




摘要
准确高效的潮流 (PF) 分析对于现代电网的运行和规划至关重要。因此,我们需要一种可扩展的算法,能够为小型和大型电网提供准确、快速的解决方案。由于电网可以理解为一张图,图神经网络 (GNN) 已成为一种颇具前景的方法,它通过利用底层图结构中的信息共享来提高 PF 近似的准确性和速度。在本研究中,我们介绍了 PowerFlowNet,这是一种用于 PF 近似的新型 GNN 架构,其性能与传统的牛顿-拉夫逊法相似,但在 IEEE 14 节点系统中,其速度提高了 4 倍,在法国高压电网 (6470rte) 的实际案例中,其速度提高了 48 倍。同时,它在性能和执行时间方面显著优于其他传统近似方法,例如直流潮流;因此,PowerFlowNet 将成为实际 PF 分析中极具前景的解决方案。此外,我们通过深入的实验评估验证了该方法的有效性,全面考察了 PowerFlowNet 的性能、可扩展性、可解释性和架构可靠性。此次评估深入了解了 GNN 在电力系统分析中的行为和潜在应用
1. 介绍
PowerFlowNet是由代尔夫特理工大学和荷兰应用科学研究组织开发的一种基于深度学习的新一代智能流体模拟模型,专注于高效预测复杂流体运动与多物理场耦合现象。该模型通过融合卷积神经网络(CNN)与物理约束模块,显著提升了流体仿真的计算效率与精度,广泛应用于工程流体力学、气象预测、航空航天设计等领域。PowerFlowNet采用自适应网格优化和并行计算技术,能够在保持高分辨率模拟的同时降低计算资源消耗。其开源框架提供从数据预处理、模型训练到实时推理的全流程工具链,为科研与工业界提供了可扩展的流体模拟解决方案。
2. 网络架构
PowerFlowNet 是一种 GNN 方法,它根据问题的部分信息(例如图 𝐴 的邻接矩阵、已知节点特征 ![]() (其中未知特征填充为 0)以及每条线 (𝑖, 𝑗) ∈的边特征
(其中未知特征填充为 0)以及每条线 (𝑖, 𝑗) ∈的边特征 ![]() ,重建每个节点的完整特征向量
,重建每个节点的完整特征向量![]() 。我们提出的模型由一个掩码编码器和一堆我们新颖的 Power Flow 卷积层 (PowerFlowConv) 组成。首先,掩码编码层使用特征掩码对输入特征进行移位,以区分已知和未知特征。然后,如图 1所示,编码后的图特征被输入到由独特排列的消息传递层和 TAGConv 层组成的 Power Flow 卷积运算堆栈中。这样,来自每个节点和边的信息都会被聚合,从而预测完整的特征矩阵
。我们提出的模型由一个掩码编码器和一堆我们新颖的 Power Flow 卷积层 (PowerFlowConv) 组成。首先,掩码编码层使用特征掩码对输入特征进行移位,以区分已知和未知特征。然后,如图 1所示,编码后的图特征被输入到由独特排列的消息传递层和 TAGConv 层组成的 Power Flow 卷积运算堆栈中。这样,来自每个节点和边的信息都会被聚合,从而预测完整的特征矩阵 ![]() 。
。
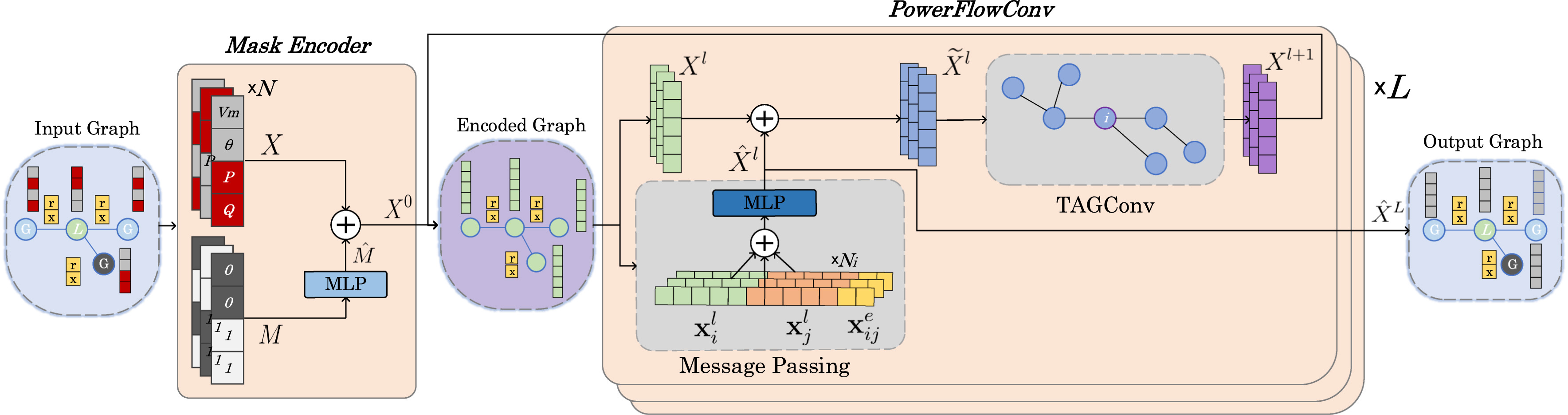
图1:PowerFlowNet 模型架构由一个掩码编码器和 𝐿 PowerFlowConv 层组成。包含不完整特征信息的输入图被逐个节点地输入到掩码编码器,以生成编码后的图特征,其中每个节点 𝑛 ∈ 𝑁,且 (𝒙𝑖, 𝒎𝑖)。然后,编码后的图特征由一系列 𝐿 顺序 PowerFlowConv 层处理,每个层包含一个单步消息传递和一个高阶 TAGConv。最终生成完整的输出图。
2.1 掩码编码器
在 PF 问题中,每个节点都有不同的已知和未知特征。目标是在保持已知特征不变的情况下预测未知特征。这意味着我们的神经网络应该知道哪些特征需要预测。因此,对于每个具有特征向量 𝒙𝑖 的输入节点,我们创建一个二元掩码 ![]() ,其中 0 表示已知特征,1 表示未知特征。例如,一个负载 (PQ) 节点的特征向量
,其中 0 表示已知特征,1 表示未知特征。例如,一个负载 (PQ) 节点的特征向量![]() 和未知值 𝑉𝑚 和 𝜃,其掩码为 𝒎𝑖 = (1, 1, 0, 0)。此外,我们建议使用一个能够学习表示不同类型节点的掩码编码器(参见图1中的掩码编码器模块)。实际上,它由两个全连接层组成,将二值掩码映射到连续值向量。值得注意的是,也可以使用固定的(非学习的)掩码嵌入,但我们的掩码编码器可以学习更灵活的掩码表示,从而提升最终性能。对于每个
和未知值 𝑉𝑚 和 𝜃,其掩码为 𝒎𝑖 = (1, 1, 0, 0)。此外,我们建议使用一个能够学习表示不同类型节点的掩码编码器(参见图1中的掩码编码器模块)。实际上,它由两个全连接层组成,将二值掩码映射到连续值向量。值得注意的是,也可以使用固定的(非学习的)掩码嵌入,但我们的掩码编码器可以学习更灵活的掩码表示,从而提升最终性能。对于每个 ![]() ,其中
,其中![]() ,
,![]() ,这是一个函数
,这是一个函数![]() ,权重矩阵
,权重矩阵![]() 和偏差
和偏差![]() 是可训练参数。最后,为了生成编码图特征
是可训练参数。最后,为了生成编码图特征![]() ,我们将输入节点特征𝑋与学习到的表示𝒎̂𝑖进行平移,即
,我们将输入节点特征𝑋与学习到的表示𝒎̂𝑖进行平移,即![]() 。
。
2.2 功率流卷积层
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 17万+
17万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









