




Robotic Arm Representation Using Image-Based Feedback for Deep Reinforcement Learning
1. 摘要
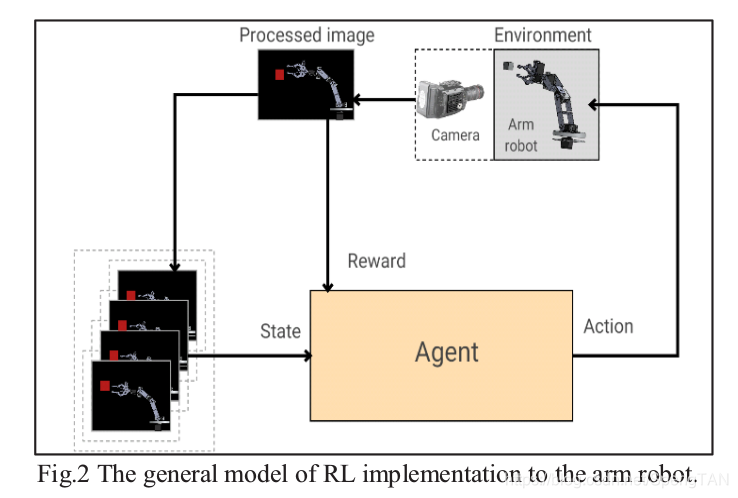
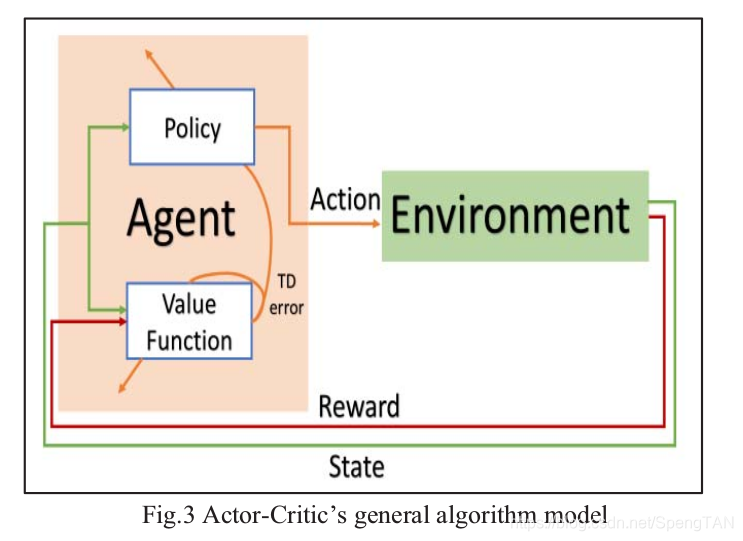
This paper presents a technique that uses feedback images for implementing a robotic task using Deep Reinforcement Learning (DRL). The agent (controller) type is Actor-Critic that uses Temporal- Difference (TD) to gain knowledge about the environment (plant). The representation of the robot is implemented in the V-Rep simulator.
本文提出了一种使用反馈图像通过深度强化学习(DRL)来实现机器人任务的技术。 Agent(控制器)类型是Actor-Critic,它使用时间差异(TD)来获取有关环境(plant)的知识。 机器人的表示在V-Rep仿真器中实现。
2. 方案


















 2667
2667

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









