



原文论文:MambaIRv2: Attentive State Space Restoration
作者:Hang Guo, Yong Guo, Yaohua Zha, Yulun Zhang, Wenbo Li, Tao Dai, Shu-Tao Xia, Yawei Li;
项目开源链接:csguoh/MambaIR: [ECCV2024, CVPR2025] MambaIR and MambaIRv2!
https://github.com/csguoh/MambaIR
一、引言
在图像修复领域,Mamba 凭借 “全局视野 + 高效计算” 的优势崭露头角,但它有个致命短板 —— 只能依赖扫描序列里的前置像素,没法用全图信息。而《MambaIRv2:Attentive State Space Restoration》中提出的 MambaIRv2,用两个关键设计帮 Mamba 补上了这个漏洞,在超分、去噪等任务里又快又好。本文将解读这篇CVPR 论文,解析其在图像修复任务中如何在保持高效计算的同时,解决 Mamba 的因果建模限制。
二、先搞懂:传统 Mamba 在图像修复的 缺陷
要明白 MambaIRv2 的价值,得先看清传统 Mamba 的问题。Mamba 处理图像时,会先将 2D 图像按固定规则(如从左到右、从上到下)扫描为 1D 序列,再通过离散状态空间方程建模像素间的交互,公式如下:
其中:
-
是第i个像素的隐藏状态,
是第i个像素的输入特征;
-
是控制矩阵(负责传递历史隐藏状态),
是输入矩阵(将输入特征融入隐藏状态);
-
C是输出矩阵(将隐藏状态转化为输出),D是直接映射项(补充输入特征)
这个公式暴露了 Mamba 的 “因果缺陷”:第i个像素的隐藏状态,完全依赖前一个像素的隐藏状态
,后续未扫描的像素信息完全无法利用。这直接导致三个问题:
-
信息利用不全:比如修复图片右侧的线条,Mamba 看不到右边没扫的像素,只能靠猜,修复效果自然差;
-
多扫还浪费:为了 “看全”,大家会让 Mamba 多扫几次(比如上下左右四个方向),但论文实验显示,不同方向的扫描结果相似度超 70%(如图1),相当于做重复功,计算量还翻倍;
-
远像素 “断联”:就算是前面扫过的像素,只要距离远,Mamba 也没法有效利用 —— 它的核心参数会让远距离像素的交互变弱(如图2,控制矩阵数值小于 1),有用信息接不上。
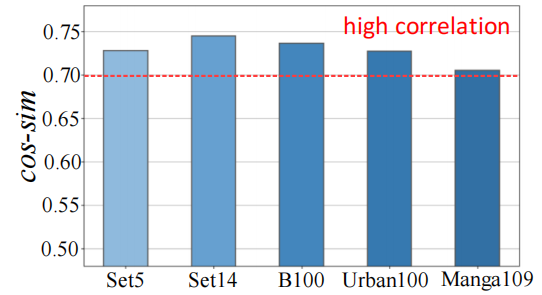
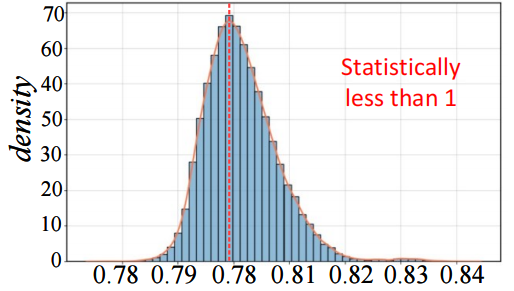
三、MambaIRv2 的核心改进:两大模块优化
MambaIRv2 的核心思路是 “给 Mamba 注入非因果能力”,通过注意力状态空间方程(ASE) 和语义引导邻域(SGN) 实现,其中 ASE 的公式改进是关键。
1. ASE 模块:让 Mamba “看见全图”
ASE 的核心是改造传统 Mamba 的输出矩阵C,通过提示学习(Prompt Learning) 融入全图信息,让输出矩阵具备 “查询” 未扫描像素的能力,对应的注意力状态空间方程如下:
其中P是实例专属提示,直观地说,它就像是一份“全局参考指南”:
当模型在扫描某个像素时,可以根据 P提供的全局信息,快速了解“整张图像中哪些区域与当前像素语义相似”。
对比传统公式,最大变化是将输出矩阵改为
,使ASE 在输出阶段引入了一个动态的“全图补偿项”P,让每个像素在生成输出时能够融合全局统计特征。换句话说,MambaIRv2 不需要改变状态递推结构,就能在输出时实现全图建模。它的设计包含三个关键步骤:
步骤 1:构建语义解耦的提示池
为让提示能代表全图相似像素,论文设计提示池(T为提示数量,d为 Mamba 隐藏状态维度),并通过语义解耦提升可解释性,公式如下:
-
N是所有模块共享的 “特征词典”,确保不同模块用统一的语义标准;
-
M是模块专属的 “组合系数”,让不同模块能灵活调用共享特征;
-
(r为内积维度),在保证效果的同时降低计算量。
这一步为模型建立了一个语义记忆库:将提示向量 P拆分为共享的语义基 N和模块专属组合系数 M。共享的语义基 N 提供固定的基础语义(如天空、纹理、边缘),而不同模块可以通过各自的组合系数 M自由组合这些基础语义,从而生成适合该模块的提示向量,使像素能够根据语义选择最合适的参考信息。
步骤 2:可微分的提示选择
所有的提示都需要基于当前的输入像素,要让每个像素匹配到对应的提示,论文通过 “路由矩阵” 实现可微分选择:
输入特征经线性层投影到 TTT 维后,通过 LogSoftmax 得到提示选择概率,再用 Gumbel-Softmax 采样生成独热路由矩阵 R,最终得到实例专属提示:
其中 R 表示每个像素选中的提示组合,这一步使每个像素根据自身特征决定参考哪类语义提示。
直觉解释:
假设图像中有大片蓝天区域,不同像素的局部状态可能不同,但它们都共享相似的全局语义(天空)。
通过路由矩阵,这些像素会选择同一个“天空提示”,从而在输出时共享全局一致的语义信息。
因此,提示选择相当于在输出层构建了跨像素的信息通道。
步骤 3:融入状态空间方程
最终将P通过残差连接加入C,形成—— 这一步相当于给每个像素的 “输出计算” 加了 “全图相似像素的信息标签”,让第i个像素能参考未扫描区域的同类像素,彻底打破因果限制,同时无需多方向扫描(仅需 1 次扫描即可)。
2. SGN 模块:缓解长距离衰减的 “序列重组”
传统 Mamba 的长距离衰减,本质是 “空间远的像素在 1D 序列中也远”,导致衰减快。SGN 的解决方案是按语义而非空间顺序重组序列,让相似像素在1D 序列中相邻:
-
复用 ASE 的路由矩阵R(已包含每个像素的提示类别,即语义标签);
-
通过 “SGN-unfold” 操作,将同一语义标签的像素归为一组,生成 “语义邻域序列”;
-
经 ASE 处理后,再通过 “SGN-fold” 逆操作还原为 2D 特征图(如图3展示流程)。
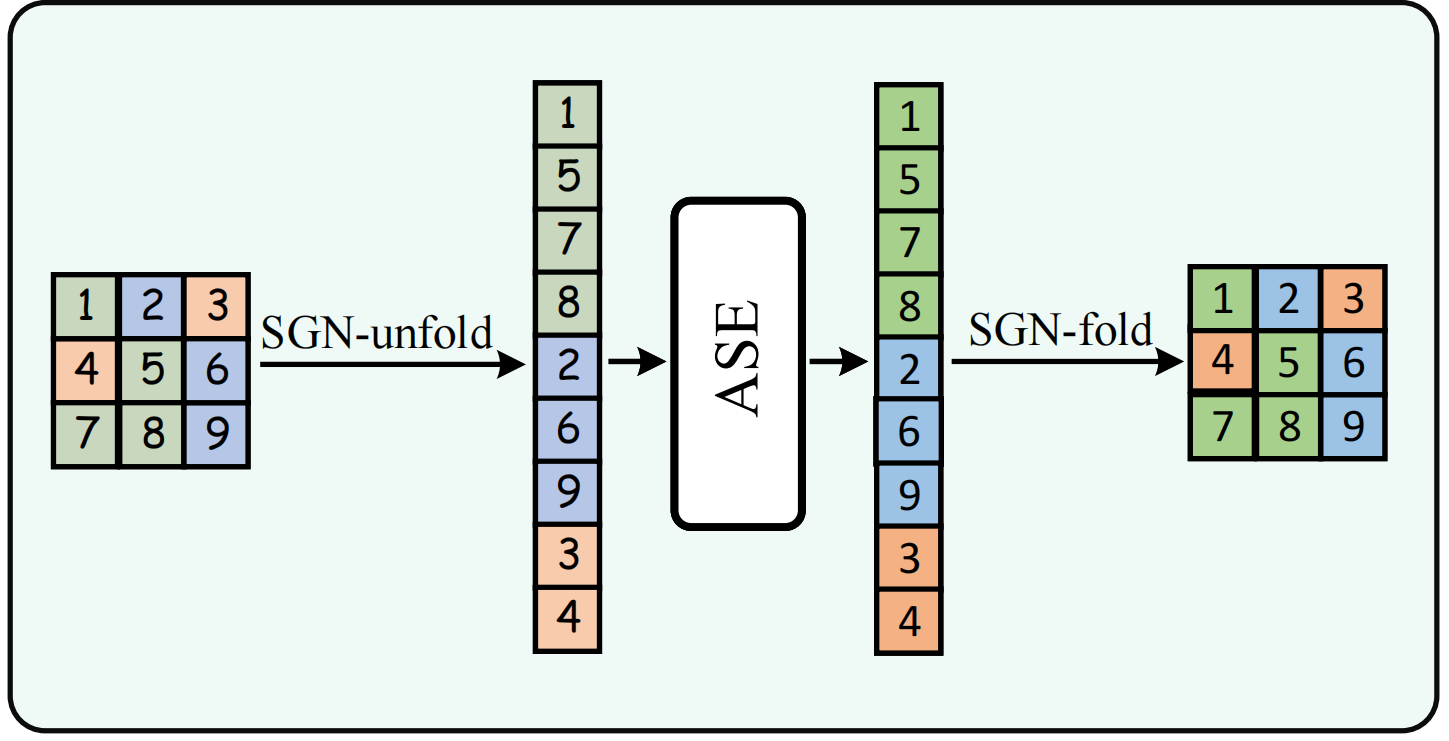
这一步无需复杂公式,核心是 “用语义顺序替代空间顺序”,让远处相似像素的距离k变小,衰减减弱,从而强化交互。
SGN-unfold 操作
将 2D 特征按语义类别重新排序:先为每个像素分配语义标签,再将相同类别的像素聚在一起按类别顺序展开为 1D 序列,使语义相似的像素在序列中相邻,从而缓解长距离衰减。对应逆操作为 SGN-fold,用于恢复空间结构。💭 思考与讨论
ASE 的作用是注入全局语义信息,对特征进行语义增强,那么初次执行时的 SGN-Unfold 是如何运作的?毕竟其顺序是先进行 Unfold 再经过 ASE。在第一次冷启动阶段,是否仅执行普通的展开操作,而不涉及语义重排?此外,ASSM 仅进行一次语义扫描——这一优势是否意味着语义重排的逐步完善依赖于多个 ASSB 的递进处理?
四、整体架构
MambaIRv2 的架构围绕 ASE 和 SGN 展开,ASSM由两者构成。
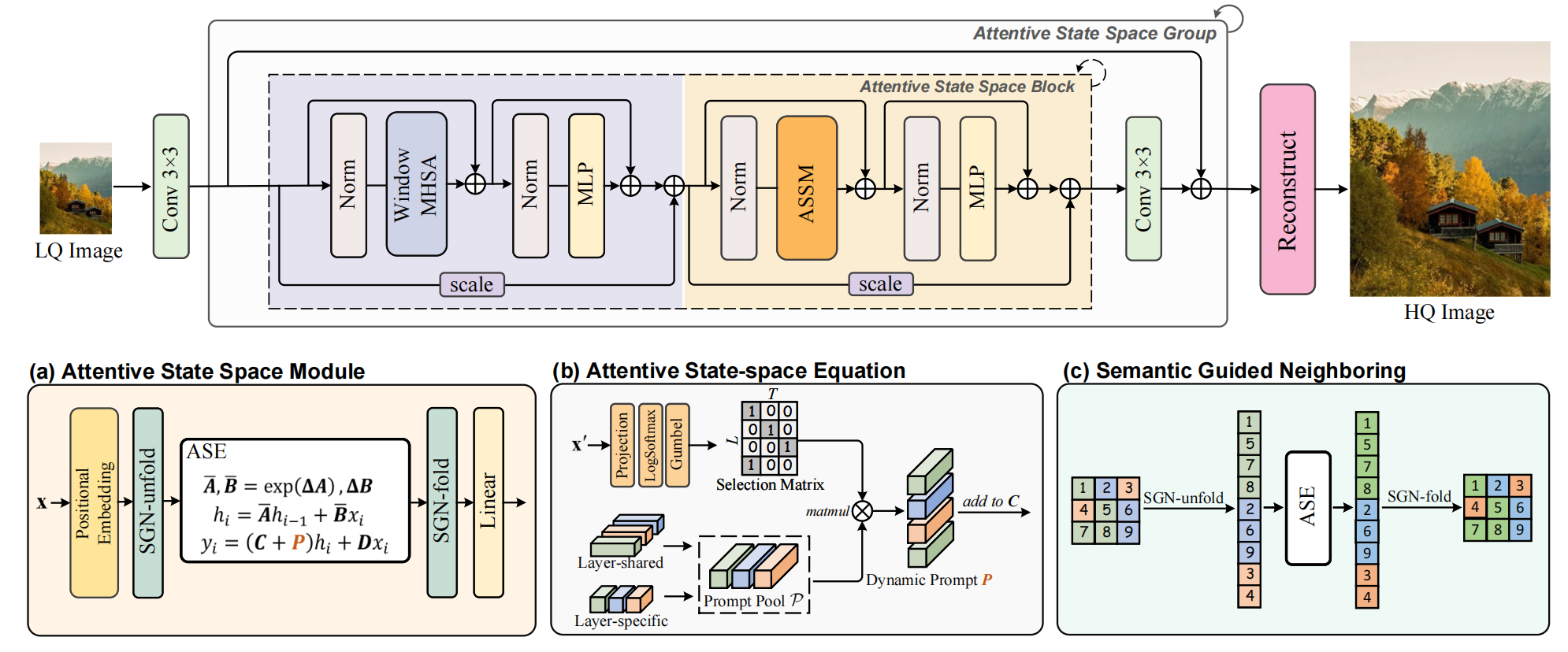
第一步是浅层特征提取,通过 3×3 卷积从低质量图像中提取基础特征,为后续的精细处理打下基础,这一步的作用是快速捕捉图像的边缘、颜色块等底层信息,避免后续模块在原始低质量数据上直接运算。
第二步是注意力状态空间组(ASSG)精修,这是架构的核心部分。每个 ASSG 包含多个 “注意力状态空间块(ASSB)”,每个 ASSB 都采用 “局部 - 全局” 结合的建模思路:在局部交互层面,通过窗口多头自注意力(MHSA)优化小范围细节,比如图像中的纹理、细小线条等,确保局部区域的修复精度;在全局交互层面,借助 ASSM(ASE 与 SGN 的组合),通过前文提到的注意力状态空间方程捕捉全图语义关联,让每个像素都能关联到全图的相似像素信息;同时,为了稳定训练过程、避免梯度消失或爆炸,还加入了带有可学习尺度的残差项,这一设计能有效保留浅层特征并提升模型收敛速度。
第三步是任务专属重建,针对不同的图像修复任务设计差异化的输出模块:在图像超分辨率任务中,采用 PixelShuffle 技术将特征图放大到目标分辨率,实现清晰的细节还原;在图像去噪任务中,则通过卷积层直接输出去噪后的图像特征,确保输出结果适配具体任务需求,让模型能灵活应对超分、去噪、JPEG 去压缩伪影等多种场景。
五、实验
论文通过四组关键实验,从模块有效性、任务适配性、性能对比等维度,全面验证了 MambaIRv2 的价值,所有实验均基于统一的训练设置(如数据增强用水平翻转与随机旋转、优化器用 Adam 等):
1. 消融实验:验证 ASE 与 SGN 的必要性
实验基于 2× 轻量级超分模型(DIV2K 训练,Urban100/Manga109 测试),对比 “仅 MHSA”“MHSA+ASE”“MHSA+ASE+SGN” 三种配置。
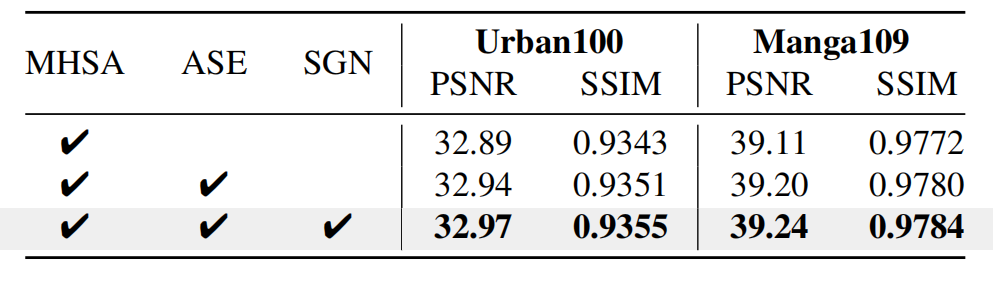
结果显示,仅用 MHSA 时 Urban100 PSNR 为 32.89dB、Manga109 为 39.11dB;加入 ASE 后两项指标分别提升至 32.94dB 和 39.20dB,证明非因果建模的价值;再加入 SGN 后进一步提升至 32.97dB 和 39.24dB,验证语义重组能缓解长距离衰减 —— 三大模块协同是性能突破的关键。
2. ASE 提示插入位置实验:确定最优改进方向
针对 ASE 中提示P的插入位置(输出矩阵C、输入矩阵、输出y等),在 Set14、Urban100、Manga109 数据集上对比。
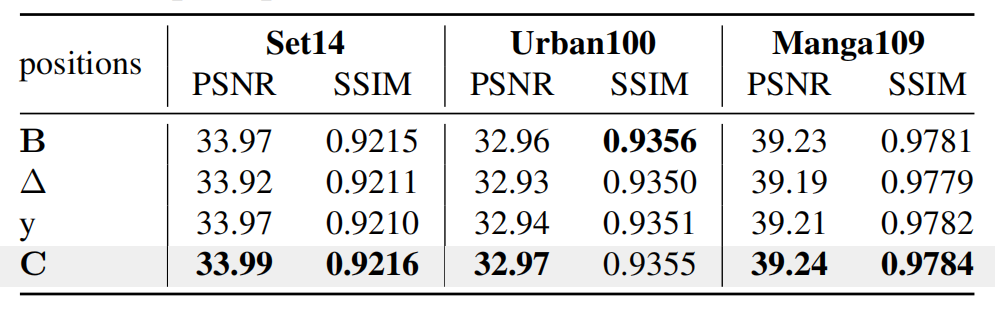
结果显示,将P插入C时效果最优:Urban100 PSNR 达 32.97dB、Manga109 达 39.24dB,而插入其他位置时性能均下降,证明 “” 是改进 Mamba 输出计算的最优选择。
3. 多任务性能对比实验:验证通用性与 SOTA 优势
论文在四大图像修复任务中与主流模型对比:
-
轻量级超分(论文表 3):2× 超分时,MambaIRv2-light(774K 参数)比 SRFormer-light(853K 参数)少 9.3% 参数,Urban100 PSNR 却高 0.35dB(33.26dB vs 32.91dB);
-
经典超分(论文表 4):MambaIRv2-B(22.9M 参数)比 HAT(20.6M 参数)计算量少 13%,Manga109 2× 超分 PSNR 高 0.16dB(40.42dB vs 40.26dB);
-
JPEG 去压缩伪影(论文表 6):q=40 时,Classic5 数据集 PSNR 达 34.64dB,超 MambaIR 0.11dB;
-
高斯去噪(论文表 7):σ=15 时,Urban100 数据集 PSNR 达 35.42dB,超 U 型 Restormer 0.29dB,证明模型通用性。
4. 扫描模式对比实验:验证单扫描的效率优势
对比 MambaIR 不同扫描方向(1/2/4 个方向)与 MambaIRv2 的单扫描。
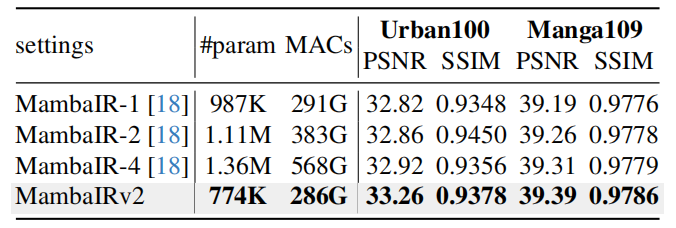
结果显示,MambaIRv2(774K 参数)比 4 方向扫描的 MambaIR(1.36M 参数)少 43% 参数、50% 计算量,且 Urban100 2× 超分 PSNR 高 0.34dB,直观证明单扫描设计的高效性。
六、挑战与展望
尽管 MambaIRv2 在图像恢复任务中取得了显著进展,但仍存在一些局限性,同时也为未来研究提供了潜在方向。主要包括以下几点:
1. 当前挑战
-
因果建模限制:传统 Mamba 的状态空间建模具有因果性质,每个像素仅依赖于扫描序列中的前置像素。这导致图像中远距离但语义相关的像素无法被充分利用,迫使现有方法采用多方向扫描以缓解信息缺失,增加了计算复杂度和冗余。
-
长距离衰减问题:即使在多方向扫描下,序列中相距较远的像素交互仍然减弱,限制了模型对长距离依赖的捕捉能力。
2. 未来展望
-
非因果建模扩展:MambaIRv2 通过引入ASE和SGN实现了非因果建模,为未来探索更多 ViT 风格的非因果扩展提供了可能。
-
高效全局信息交互:进一步研究如何在保持计算效率的同时,更加精细地捕捉远距离像素之间的语义关系,有助于提升图像恢复的精度和稳健性。
-
任务扩展与泛化能力:虽然 MambaIRv2 已在超分辨率、图像去噪和 JPEG 压缩恢复任务中表现优异,但其在去雾、去雨、低光增强等其他恢复任务上的潜力仍值得探索。
-
模型轻量化与性能优化:在保证恢复效果的前提下,进一步优化模型结构与参数规模,使其适用于超高分辨率图像或移动端设备,是未来研究的关键方向。
综上所述,MambaIRv2 的设计不仅缓解了因果建模和长距离衰减问题,也为非因果图像恢复模型的高效、可扩展发展提供了新的思路。未来工作可在非因果建模、全局交互、任务泛化和轻量化优化等方向进一步拓展。

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









