base_url = base_url self.api_key = api_key self.tokenizer = AutoTokenizer.from_pretrained(tokenizer_name_or_path) self.client = openai.OpenAI(base_url=self.base_url, api_key=self.api_key) def chat_completion(self, model: str, messages: List[Dict[str, Any]], max_thinking_budget: int = 512, max_tokens: int = 1024, **kwargs): # 实现思考预算控制的完整逻辑 pass
这种完整的部署生态,使得开发者可以轻松地将Nemotron Nano 2 9B集成到各种应用场景中,充分发挥其边缘推理的优势。
边缘AI的“下一个十年”
Nemotron Nano 2 9B的发布不仅仅是一个新模型的诞生,更预示着边缘AI发展新纪元的到来。随着AI技术从云端向边缘迁移,我们将看到更多创新的应用场景和商业模式。
技术发展趋势
-
模型小型化:随着压缩技术的进步,未来我们将看到更多高性能的小参数模型,它们能够在资源受限的边缘设备上运行复杂的AI任务。
-
推理可控化:思考预算只是开始,未来AI模型将提供更多可配置的推理参数,让用户能够精确控制AI的行为和输出。
-
架构多样化:Transformer-Mamba混合架构只是探索之一,未来将出现更多创新的神经网络架构,针对不同应用场景进行优化。
-
部署标准化:随着NVIDIA NIM等推理微服务的普及,边缘AI的部署将变得更加标准化和简单化。
当AI学会“思考”,世界将如何改变?
Nemotron Nano 2 9B的发布,让我们看到了AI发展的另一种可能——不是一味追求参数量的“军备竞赛”,而是通过精巧的架构设计和创新的机制,让AI变得更加高效、可控和实用。
思考预算的概念,某种程度上反映了人类对AI的终极期待:我们希望AI能够像人一样思考,但又不像人那样无法控制。这种“可控的智能”或许才是AI真正落地的关键。
Nemotron Nano 2 9B只是开始,未来我们将看到更多这样的“小而美”的AI模型,它们将在我们的手机、汽车、家电、工业设备中默默运行,用可控的智能让我们的生活变得更加美好。
在这个AI狂飙突进的时代,NVIDIA用Nemotron Nano 2 9B告诉我们:真正的创新不在于大小,而在于巧思;真正的价值不在于参数,而在于实用。

















 1907
1907

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









