




✨✨ 欢迎大家来访Srlua的博文(づ ̄3 ̄)づ╭❤~✨✨🌟🌟 欢迎各位亲爱的读者,感谢你们抽出宝贵的时间来阅读我的文章。
我是Srlua小谢,在这里我会分享我的知识和经验。🎥
希望在这里,我们能一起探索IT世界的奥妙,提升我们的技能。🔮
记得先点赞👍后阅读哦~ 👏👏
📘📚 所属专栏:传知代码论文复现
欢迎访问我的主页:Srlua小谢 获取更多信息和资源。✨✨🌙🌙



目录
2.2 VALL-E 如何利用语音编解码技术进行文本到语音的合成
4.1 VALL-E 在 LibriSpeech 数据集上的表现
4.4 强调 VALL-E 在合成语音时的多样性、保真性和说话者相似度
本文所有资源均可在该地址处获取。
1. 引言
语音合成技术在现代通信和娱乐领域扮演着愈发重要的角色,它不仅让我们能够与机器更自然地交流,还在无障碍技术和虚拟助手等方面发挥着关键作用。近期,一个引人注目的语音合成模型——VALL-E,突破性地采用了全新的方法,为语音合成技术的未来开启了新的里程碑。
1.1 语音合成技术的背景
随着人工智能和自然语言处理领域的迅猛发展,语音合成技术逐渐成为人们关注的焦点。起初,语音合成主要通过简单的文本到语音(TTS)模型实现,但随着技术的不断演进,如今的语音合成已经远非过去可比。这项技术的进步不仅在改善视觉障碍者的生活方面发挥着巨大作用,还推动了虚拟助手、智能客服等各种应用的广泛普及。
语音合成技术的演进为人机交互提供了更加自然、高效的手段。过去,TTS模型主要通过转换给定的文本为语音,但这往往缺乏自然流畅的音韵和抑扬顿挫。然而,随着深度学习和神经网络技术的发展,新一代的语音合成模型变得更加智能、灵活,能够更好地捕捉语音的细致差异,使得合成语音更加自然贴近真实。
1.2 VALL-E 模型的崭新方法
在语音合成领域,VALL-E 模型以其独特的方法引起了广泛关注。传统的语音合成方法主要集中在音频的生成和重建上,但VALL-E 模型摒弃了这种传统思路,引入了语音编解码技术,将语音信号转换成中间表示。这个全新的方法为语音合成的未来打开了新的方向。
VALL-E 模型的语音编解码技术具有创新性,它不仅能够更好地理解语音信号的特征,还能够在生成过程中更灵活地应对各种语音场景。这种崭新的方法为零样本学习提供了可能性,使得模型能够在未见过的说话者或语音情境下表现出色。在本文中,我们将深入剖析VALL-E 模型的工作原理,挖掘其独到之处,并详细探讨其在零样本学习和语音合成方面取得的显著成果。
2. VALL-E 模型概览
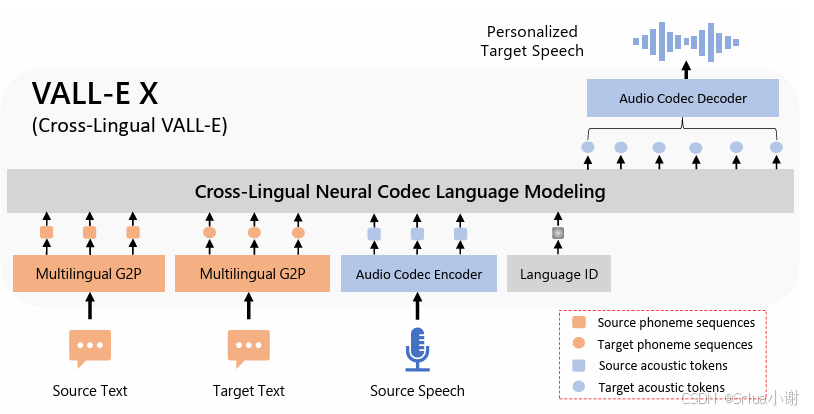
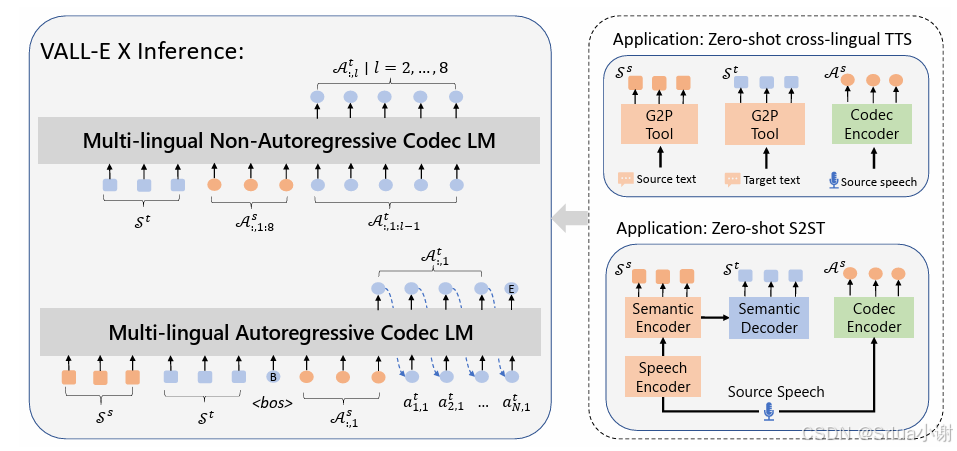
VALL-E X跨语音框架:个性合成他语音,无需同一说话者跨语音数据,实现零样本跨语音任务。
2.1 VALL-E 模型的核心思想
VALL-E 模型作为一种语音合成技术的创新,其核心思想在于摒弃传统的语音合成方法,大胆采用了语音编解码技术。这一突破性的思想源于对语音合成过程的全新思考,旨在通过更智能、更高效的方式实现文本到语音的转换。传统的语音合成方法常常依赖于基于文本的音素转换和声学特征生成的繁琐流程,而VALL-E 模型则以一种更直观的方式解决这一问题。
在采用语音编解码的核心思想下,VALL-E 模型将语音信号编码为中间表示,具有重要的抽象性和信息丰富性。这一中间表示不仅包含了语音的基本特征,还更为灵活地捕捉了文本中的各种语音信息,如音调、语速等。通过引入这个中间表示的概念,VALL-E 模型的语音合成过程更接近人类语音产生的方式,使得生成的语音更加自然、高质量。
2.2 VALL-E 如何利用语音编解码技术进行文本到语音的合成
VALL-E 模型的文本到语音合成过程主要经历两个关键步骤:编码和解码。
在编码阶段,模型接收文本输入并通过先进的神经网络结构将其转换为中间语音编码。这一编码过程的目标是将文本中的语音特征抽象为一种中间表示,以便后续解码器更好地理解和还原。通过深度学习的方式,VALL-E 模型能够在这个阶段捕获文本的丰富信息,为最终语音生成奠定基础。
在解码阶段,模型将中间语音编码还原为自然语音。解码器在这一过程中扮演着关键的角色,通过将中间表示解码为音频波形,完成了从文本到语音的转换。这一解码过程的精密性和准确性直接影响着最终语音的质量。通过优化解码器的设计,VALL-E 模型保证了生成语音在保持语义准确性的同时,能够表达文本所蕴含的各种语音细节。
通过紧密结合编码和解码的过程,VALL-E 模型以前所未有的方式利用语音编解码技术进行文本到语音的合成。这种新颖的方法不仅提高了合成的灵活性和表现力,还使模型能够更好地适应多样的语音合成任务和输入条件。这标志着语音合成技术在VALL-E 模型的引领下迈入了一个更加智能、自然的时代。
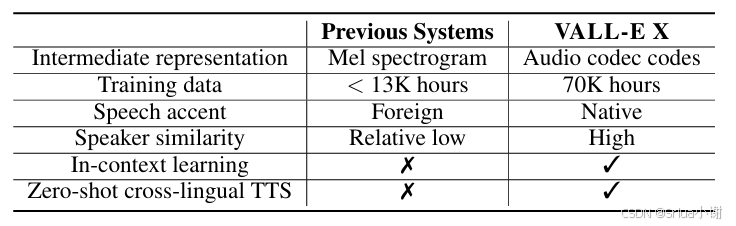
VALL-E X与先前跨语音TTS系统的比较
3. 训练和优化
3.1 VALL-E 模型的预训练过程
VALL-E 模型作为一项领先的语音合成技术,其预训练过程扮演着至关重要的角色。在这一阶段,模型通过学习大规模的语音数据,以无监督的方式获取语音的基本特征和结构。这一预训练的过程采用了 LibriLight 数据集,这个数据集包含了 60,000 小时的丰富语音素材,为模型提供了广泛的语音输入。
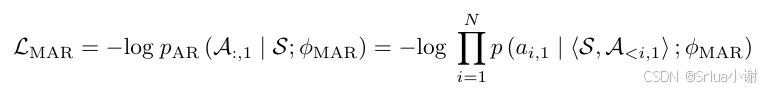
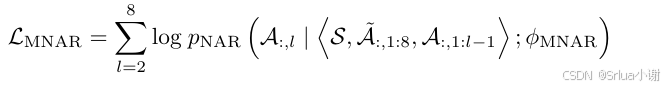
预训练的目标是将语音信号转换为中间表示,即语音编码。通过编码的方式,模型能够在不同说话人、语速、语调等情境下更好地捕捉语音的抽象特征。这种中间表示的引入是 VALL-E 模型设计的创新之一,为后续的任务提供了有力的基础。预训练过程中,VALL-E 利用了先进的神经网络结构,通过多层的注意力机制和嵌入层,提高了模型对语音信息的表征能力。
3.2 模型是如何在大规模语音数据上进行训练的
在预训练完成后,VALL-E 模型通过在大规模语音数据上进行进一步的训练,不断优化其参数,以更好地适应语音合成任务。训练数据来自 LibriLight 数据集,这个数据集的广泛覆盖确保了模型能够处理不同场景、说话人和语音特征。
在训练过程中,VALL-E 模型充分利用了计算资源,使用了 16 个 NVIDIA TESLA V100 32GB GPU 进行协同训练。每个 GPU 处理 6,000 个声学标记的批次,为了达到更好的泛化效果,模型总共进行了 800,000 次迭代。在这个过程中,采用了 AdamW 优化器,通过学习率的渐变升高和线性衰减,使模型能够更好地收敛到全局最优点。
在模型的训练中,引入了先进的神经网络结构,模型核心采用了语音编解码技术。这种技术的应用不仅提高了模型对语音信息的建模能力,也使得模型在不同输入条件下更加灵活。通过结合编码和解码的方式,模型能够更好地处理文本到语音的转换任务,使生成的语音更加自然。
3.3 突出 VALL-E 在零样本学习中的优化策略
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1310
1310

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









