




 本文介绍了DDMP,一种重要的扩散模型,它包括前向过程(不断添加噪声)和反向过程(逐步去噪)。前向过程通过添加高斯噪声破坏图像,反向过程则学习如何通过神经网络消除噪声以恢复图像。训练目标是最大化生成样本的对数似然性,简化后的损失函数是前向过程添加的噪声和模型预测噪声之间的均方误差。
本文介绍了DDMP,一种重要的扩散模型,它包括前向过程(不断添加噪声)和反向过程(逐步去噪)。前向过程通过添加高斯噪声破坏图像,反向过程则学习如何通过神经网络消除噪声以恢复图像。训练目标是最大化生成样本的对数似然性,简化后的损失函数是前向过程添加的噪声和模型预测噪声之间的均方误差。
由于课题组研究需要,了解了一下当前比较火爆的扩散模型(Diffusion Model),其中DDMP作为扩散模型中比较重要的基础模型之一,特此记录。
这篇论文主要介绍了一种去噪扩散概率模型。
关于扩散模型的一些基础笔记,记录在http://t.csdn.cn/VZkZG
模型原理
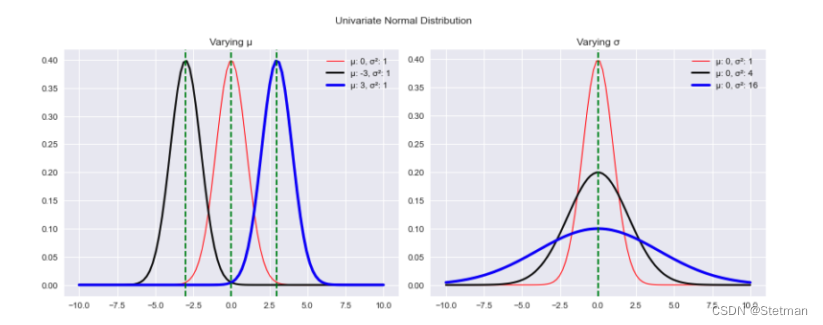
* PDF:PDF是一个“概率函数”,表示连续随机变量的密度(可能性)——在这种情况下,这意味着一个函数,表示图像位于函数参数定义的特定值范围之间的可能性。 每个PDF都有一组参数,这些参数决定了分布的形状和概率。分布的形状会随着参数值的变化而变化,如下图所示。例如,在正态分布的情况下,我们有均值µ(mu)和方差σ2(sigma)来控制分布的中心点和扩散。
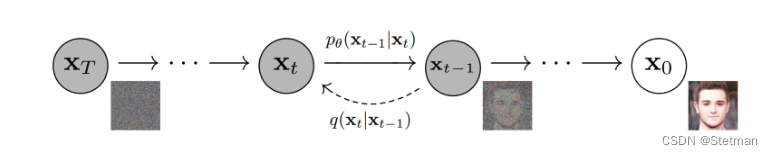
上图体现了扩散模型的正反向扩散过程,其中:
![]()
这个术语也被称为前向扩散核(FDK)。它定义了给定图像xt-1的前向扩散过程xt中的时间步长t处的图像的PDF。它表示正向扩散过程中每一步应用的“过渡函数”。
![]()
类似于正向过程,这个术语被称为反向扩散核(RDK)。它代表给定xt的xt-1的PDF,由𝜭. 这个𝜭 意味着使用神经网络来学习反向过程的分布参数。它是应用于反向扩散过程中每一步的“过渡函数”。
简言之,在DDPM模型中,主要包括了两个过程:
-
前向过程 (Forward process):不断地往原始图片中添加噪声
-
反向过程 (Reverse process):通过不断地去噪去复原图片

向前过程分析:
简单来说,前向过程的输入是原始图片,该图片服从一定的分布,输出是噪音图片,该图片服从高斯分布。
在前向过程中,对于一个输入图片,在某一个特定的时间 t 下,添加某种程度的噪音,得到噪音样本。前向过程不断重复该步骤,结果是一个时间序列和一系列噪音增大的图片。
具体来说,从数据分布 q(x) 中选取图片 x0,在时间序列 {0, T} 内的某个时间 t,选取某个等级的噪音 nt,把噪音添加到输入图片,得到噪音样本 xt。在 T 个步长后得到样本序列:{X0, Xt}。步长由超参数方差机制 βt(0 - 1) 来控制。
前向扩散过程中的分布q被定义为马尔可夫链,由下式给出:
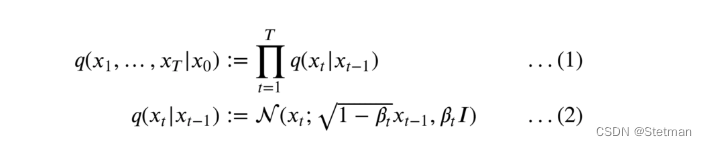
我们首先从我们的数据集中获取一张图像:x0。从数学上讲,它被称为从原始(但未知)数据分布中采样一个数据点:x0~q(x0)。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2123
2123




 到【灌水乐园】发言
到【灌水乐园】发言







