




✨✨ 欢迎大家来访Srlua的博文(づ ̄3 ̄)づ╭❤~✨✨🌟🌟 欢迎各位亲爱的读者,感谢你们抽出宝贵的时间来阅读我的文章。
我是Srlua小谢,在这里我会分享我的知识和经验。🎥
希望在这里,我们能一起探索IT世界的奥妙,提升我们的技能。🔮
记得先点赞👍后阅读哦~ 👏👏
📘📚 所属专栏:传知代码论文复现
欢迎访问我的主页:Srlua小谢 获取更多信息和资源。✨✨🌙🌙


目录
本文所有资源均可在该地址处获取。
文献参考
Learning representations by back-propagating errors
《Learning representations by back-propagating errors》这篇论文是神经网络和机器学习领域的开创性工作,由David E. Rumelhart, Geoffrey E. Hinton, 和 Ronald J. Williams于1986年发表。这篇论文的主要内容是介绍了反向传播算法(Backpropagation),这是一种用于训练多层神经网络的高效方法。
反向传播算法的核心思想是利用链式法则来计算神经网络中每个权重参数的梯度,即计算损失函数对每个权重的影响。这些梯度随后用于通过梯度下降法更新网络中的权重,目的是最小化网络的预测误差。
论文的主要贡献包括:
反向传播算法的描述:详细阐述了如何计算多层网络中每个权重的误差梯度。这个过程涉及到从输出层开始,逐层向后传播误差信号,直到达到输入层。
误差梯度的计算:论文解释了如何利用误差梯度来调整网络中的权重,以便减少网络输出和目标值之间的差异。
网络结构的讨论:论文讨论了不同类型的网络结构,包括前馈网络和反馈(递归)网络,并探讨了它们在不同任务中的应用。
学习表示的选择:论文讨论了学习表示的重要性,即网络如何通过学习输入数据的内在特征来提高性能。
实验结果:提供了使用反向传播算法训练网络的实验结果,展示了该算法在语音识别和手写字符识别等任务上的有效性。
反向传播算法的提出对深度学习的发展产生了深远的影响,它使得研究人员能够训练具有大量参数的复杂神经网络,这在之前是不可能的。这篇论文因此被认为是深度学习领域的里程碑之一。
概述
本文将详细推导一个简单的神经网络模型的正向传播、反向传播、参数更新等过程,并将通过一个手写数字识别的例子,使用python手写和pytorch分别实现,能够让读者深刻地理解神经网络的具体参数更新训练的工作流程,文末将包含数据+代码+PPT。
这些内容是基于神经网络和机器学习的通用知识,正向传播和反向传播,如今几乎所有的深度学习模型的训练都是基于这样相同或者相似的方法进行训练的,有助于帮助我们更加深入的理解深度学习模型。
引言
多层感知机(Multilayer Perceptron,简称MLP)是神经网络的一种。MLP是一种前馈神经网络,它包含一个或多个隐藏层,以及非线性激活函数,这使得MLP能够学习和模拟复杂的非线性关系。MLP是最基础也是最广泛研究的神经网络类型之一,本文将以一个MLP模型来展开。
MLP的结构通常如下:
输入层:接收外部输入数据。
隐藏层:一个或多个隐藏层,每层包含多个神经元。隐藏层负责从输入数据中提取特征并进行初步的非线性变换。
输出层:输出网络的预测结果,对于分类问题,输出层通常使用softmax激活函数进行多类分类。
MLP的训练过程通常包括以下几个步骤:
前向传播:输入数据通过网络,通过每个神经元的加权和和激活函数,最终得到输出。
计算损失:使用损失函数(如均方误差、交叉熵等)计算网络输出与真实标签之间的差异。
反向传播:根据损失函数的梯度,计算每一层的权重对损失的贡献,即梯度。
权重更新:使用梯度下降或其他优化算法(如Adam、RMSprop等)根据梯度更新网络的权重和偏置。
MLP在许多领域都有应用,包括图像识别、语音识别、自然语言处理、游戏AI等。随着深度学习的发展,MLP作为深度神经网络的基础,其结构和训练方法也在不断地被改进和优化。
实际上,几乎所有的深度学习模型中都会有MLP的身影,相当于深度学习模型的骨架,特别是在深度学习模型中最后一步,通常会接个MLP来使得输出的维度符合我们任务的需求,例如我们当前需要要对手写数字识别,那就是一个10分类问题,最后输出可以通过接一个MLP变成10维,每一维代表一个分类,从而顺利地使模型适配我们的任务。
神经网络公式推导
参数定义

假设我们有这么一个神经网络,由输入层、一层隐藏层、输出层构成:
(这里为了方便,不考虑偏置bias)

Simoid激活函数如下:

前向传播(forward)
首先,我们可以试着表示一下y1
如模型图所示可以表示为:

那么我要表示yj呢?

其中j=1时,就是y1的表示,j=m时,就是ym的表示。
同理我们可以得到:

ok表示输出层第k个神经元的预测值,这就是我们需要的输出。
至此,正向传播完毕。
反向传播(backward)
光正向传播,我们只能得到模型的预测值,不能更新模型的参数,也就是说,正向传播的时候,模型是不会被更新的。
因为我们得到了模型输出的预测值,并且我们手上有对应的真实值,我们就能够将误差反向传播,更新模型参数。
具体操作怎么操作呢?
首先,我们需要定义误差,即预测值和真实值差了多少,以此来决定模型参数更新的方向和力度。
这里我们采用简单的差的平方的损失函数:

注意,这里只是更新输出层第k个神经元所反馈的误差。
隐藏层和输出层的权重更新
首先根据已知如下:
输出层预测值ok

激活函数Sigmoid
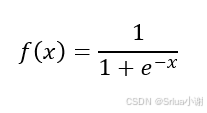
那我们可以试着展开一下Ek
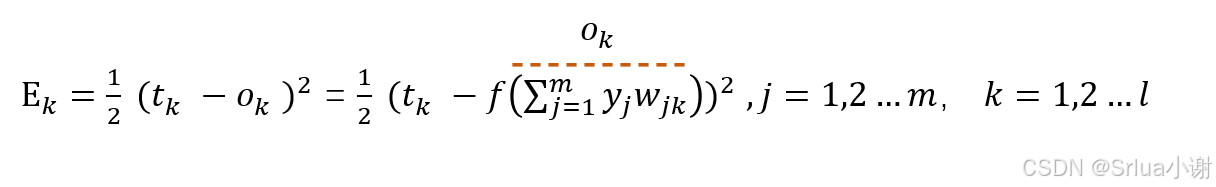
因为我们现在需要更新的是wjk,因此展开到wjk我们就能有一个比较形象的认识了。
根据梯度下降法可得,我们现在只需要求出

即可通过

来更新我们隐藏层和输出层的权重了。
那么如何计算呢?
直接求导可能有点混乱,利用复合函数求导的方法,我们可以根据链式法则将表达式展开如下:

接下来我们分别求出:

以及

就可以了。
我们先给出激活函数的导数推导过程:


就是使用复合函数除的求导法则进行求导。我们可以发现sigmoid函数求导之后还是挺好看的。
接下来就是计算两个导数即可。

首先:

一眼就能看出来了吧。
就是别忘了里面的-ok也要导,负号别漏了
然后是

这个可能会有点困难,但是仔细看看,发现还是很简单的。
首先


(链式求导法)
因此:

那么这个结果计算起来就比较简单了。
既然如此,将结果拼起来就是我们要求的结果了:

其中:

全是已知的,不就可以更新参数了嘛
因此,加个学习率这层权重更新推导就大功告成了。

输入层和隐藏层的权重更新
如果上面的推导看懂了,下面的推导就非常简单了,无非就是多展开一级,多求一次导数而已。
首先(前面已经推到过了)

那么我们可以将误差再展开一级(接着链导下去):

那么下面这个就非常直观了

同样的,我们也分别求出三次的导数,最后拼起来就行了。



至此分别求出来了,拼起来就是我们要的结果了:

通过观察,里面全是已知的变量
那么更新公式也就有了:

至此我们公式推导就完成了。
数据集介绍
实验数据就是mnist手写数据集

第一列为label,表示这个图片是什么数字
后面都为图片的像素值,表示图片的数据
模型的输入就是像素值,输出就是预测值,即通过像素预测出是什么数字。
核心代码
其中比较关键的就是那两个参数的更新公式。
隐藏层和输出层的权重更新:

输入层和隐藏层的权重更新:

数据集+python手写代码+pytorch代码+ppt都在附件里哦
运行结果
pytorch结果:

python手写结果:
总结
感觉从推导到代码实现也是一个反复的过程,从推导发现代码写错了,写不出代码了就要去看看推导的过程,这个过程让我对反向传播有了较全面的理解。
我们发现,手写代码运行时间要一分多钟而pytorch其实只要10s不到,毕竟框架,底层优化很多,用起来肯定用框架。
以及二者准确率有一些差距,可能是因为pytorch里使用了交叉熵损失函数,比较适合分类任务;手写的并没有分batch,而是所有数据直接更新参数,但是pytorch里分了batch,分batch能够使得模型训练速度加快(并行允许),也使得模型参数更新的比较平稳。

希望对你有帮助!加油!
若您认为本文内容有益,请不吝赐予赞同并订阅,以便持续接收有价值的信息。衷心感谢您的关注和支持!


















 2325
2325

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









