




 本文深入解析了TD算法,一种将DP和MC算法相结合的RL核心算法。TD算法无需等待最终结果即可更新估计值,通过bootstrap方式自我迭代。此外,文章还介绍了Q-learning,一种离策略TD控制方法。
本文深入解析了TD算法,一种将DP和MC算法相结合的RL核心算法。TD算法无需等待最终结果即可更新估计值,通过bootstrap方式自我迭代。此外,文章还介绍了Q-learning,一种离策略TD控制方法。
temporary
英 ['temp(ə)rərɪ]美 [ˈtempəreri]
adj. 临时的,暂时的;短暂的
n. 临时工,临时雇
TD算法是RL的核心算法。TD是DP和MC算法的结合。Like DP, TD methods without waiting for a final outcome (they bootstrap)。
TD(0), or one-step TD

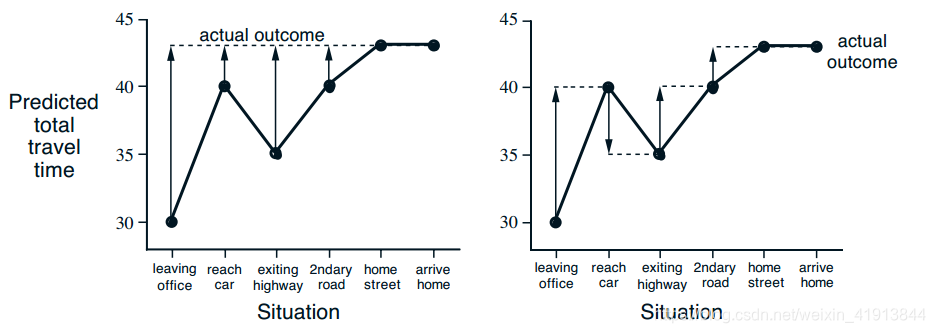
Advantages of TD Prediction Methods
TD methods update their estimates based in part on other estimates. They learn a guess from a guess,they bootstrap.

Q-learning: Off-policy TD Control
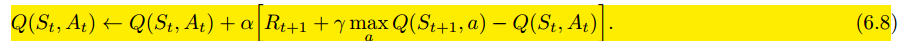


















 2352
2352

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









