



文章目录
本文是笔者进行神经网络学习的个人学习日记
图片和链接均源自网络,侵删
1 RNN网络结构
RNN作为循环神经网络的基础结构,只能对短期的内容进行记忆,但是是不得不学的。相对于普通的FCNN,它更关注时间序列,随着时间的推进,不断有新的输入加入到RNN中,而每次经过计算后的输出值,会作为部分输入参与到下一个节点的计算中。如下图:
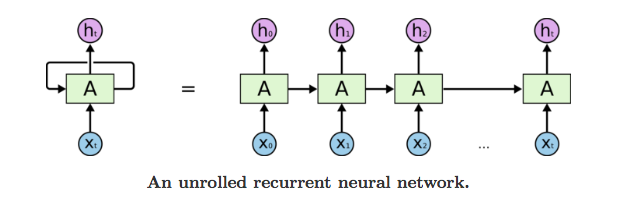
在标准的RNN中,每个神经元中都只有一个简单的结构,例如一个Sigmoid层或一个Tanh层,将输入变换为(0, 1)或(-1, 1)上的输出,公式如下:
σ
(
x
)
=
1
1
+
exp
(
−
x
)
t
a
n
h
(
x
)
=
e
x
−
e
−
x
e
x
+
e
−
x
\sigma(x)=\frac{1}{1+\exp(-x)}\quad tanh(x)=\frac{e^x-e^{-x}}{e^x+e^{-x}}
σ(x)=1+exp(−x)1tanh(x)=ex+e−xex−e−x
深度学习之RNN(循环神经网络):https://blog.youkuaiyun.com/qq_32241189/article/details/80461635
Pytorch循环神经网络(RNN)快速入门与实战:https://blog.youkuaiyun.com/weixin_45727931/article/details/114369073
2 长短时记忆网络(LSTM)
长短时记忆网络,相较于普通的RNN,它解决了短期依赖的问题。LSTM的关键在于细胞状态,它是贯穿于细胞上方的水平线,只存在一些少量的线性交互,信息在上面流传时保持相对小的变化。
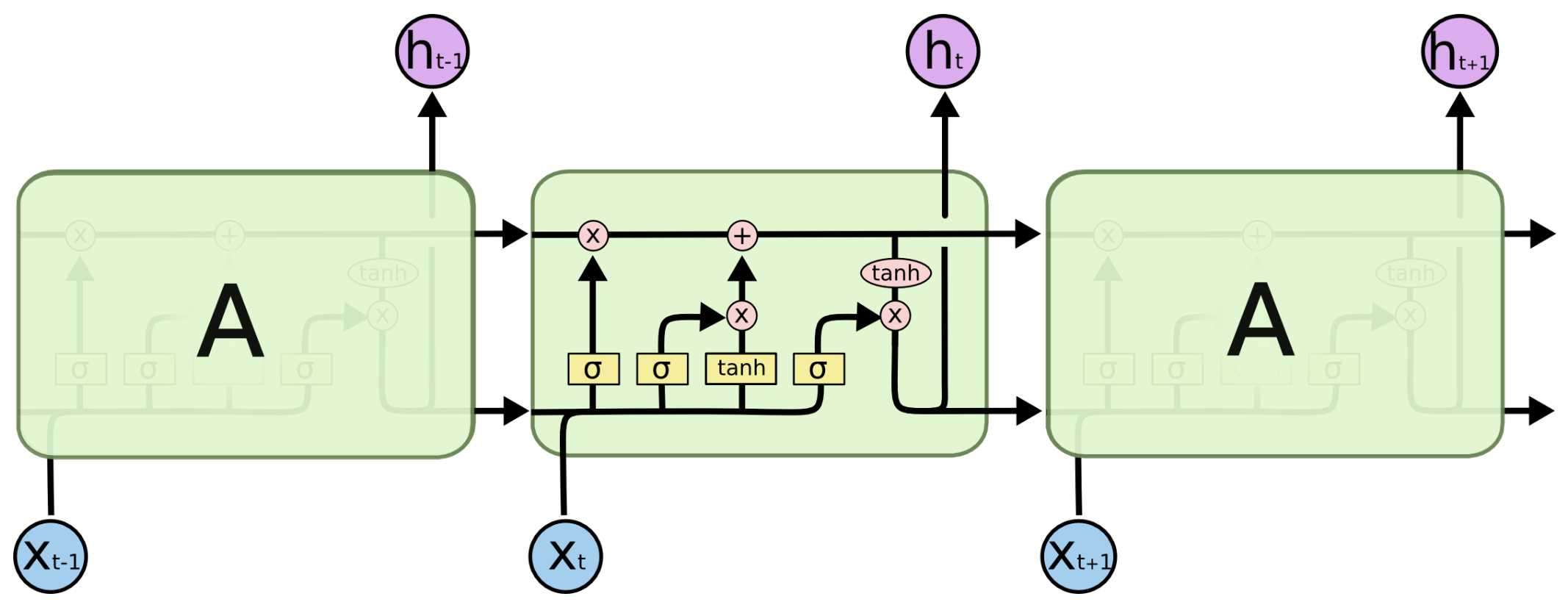
如上图所示,LSTM拥有三种类型的门结构:忘记门、输入门和输出门,来保护和控制细胞状态。
2.1 忘记门
忘记门在LSTM神经元中的位置如下图所示。它会读取上一个神经元的输出
h
t
−
1
h_{t-1}
ht−1和当前输入
x
t
x_t
xt,经过一个简单的sigmoid层,输出一个
f
t
f_t
ft,即:
f
t
=
σ
(
W
f
h
h
t
−
1
+
W
f
x
x
t
+
b
f
)
f_t=\sigma(W_{fh}h_{t-1}+W_{fx}x_t+b_f)
ft=σ(Wfhht−1+Wfxxt+bf)。
而这个输出 f t f_t ft会与上一个神经元输出的细胞状态 C t − 1 C_{t-1} Ct−1相乘,由于 f t f_t ft的值在0到1之间,与原先的细胞状态相乘后,相当于忘记了一定程度 C t − 1 C_{t-1} Ct−1的内容。
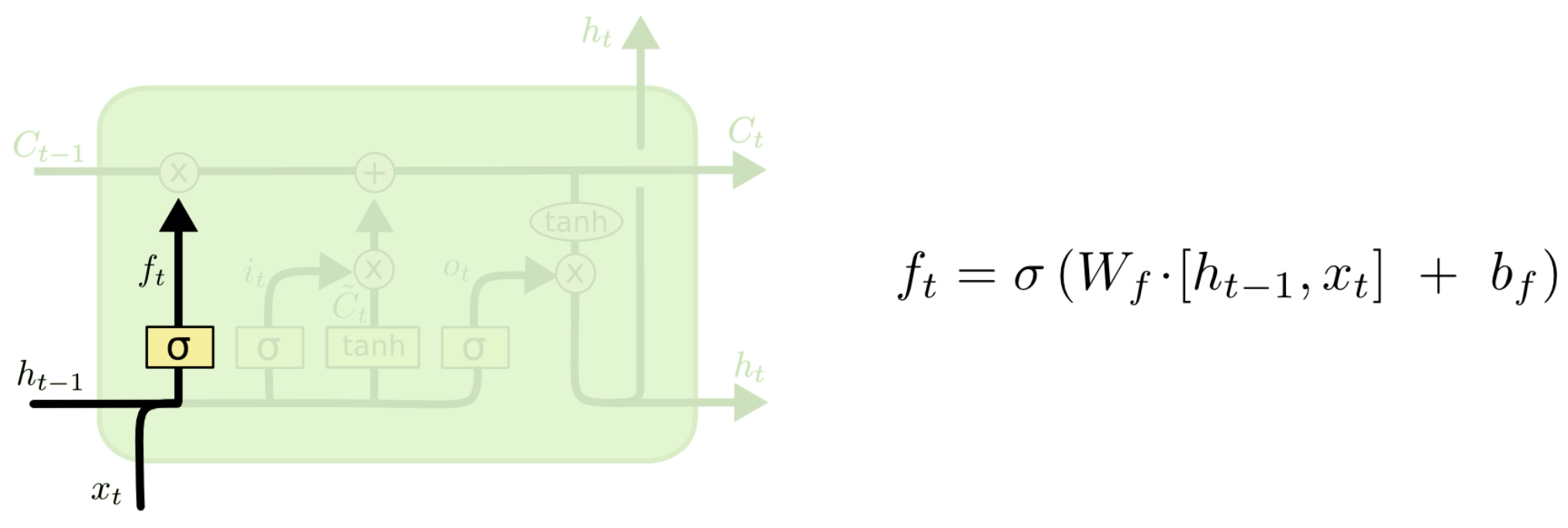
例如,在语言处理中,我们假设原先的细胞状态 C t − 1 C_{t-1} Ct−1可能保存着当前主语的信息(如性别等),而当我们看到新的主语时,我们希望丢弃原先的主语信息,防止干扰后续信息的正常流传。
2.2 输入门
输入门在LSTM神经元中的位置如下如所示。输入值通过Tanh层产生新的候选值向量 C ~ t \tilde{C}_t C~t,它会经过与Sigmoid层产生的 i t i_t it相乘,Sigmoid层决定了我们需要更新什么值(即 i t × C ~ t i_t\times\tilde{C}_t it×C~t),最后,这个值会加入到细胞状态中。
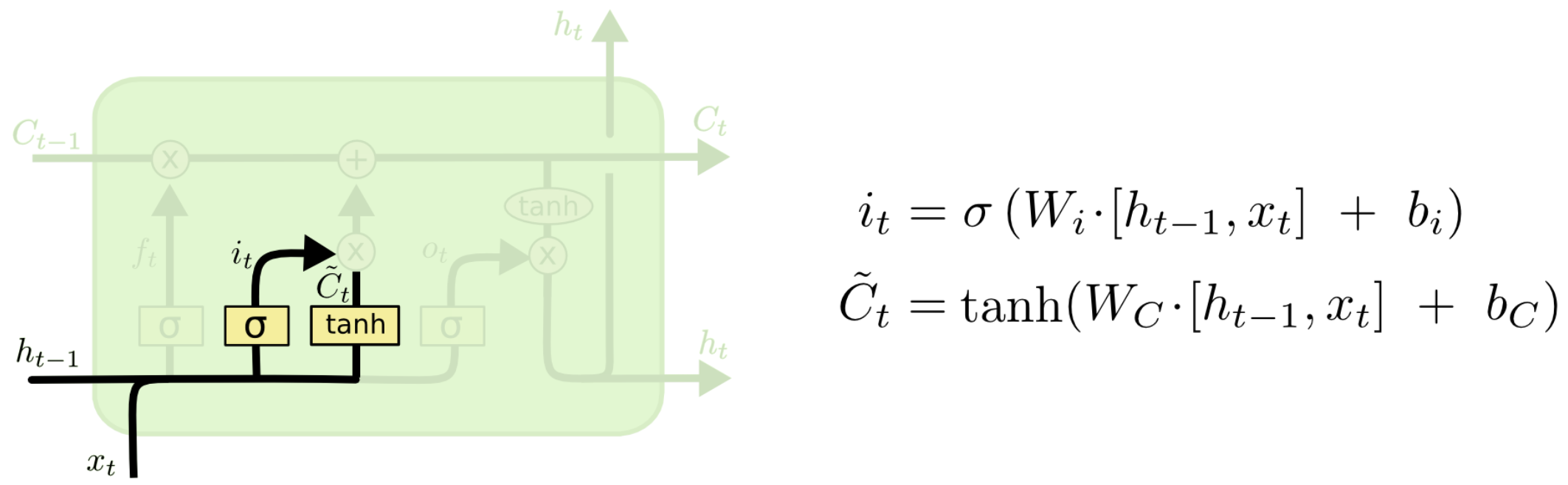
类比到上面的例子中,当我们丢弃了原先的主语信息后,我们需要把新的主语信息加入到细胞状态中,来代替原先的信息。
2.3 输出门
经过上面的变化,我们已经得到了新的细胞状态
C
t
C_t
Ct,即:
C
t
=
f
t
×
C
t
−
1
+
i
t
×
C
~
t
C_t=f_t\times C_{t-1}+i_t\times\tilde{C}_t
Ct=ft×Ct−1+it×C~t
而新的细胞状态将会有一部分要作为输出,这部分通过Sigmoid层来决定。我们将细胞状态
C
t
C_t
Ct经过Tanh层处理后,与Sigmoid门产生的
o
t
o_t
ot相乘,产生了我们需要输出的
h
t
h_t
ht。
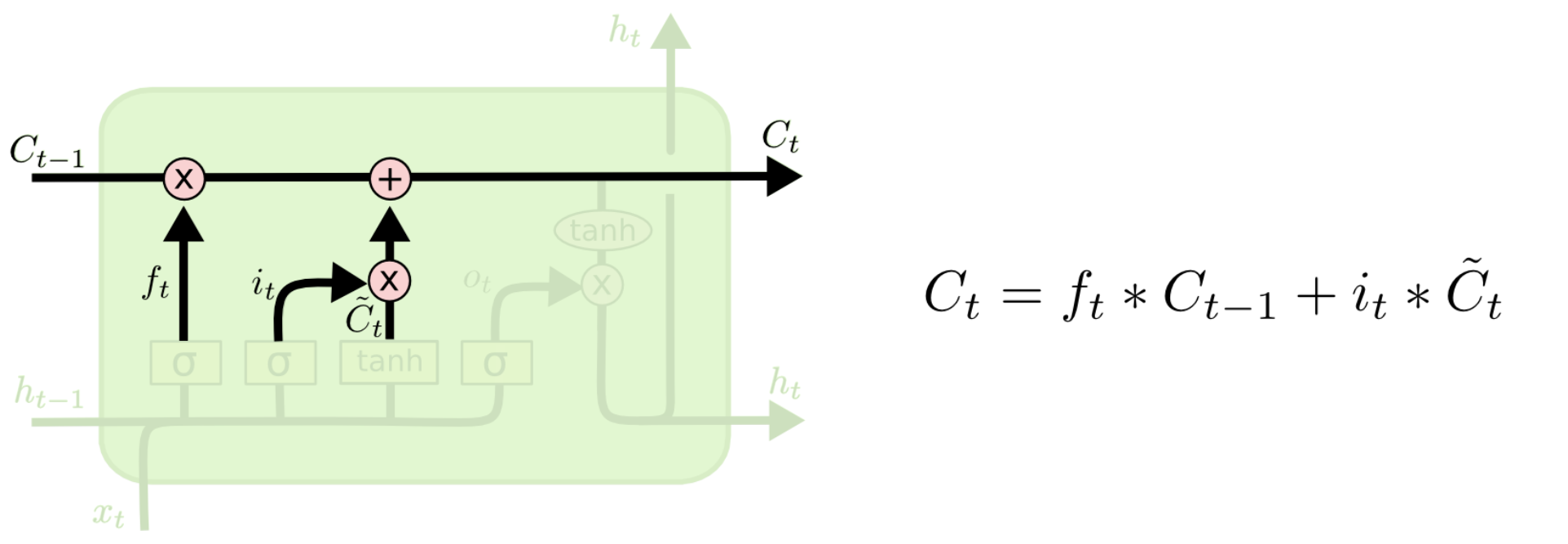
同样类比到上面的例子,这个输出的部分可能包含了一些主语之外的其他信息,需要通过细胞状态进行推断。
最后,这里还有两张图,但不适合放在这里,就放两个超链接吧:LSTM详细结构图和LSTM结构动图。
如何从RNN起步,一步一步通俗理解LSTM:https://blog.youkuaiyun.com/v_JULY_v/article/details/89894058
Pytorch LSTM实现中文单词预测(附完整训练代码):https://blog.youkuaiyun.com/guyuealian/article/details/128582675
时间序列预测——LSTM模型(附代码实现):https://blog.youkuaiyun.com/weixin_52910499/article/details/124693212
3 双向长短时记忆网络(BiLSTM)
BiLSTM指的是双向LSTM,从上面LSTM的介绍中我们也可以看出,单向的循环神经网络结构模型实际上只是不断参考“上文”和“当前”的信息,而没有考虑到“下文”的信息。在实际语言分析中,我们有可能会需要结合上下文内容,因此,我们有了双向长短时记忆网络。其最终的输出的结果为正向的LSTM结果与反向LSTM结果的简单堆叠。
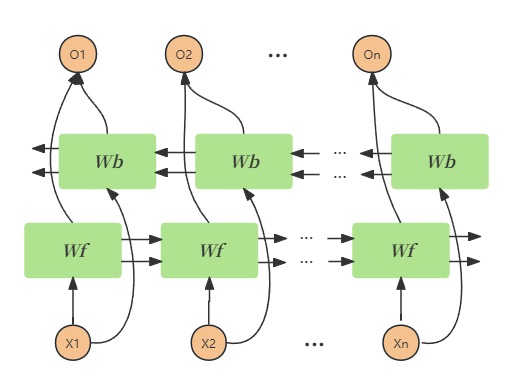
Pytorch实战笔记(1)——BiLSTM 实现情感分析:https://blog.youkuaiyun.com/qq_35357274/article/details/128701233
一幅图真正理解LSTM、BiLSTM:https://blog.youkuaiyun.com/weixin_42118657/article/details/120022112
4 门控神经网络(GRU)
GRU是门控神经网络(Gate Recurrent Units),它与LSTM最大的不同在于GRU将忘记门和输入门合并了,组成了一个“更新门”。
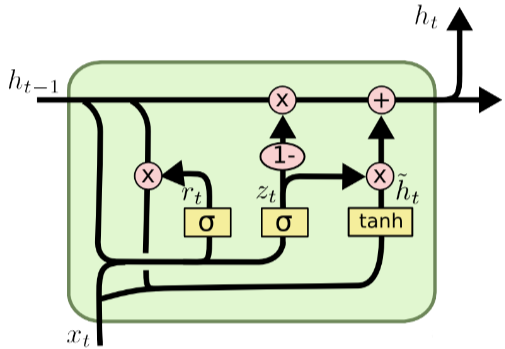
GRU有两个输入端,分别是当前时刻的输入 x r x_r xr和前一时刻的隐藏状态 h t − 1 h_{t-1} ht−1。从左到右三个激活函数分别控制着重置门( r t r_t rt)、更新门( z t z_t zt)和候选隐藏状态( h ~ t \widetilde h_t h t),下面分别介绍。
4.1 重置门( r t r_t rt)
重置门决定了有多少过去的信息需要遗忘,计算公式为:
r
t
=
σ
(
W
r
x
t
+
U
r
h
t
−
1
+
b
r
)
r_t=\sigma(W_rx_t+U_rh_{t-1}+b_r)
rt=σ(Wrxt+Urht−1+br)
其中,
W
r
W_r
Wr和
U
r
U_r
Ur分别为输入和前一时刻隐藏状态到重置门的权重矩阵,
b
r
b_r
br为偏置项。
4.2 更新门( z t z_t zt)
更新门决定了有多少过去的信息将要被传递到未来,计算公式为:
z
t
=
σ
(
W
z
x
t
+
U
z
h
t
−
1
+
b
z
)
z_t=\sigma(W_zx_t+U_zh_{t-1}+b_z)
zt=σ(Wzxt+Uzht−1+bz)
其中,
W
z
W_z
Wz和
U
z
U_z
Uz分别为输入和前一时刻隐藏状态到更新门的权重矩阵,
b
t
b_t
bt为偏置项。
4.3 候选隐藏状态( h ~ t \widetilde h_t h t)
该部分基于当前输入和经过重置门调整后的前一时刻隐藏状态计算得到,是更新隐藏状态的候选,计算公式为:
h
~
t
=
tanh
(
W
h
x
t
+
U
h
(
r
t
⊙
h
t
−
1
)
+
b
h
)
\widetilde h_t=\text{tanh}(W_hx_t+U_h(r_t\odot h_{t-1})+b_h)
h
t=tanh(Whxt+Uh(rt⊙ht−1)+bh)
其中,
⊙
\odot
⊙表示元素乘法(Hadamard乘积)。
4.4 最终隐藏状态( h t h_t ht)
通过更新门得到的
z
t
z_t
zt对前一时刻隐藏状态
h
t
−
1
h_{t-1}
ht−1和候选隐藏状态
h
t
h_t
ht加权组合,得到当前时刻最终隐藏状态:
h
t
=
(
1
−
z
t
)
⊙
h
t
−
1
+
z
t
⊙
h
~
t
h_t=(1-z_t)\odot h_{t-1}+z_t\odot\widetilde h_t
ht=(1−zt)⊙ht−1+zt⊙h
t
门控循环单元不会随时间而清除以前的信息,它会保留相关的信息并传递到下一个单元,因此它利用全部信息而避免了梯度消失问题。
【Pytorch学习笔记十二】循环神经网络(RNN)详细介绍(常用网络结构及原理):https://blog.youkuaiyun.com/QH2107/article/details/126706353
个人神经网络学习日记:
【神经网络学习日记(1)】神经网络基本概念
【神经网络学习日记(2)】全连接神经网络(FCNN)及Pytorch代码实现
【神经网络学习日记(3)】卷积神经网络(CNN)
【神经网络学习日记(4)】循环神经网络(RNN、LSTM、BiLSTM、GRU)
【神经网络学习日记(5)】数据加载器(DataLoader)的调用
【神经网络学习日记(6)】Transformer结构详解
【神经网络学习日记(7)】Transformer的应用(BERT、Longformer、LLM)
【神经网络学习日记(8)】一些图神经网络的简单介绍(GCN、GAT、rGCN)
文中引用部分都尽可能写出了,如果有侵犯其他人文章版权的问题,请务必联系我,谢谢!



















 3526
3526

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}