 OpenFold2.0基于NPU的推理适配测试
OpenFold2.0基于NPU的推理适配测试





摘要
OpenFold是一种基于深度学习的蛋白质结构预测模型,广泛应用于蛋白质从头预测、功能位点解析、突变效应模拟等领域。该模型的核心目标是通过大规模预训练和多阶段优化,从氨基酸序列中高效、准确地推断蛋白质的三维结构。OpenFold结合了Transformer架构和几何优化模块,显著提高了结构预测的精度和速度。该模型的部署包含详细的微调教程、模型训练、推理优化等内容,为研究人员提供了全面的技术支持。
OpenFold介绍
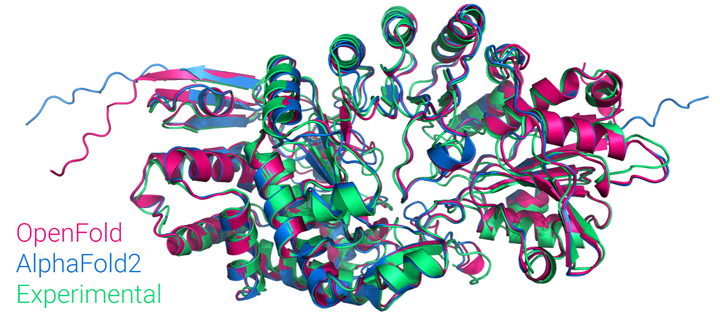
OpenFold是由DeepMind团队开发的一种高效蛋白质结构预测模型。该模型在AlphaFold2的基础上进行了多项改进,进一步提升了蛋白质结构预测的准确性和计算效率。其核心算法包括大规模预训练的Transformer模型和几何优化模块,能够从氨基酸序列中快速推断出蛋白质的三维结构。通过多阶段优化和大规模数据集的训练,该模型在蛋白质从头预测、功能位点解析、突变效应模拟等领域展现了卓越的性能。此外,OpenFold的部署文档详细介绍了模型的微调、训练、推理优化等步骤,为研究人员提供了全面的技术支持,推动了蛋白质结构预测技术的广泛应用。
OpenFold网络架构
OpenFold的模型架构由三个核心模块构成:输入嵌入层、Evoformer堆叠模块和结构解码器。输入数据整合了多序列比对(MSA)、模板特征、氨基酸序列及进化信息,形成高维生物特征张量。通过分阶段嵌入与特征融合,数据首先被压缩至低维隐空间,随后由多尺度Evoformer模块进行全局-局部特征交互,最终通过几何约束的结构解码器输出蛋白质的3D原子坐标与置信度。
环境搭建
#下载安装包
wget https://repo.anaconda.com/archive/Anaconda3-2024.10-1-Linux-aarch64.sh
c 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1595
1595

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









