




 本文详细介绍了时序差分(TD)方法中的TD预测及控制技术,包括TD(0)算法、Sarsa同轨控制及Q学习离轨控制等内容,并对比了动态规划法DP、蒙特卡洛法MC与TD的不同。
本文详细介绍了时序差分(TD)方法中的TD预测及控制技术,包括TD(0)算法、Sarsa同轨控制及Q学习离轨控制等内容,并对比了动态规划法DP、蒙特卡洛法MC与TD的不同。
目录
1. TD预测
TD是另一种对最优策略的学习方法,本节讲述TD预测,即使用TD求解策略 π \pi π的值函数 v π ( s ) v_{\pi}(s) vπ(s)。
TD预测被称为 DP 和 MC 的结合体,DP是 期望更新+自举bootstrap,MC是 采样更新 + 样本估计。而TD则是采样更新 + 自举,即值函数 V ( S t ) V(S_t) V(St)更新基于采样得到的 V ( S t + i ) V(S_{t+i}) V(St+i)的结果。
如果 i = 1 i=1 i=1,就为TD(0)单步TD算法,否则就为多步TD
当然动态特性 p ( s ′ , a ∣ s , a ) p(s',a|s,a) p(s′,a∣s,a)对于TD也是未知的。
1.1. TD(0)算法
根据采样更新与自举的思想,TD(0)的状态值函数预测式为
V ( S t ) = V ( S t ) + α [ R t + 1 + γ V ( S t + 1 ) − V ( S t ) ] (1) V(S_t) = V(S_t) + \alpha[R_{t+1} + \gamma V(S_{t+1}) - V(S_t)] \tag{1} V(St)=V(St)+α[Rt+1+γV(St+1)−V(St)](1)
先给出一些定义:
TD目标:指 R t + 1 + γ V ( S t + 1 ) R_{t+1} + \gamma V(S_{t+1}) Rt+1+γV(St+1)
TD误差:指 R t + 1 + γ V ( S t + 1 ) − V ( S t ) R_{t+1} + \gamma V(S_{t+1}) - V(S_t) Rt+1+γV(St+1)−V(St)
步长\学习率:指 α \alpha α
如何理解上述定义呢?
结合图一看就明白了。对于状态 s s s,所有包含 s s s的episode均会使值函数的估计值 V ( s ) V(s) V(s)朝着TD目标走长度为 α \alpha α倍TD误差 的一步,而获得新的 V ( s ) V(s) V(s)。就是经过这样不断地走,最终会接近 v π ( s ) v_{\pi}(s) vπ(s)。
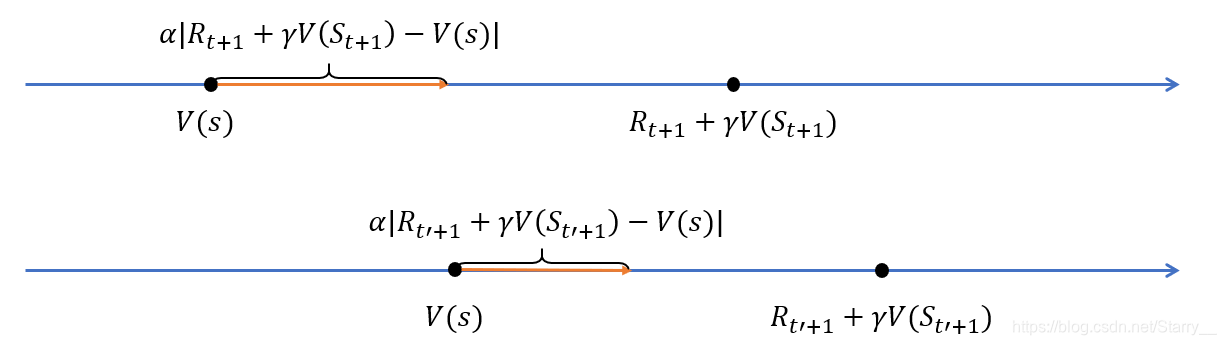
有没有想到梯度下降中的步长的概念?意思其实是一样的,同样的可以使用非恒定学习率,例如 1 s 的 更 新 次 数 \frac{1}{s的更新次数} s的更
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 892
892

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











