







前言
RNN擅长解决的问题是连续的序列,且序列的长短不一,比如基于时间的序列:一段段连续的语音等。这些序列比较长,且长度不一,比较难直接拆分成一个个独立的样本通过DNN/CNN进行训练。
而RNN由于其独有的结构和优势,能够处理DNN/CNN所不能及的问题。
RNN的5种不同架构
声明:下列图中的方块或者圆圈都代表一个向量。
one2one:
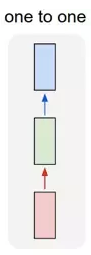
一个输入对应一个输出。
one2many:

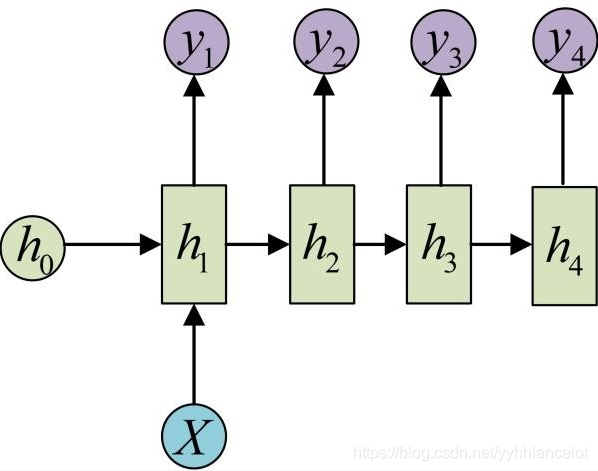
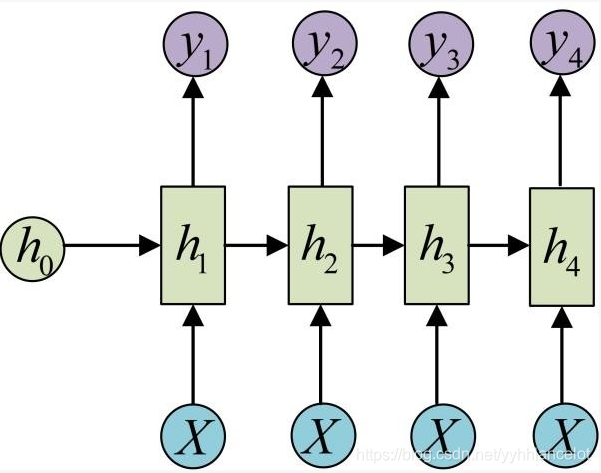
一个输入对应多个输出,这个架构多用于图片的对象识别,即输入一个图片,输出一个文本序列(来阐述这个图片)。
many2one:
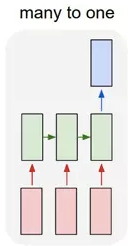
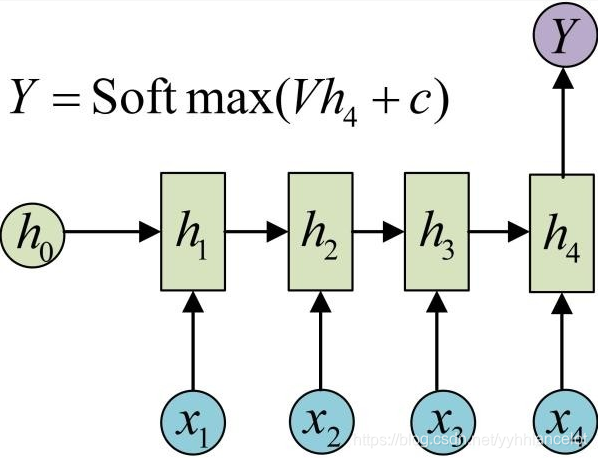
多个输入对应一个输出,多用于文本分类或视频分类,即输入一段文本或视频片段,输出类别。
N2N
这是最经典的RNN结构
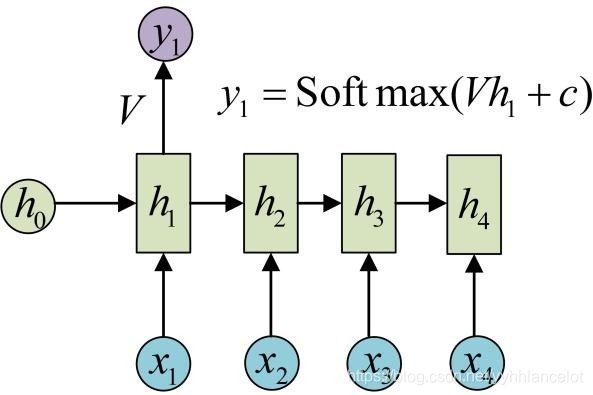
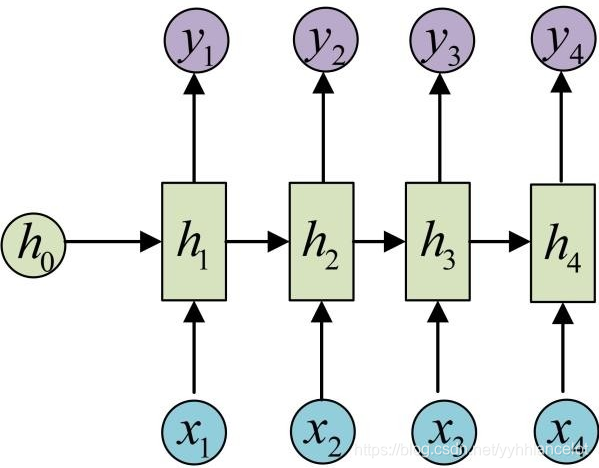
从这里可以看出,它要求序列的输入输出是等长的。
N2M / Encoder-Decoder / Seq2Seq:
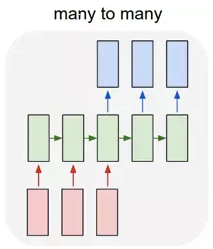
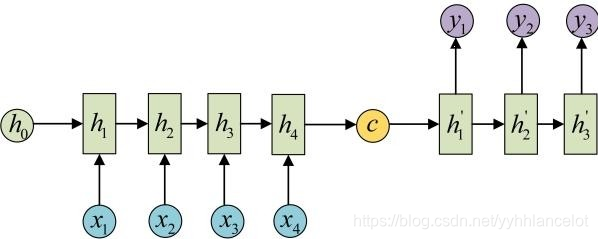
这种结构是RNN最重要的一个变种,广泛用于机器翻译,输入一个文本,输出另一种语言的文本。文本摘要,输入一段文本序列,输出这段文本序列的摘要序列。阅读理解,将输入的文章以及答案分别进行编码,最后再对其进行解码得到答案。语音识别,输入语音信号,输出的是文字序列。这里已经没有N2N序列等长的要求,在后面会进一步对该种模型进行阐述。
RNN模型与前向传播
RNN是基于序列的,它对应的输入为对应的样本序列中的时间步t对应的
。而
代表t位置的隐藏状态,由
和t-1位置的隐藏状态
决定。
主流模型如下图

这些循环使RNN可以被看做同一个网络在不同时间步的多次循环,每个神经元会把更新的结果传递到下一个时间步。这就是RNN的正向传播,依次按照时间的顺序计算一次即可。
和
分别代表序列时间步t-1和t+1时训练样本的输入。
对任意一个序列时间步t,隐藏状态由
和
得到:
.................................... (0)
为激活函数,这里一般为tanh或者Relu,b为偏置。这个公式就可以理解为
,现有的输入+过去的记忆,也正是由于这个,使RNN具有了记忆能力。
这里处采用Pascanu等人的论文On the difficulty of training Recurrent Neural Networks中的定义,即认为
........................................ (1)
这两种方法其实是等价的,只是前一种表述把隐层状态定义成激活后的值,后一种表述把隐层定义成激活前的值,这里采用后一种方式是因为它稍微好算一点。
U:输入层到隐藏层直接的权重
W:隐藏层到隐藏层的权重
V:隐藏层到输出层的权重
U,W,V这三个矩阵是模型的线性关系参数,在整个RNN网络的每一步中是共享的,也正是因为共享,才体现了RNN模型的“循环反馈”的思想。
输出的表达式比较简单:
最终在时间步t时我们预测输出为:
通常RNN是分类模型,所以这里的激活函数一般是softmax/sigmoid。
误差函数可以量化模型当前损失,比如交叉熵损失函数或平方误差,即
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









