







前排提示:本片笔记纯属自己写给自己看,里面有不少自己的理解和引用,如有侵权请删除联系
基本思路:对一张已有的图片先进行前向加噪,通过概率论数学推导发现反向生成需要预测噪声,所以让一个神经网络去学习这个加噪过程的规律,之后取一个随机噪音,结合这个网络进行逐步去噪完成反向生成
题外话:怎么生成服从高斯分布的数据 (Box-Muller变换)
设 U 1 , U 2 U_1,U_2 U1,U2 相互独立且服从均匀分布 U ( 0 , 1 ) U(0,1) U(0,1),令 R = − 2 l o g U 1 , θ = 2 π U 2 R=\sqrt{-2logU_1},\theta=2\pi U_2 R=−2logU1,θ=2πU2,则 X = R c o s θ , Y = R s i n θ X=Rcos\theta, Y=Rsin\theta X=Rcosθ,Y=Rsinθ 服从标准正态分布且相互独立
1.前向扩散 Q ( x t ∣ x t − 1 ) Q(x_t|x_{t-1}) Q(xt∣xt−1)
以下推导和神经网络无关,只是加噪过程的概率描述
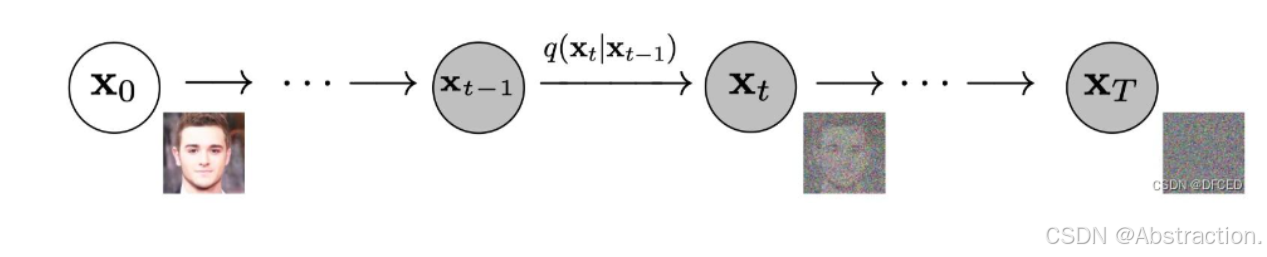
前向扩散(逐渐加噪,代码中为1000次),越往后增加的噪音越强(β接近1)
x t = 1 − β t x t − 1 + β t ε t − 1 x_t=\sqrt{1-\beta_t}x_{t-1} + \sqrt{\beta_t} \varepsilon_{t-1} xt=1−βtxt−1+βtεt−1
等价于 q ( x t ∣ x t − 1 ) = N ( x t ; 1 − β t x t − 1 , β t I ) q(x_{t}|x_{t-1})=N(x_t;\sqrt{1-\beta_t}x_{t-1},\beta_tI) q(xt∣xt−1)=N(xt;1−βtxt−1,βtI)
实际上可以直接一步到位,也就是 x t x_t xt 可以根据 x 0 , t x_0,t x0,t 直接推导出来
根据高斯分布叠加性 a X + b Y ∼ N ( a μ 1 + b μ 2 , a 2 σ 1 2 + b 2 σ 2 2 ) aX+bY∼N(aμ_1+bμ_2,a^2σ_1^2+b_2σ^2_2) aX+bY∼N(aμ1+bμ2,a2σ12+b
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 785
785

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









