



源神阿里太卷了!
图像生成领域,卷掉了曾经的开源之王 Flux,现在连自己也难幸免。
8 月 Qwen 团队发布的 qwen-image 图像生成与编辑模型,至今仍然称霸图像生成开源界。

前几天通义实验室 Z-Image 团队发布的 z-image,直接将 qwen-image 拉下神坛。稳稳霸榜 Hugging Face。

人们以为阿里在玩左右互搏,没想到是 3 只手在互博!
这不,刚刚 Ovis 团队发布了 Ovis-Image。

这是一款仅 7B 参数的文本到图像模型,却在图像内文本渲染任务上展现出媲美 GPT-4o 和 20B+ 开源模型的惊人实力。
Ovis-Image 证明了只要有多模态骨干网的强力支撑和极度精细的训练配方,可靠的中文与英文文本渲染不再是超大闭源模型的专利,单张高端显卡即可承载前沿的生成能力。

架构做减法与能力做加法
在生成式 AI 的赛道上,长期存在一种迷信,认为高质量的文本渲染必须依赖于参数量的暴力堆叠。
现有的解决方案通常走向两个极端,要么像 Qwen-Image 那样将模型规模推高到数百亿参数,带来沉重的部署成本,要么像 Seedream 或 GPT-4o 那样保持闭源,让开发者难以窥探其后的技术细节。
Ovis 团队选择了一条不同的路径。
他们没有盲目扩大规模,而是回到了设计的原点,思考如何在受限的计算预算下,最大化模型的指令遵循能力和文本绘制精度。
Ovis-Image 的核心架构建立在 Ovis-U1 的基础之上,但在结构上进行了大刀阔斧的优化。
它抛弃了复杂的精炼器结构,直接利用多模态大模型的最终隐藏状态作为图像生成的条件输入。
这种设计思路的转变,本质上是将计算资源从画蛇添足的后处理,转移到了核心生成能力的构建上。
模型整体由三个关键部分精密咬合而成。
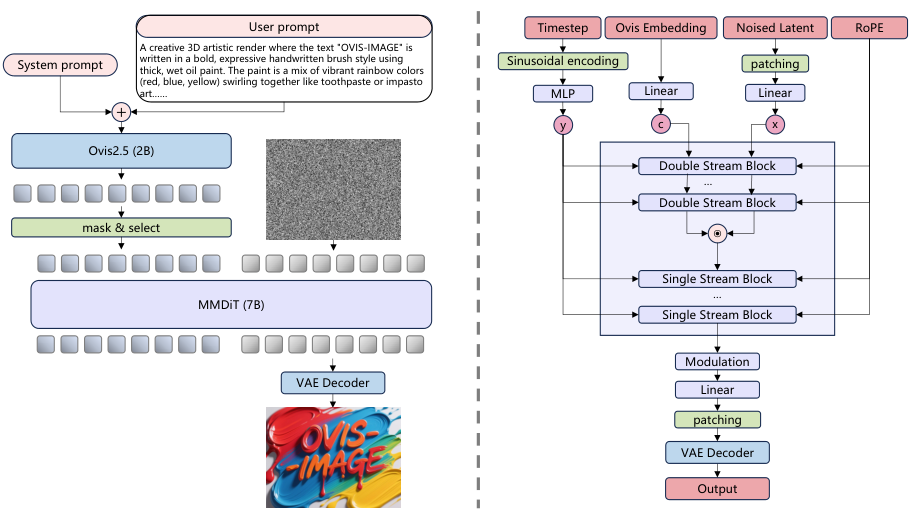
大脑是 Ovis 2.5 多模态大模型。
与常见的纯语言模型不同,Ovis 2.5 专门针对多模态数据集进行了训练,这意味着它在理解视觉与文本的对应关系上,拥有比普通语言模型更敏锐的直觉。
在 OpenCompass 基准测试中,Ovis 2.5 的表现甚至优于 Qwen2.5-VL-7B,这为后续的图像生成提供了极其精准的语义指引。
负责作画的手是参数量为 7.37B 的多模态扩散 Transformer (MMDiT)。
这个模块深受 Flux.1 Lite 的启发,包含了 6 个双流模块和 27 个单流模块。
为了提升模型处理复杂画面的容量,注意力头的数量被增加到了 24 个,激活函数也升级为 SwiGLU。
视觉信息的压缩与解压则交给了来自 FLUX.1-schnell 的变分自编码器 (VAE)。
为了保持视觉特征的稳定性,这个 VAE 模块在整个训练过程中都被冻结,不参与参数更新。
这套架构最终将总参数量控制在了 10.02B,其中核心的视觉生成部分仅占 7B。
数据工程决定了模型的上限
模型架构搭建了骨架,而数据工程则注入了灵魂。
Ovis-Image 之所以能以小博大,秘密藏在它那条精心设计的四阶段数据处理流水线中。
预训练阶段的数据决定了模型的知识广度。
团队构建了一个庞大的异构语料库,来源涵盖了网络抓取、商业许可和合成数据。
这些数据不仅包含日常摄影和插图,还特别吸纳了设计资产和 UI 模型,因为这些场景是文本渲染的高频地带。
为了解决原始数据中文本描述不准确的问题,团队对中英文数据进行了大规模的重标注 (Recaptioning)。
这不仅仅是简单的看图说话,而是通过更先进的视觉模型,生成与图片内容高度对齐的精确描述。
特别值得一提的是,团队引入了数据切片的概念。
他们专门筛选出那些文本是视觉核心元素的数据,比如海报、横幅、Logo 和 UI 布局,让模型在起步阶段就意识到文字不仅仅是符号,更是图像结构的一部分。
合成数据在这里扮演了关键角色。
利用渲染引擎,团队生成了大量包含清晰排版文本的合成样本,涵盖了各种字体、大小和布局。
这种受控的合成数据,就像是给模型上的书法课,让它在纯净的环境中学习文字的笔画和结构。
数据清洗环节同样严苛。
多阶段的过滤管道结合了启发式规则和跨模态一致性检查,那些图片模糊、文本描述不匹配或者存在安全隐患的数据被无情剔除。
预训练赋予了模型通用的视觉能力,而监督微调 (SFT) 则教会了模型听懂人话。
在这个阶段,数据质量被进一步提纯。
图像分辨率被提升到 1024 像素,涵盖了更广泛的纵横比,以适应真实世界的应用场景。
数据配比经过了精心的平衡。
自然图像提供了真实感,合成数据补充了细节锐度和稀有概念的覆盖。
通过这种混合训练,模型学会了如何将用户的指令转化为高保真的图像,不再是盲目地堆砌元素,而是理解指令背后的构图逻辑。
四阶段训练范式重塑生成质量
Ovis-Image 的训练过程是一场精密的接力赛,每一个阶段都在为下一个阶段的跃升奠定基础。
整个训练框架基于 PyTorch 构建,利用混合分片数据并行 (HSDP) 技术,在 bfloat16 混合精度下高效运转。
预训练建地基。
MMDiT 从随机初始化开始,在标准噪声预测损失的指引下,贪婪地吸收海量数据中的视觉规律。
训练策略采用了变分辨率机制,从最初的 256x256 逐步过渡到 512 至 1024 像素,纵横比也从 0.25 延伸到 4.0。
这种渐进式的训练让模型不仅学会了画画,还学会了适应各种画布的尺寸。
文本编码器和 VAE 在此阶段保持冻结,确保了语义理解和视觉重构的稳定性。
监督微调建立规矩。
模型从处理通用的描述数据,转向处理指令式的监督数据。
学习率被调低,时间表被缩短,目的是在保留预训练学到的通用视觉能力的同时,让模型适应指令跟随的新任务。
这就像是让一个已经学会绘画的学生,开始专门练习命题作文。
直接偏好优化 (DPO),是审美与准确性的进化。
这一阶段引入了人类和模型生成的偏好数据。
对于同一个提示词,模型会生成两张图,一张是符合人类审美和文本要求的高质量优胜者,另一张是相对较差的失败者。
通过最小化 Diffusion-DPO 目标函数,模型被训练去模仿优胜者的生成轨迹,同时远离失败者的路径。
为了防止模型矫枉过正,团队引入了一个巧妙的获胜者保护机制。
在传统的 DPO 训练中,如果失败者的梯度更新过于激进,可能会破坏优胜者已经学到的好的特征。
Ovis-Image 引入了梯度缩放因子。
当失败者的梯度方向与优胜者的梯度方向发生冲突,导致优胜者的损失可能增加时,这个机制会自动降低失败者梯度的权重。
这相当于给模型的自我修正装上了一个安全阀,确保每一次优化都是在稳步提升图像质量,而不是引入新的噪声或伪影。
群组相对策略优化 (GRPO),这是对文本渲染的终极打磨。
这是 Ovis-Image 能够实现高精度文本生成的杀手锏。
在这个阶段,模型不再是单打独斗,而是进行群组作战。
对于每一个提示词,模型会生成一组候选图像。
这组图像会被送入多个奖励模型进行评分。
评分不仅关注画面的美观度,更聚焦于文本的拼写准确性、排版的合理性。
通过计算每个图像在群组中的相对优势,模型能够更清晰地感知到什么样的文本渲染才是完美的。
为了提高训练效率,团队在这一阶段采用了系数保留采样技术,并减少了去噪步数。
这使得模型能够在有限的计算资源下,快速地在生成的搜索空间中找到最优解。
实测数据验证小模型的越级挑战
Ovis-Image 在多个权威基准测试中的表现,用数据打破了参数量决定论。
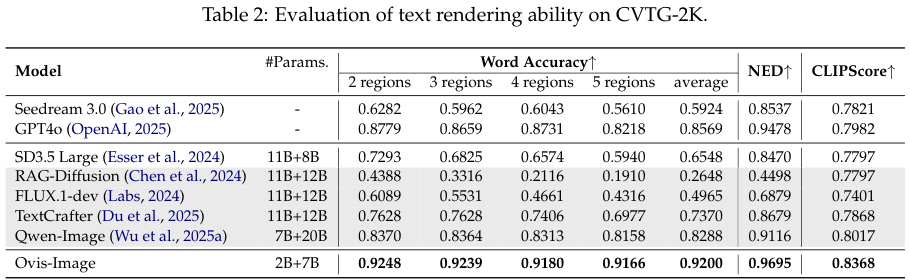
在 CVTG-2K 基准测试中,Ovis-Image 面对的是 2000 个要求极高的英文文本渲染任务。
结果显示,它的词准确率 (Word Accuracy) 达到了 0.9200。
这是一个令人咋舌的数字,因为它显著优于 7B+20B 参数架构的 Qwen-Image (0.8288),甚至超过了闭源巨头 GPT-4o (0.8569)。
在衡量文本编辑距离的 NED 指标上,Ovis-Image 以 0.9695 的高分位居榜首。
这说明它生成的文本不仅拼写正确,而且在字符级别的细节上也经得起推敲。
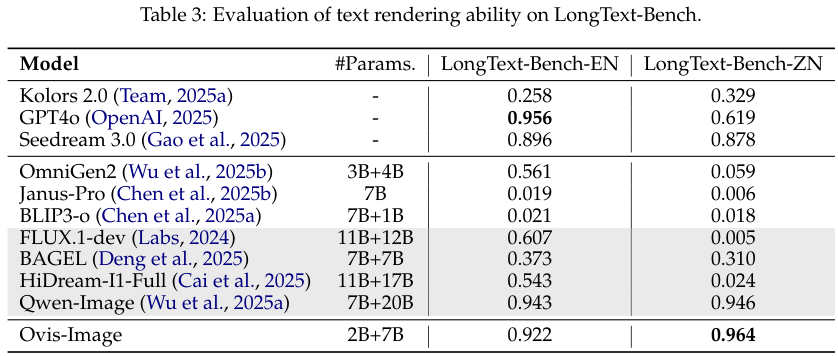
LongText-Bench 测试则进一步考验了模型在长文本生成上的耐力。
在中文长文本 (LongText-Bench-ZN) 任务中,Ovis-Image 展现了统治级的表现,得分高达 0.964。
相比之下,Qwen-Image 的得分为 0.946,而 GPT-4o 仅为 0.619。
这表明在处理复杂的中文笔画和长句排版时,Ovis-Image 对多模态数据的深度理解发挥了关键作用。
在英文长文本任务上,它也以 0.922 的高分紧咬 Qwen-Image 和 GPT-4o,差距微乎其微。
通用生成能力的评估同样没有落下。
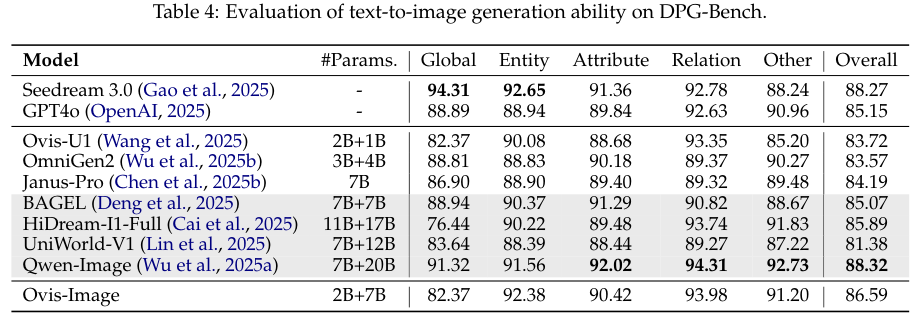
在 DPG-Bench 测试中,Ovis-Image 的总体评分为 86.59。
虽然略低于 Qwen-Image 的 88.32,但考虑到两者的参数量差距,这个成绩足以证明 Ovis-Image 在通用场景下的鲁棒性。
特别是在关系 (Relation)这一维度上,Ovis-Image 拿到了 93.98 的高分,说明它在处理物体之间的空间关系和逻辑联系上有着独特的优势。
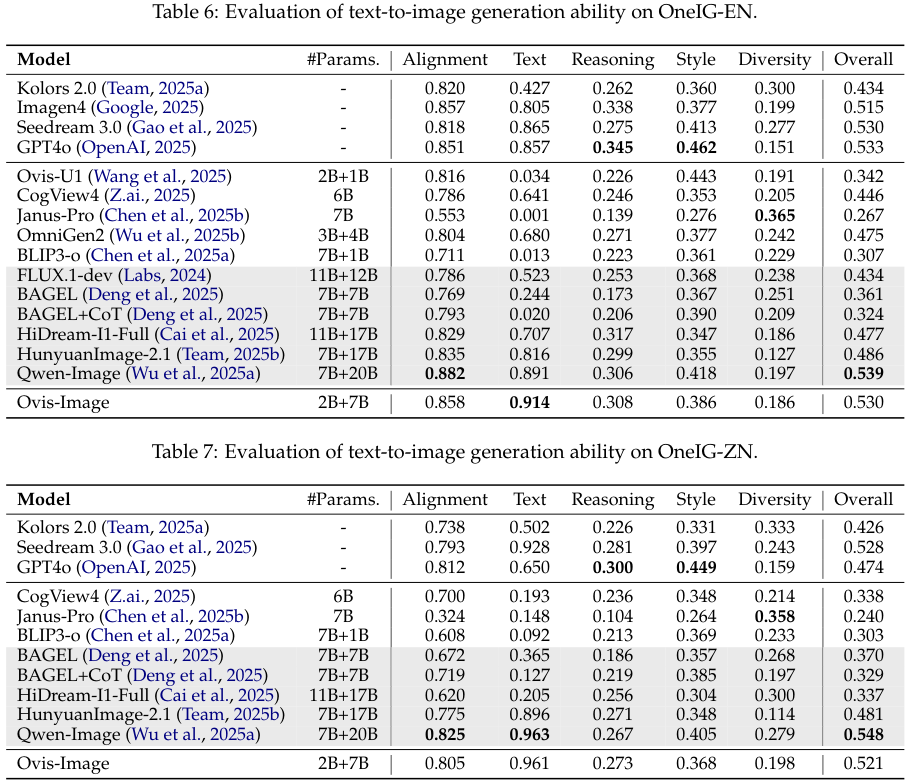
OneIG-Bench 的测试结果进一步印证了这一点。
在中文子集 (OneIG-ZN) 中,Ovis-Image 的文本维度得分高达 0.961,展现了卓越的双语处理能力。
GenEval 基准测试关注对象属性的组合生成。
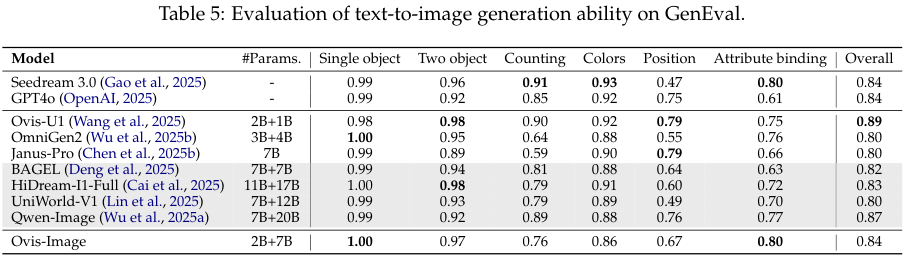
Ovis-Image 在这里拿到了 0.84 的总体评分,与 GPT-4o 和 Seedream 3.0 持平。
在单一对象生成的子项中,它更是拿到了 1.00 的满分,证明了其基础生成能力的扎实。
计算效率是 Ovis-Image 最大的落地优势。
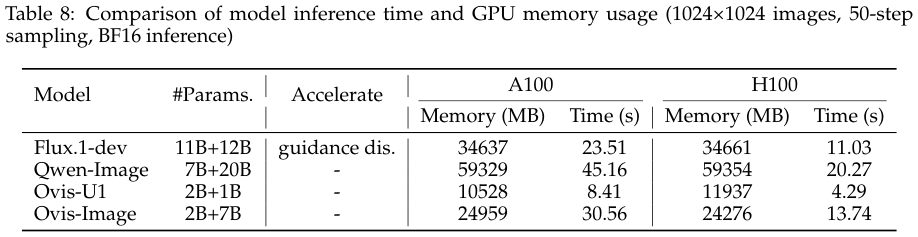
在 A100 GPU 上生成一张 1024x1024 的图像,进行 50 步采样,Ovis-Image 仅需占用 24,959 MB 的显存。
作为对比,Qwen-Image 需要庞大的 59,329 MB。
这意味着 Ovis-Image 的显存占用不到竞品的 42%。
在推理速度上,Ovis-Image 仅需 30.56 秒,比 Qwen-Image 快了约 33%。
在更先进的 H100 GPU 上,推理时间更是被压缩到了 13.74 秒。
这种高效低耗的特性,让 Ovis-Image 不再是实验室里的庞然大物,而是可以真正部署在单张显卡上的生产力工具。
Ovis-Image 告诉我们,前沿的文本感知生成能力,并不一定是从通用图像合成中偶然涌现的副产品。
通过精心选择的架构、高质量的数据策展以及针对性的对齐目标,中等规模的模型完全可以围绕图像内文本的需求进行重构。
免费试用:
https://huggingface.co/spaces/AIDC-AI/Ovis-Image-7B
参考资料:
https://huggingface.co/AIDC-AI/Ovis-Image-7B
https://github.com/AIDC-AI/Ovis-Image
https://arxiv.org/abs/2511.22982
END

















 814
814

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









