




 文章提出了EQ-Radio方法,通过分析人体反射的射频信号无接触地推断情绪。该方法克服了依赖视听技术和物理设备的局限,通过心跳信号预测情绪,使用特殊算法减弱呼吸影响并分割心跳信号。最终,心跳和呼吸特征被用于情绪分类,采用SVM进行情绪状态的识别。
文章提出了EQ-Radio方法,通过分析人体反射的射频信号无接触地推断情绪。该方法克服了依赖视听技术和物理设备的局限,通过心跳信号预测情绪,使用特殊算法减弱呼吸影响并分割心跳信号。最终,心跳和呼吸特征被用于情绪分类,采用SVM进行情绪状态的识别。
这是2016年的一篇文章,应该算是物联网中情感识别的开山之作。之前参与物联网课题就有了解过,最近又接触情感识别的相关课题,又重新精读了一遍。
文章简述
作者认为现存通过视听技术来判断个人情绪的方法并不合适,因为它只关注了外表,并没有从人的内心感受进行推断。文章提出了一种名为EQ-Radio方法:通过分析从人体反射的射频信号来推断一个人的情绪。这种创新的方法消除了对物理接触或佩戴设备的需求,同时也让情绪识别更加便捷和可靠。
作者提出的方法需要通过心跳信号来对情绪进行预测,而一般情况下呼吸比心跳带来的振动大一个量级,因此分离出所需的心跳信号比较困难;第二,射频信号中的心跳缺乏作为心电信号特征的尖锐峰,这使得很难准确识别心跳边界。第三,节拍间隔的差异(IBI )只有几十毫秒。因此,单个节拍必须在几毫秒内被分割成分段。在没有尖锐特征的情况下,获得这样的准确性尤其困难 识别心跳的开始时间或结束时间。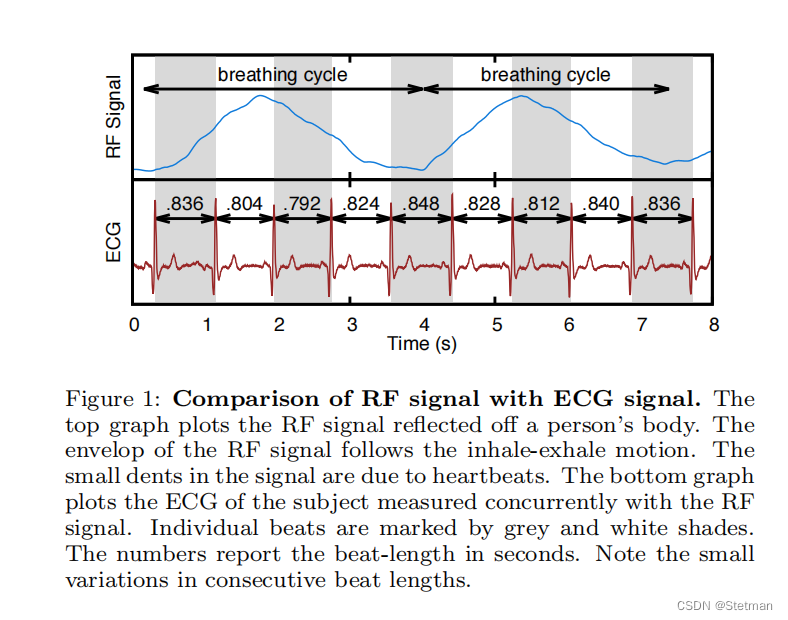
作者通过算法分别解决了以上问题:
(1)EQ-Radio 的关键技术是一种从射频信号中提取个人心跳及其差异的新算法。 我们的算法首先减轻了呼吸的影响。我们的缓解机制所基于的直觉如下:虽然吸气-呼气过程导致的胸部位移 比心跳引起的微小振动大几个数量级,但呼吸的加速度却小于心跳的加速度。但呼吸加速度却小于心跳加速度。这是因为呼吸通常是缓慢而稳定的 而心跳则涉及肌肉的快速收缩(发生在局部区域)。这是因为呼吸通常是缓慢而稳定的,而心跳则涉及肌肉的快速收缩(在局部时间内发生)。 因此,EQ-Radio 利用射频信号的加速度 以减弱呼吸信号,突出心跳信号。
(2)EQ-Radio 需要将射频反射信号分割成单个心跳信号。心电图信号有一个已知的预期形状,而射频反射中的心跳形状则是未
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2137
2137

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









