








论文项目和代码:Brain Diffusion for Visual Exploration: Cortical Discovery using Large Scale Generative Models
英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误,若有发现欢迎评论指正!文章偏向于笔记,谨慎食用
目录
2.4.1. Background on Diffusion Models
2.4.2. Brain-Encoding Model Construction
2.4.3. Brain-Guided Diffusion Model
2.5.2. Broad Category-Selective Networks
2.5.4. Semantic Divisions within ROIs
1. 心得
(1)是oral捏(看完了,名副其实,是很别致的论文,从实验中看出了作者的大脑在运转)
(2)Intro写的好复杂TUT
(3)哥们儿主图画得有点潦草
(4)非要给线性层取名线性适应层是吧我也能线性感知层线性提取层线性连接层线性萃取层归一线性层
(5)现在的img-brain signal数据集真是被玩出花了,真每篇任务都不一样
(6)实验做的很有新意,但我这里没有实验的详解,感兴趣的可以看看原文
2. 论文逐段精读
2.1. Abstract
①They proposed Brain Diffusion for Visual Exploration (BrainDiVE), which generates images by brain signals and proves ROI will perform differently in different visual tasks
2.2. Introduction
①Inference that higher visual cortex preferentially process complex semantic categories is come from manully stimuli and specific scene
②Maximum voxels of corresponding function of identify different categories. All these images are generated by BrainDiVE:

2.3. Related work
①Designed stimuli is different from natural stimuli
②Lists deep generative models such as variational autoencoders, generative adversarial networks, flows and score/energy/diffusion models. ⭐But all of these are for reconstruction rather than predicting stimuli(还没往下看,不过预测出会刺激大脑某个地方的图片该怎么去验证真的能刺激呢)
③They focus on complex scenes
macaque n.猕猴
2.4. Methods
①Steps of synthesizing images that activate a target brain region:
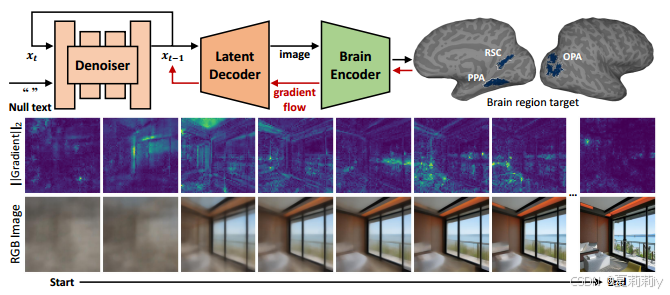
they only show the scene-selective regions (RSC/PPA/OPA) on the right hemisphere
2.4.1. Background on Diffusion Models
①Sampling from data distribution , and generate
,
step by step, where
②Mean-squared error (MSE) is the loss of autoencoder network
③Autoencoder consists of encoder
and decoder
④Diffusion model: pretrained latent diffusion model (LDM)
2.4.2. Brain-Encoding Model Construction
①Mapping learning:
where is image,
denotes voxel-wise brain encoding model,
is the fMRI
values with
elements
②Components of encoder: the first one is CLIP trained image encoder, which outputs dimensional vector as latent embedding; the second one is a euclidean normalization and linear adaptation layer
③The function of the whole encoding operations:
2.4.3. Brain-Guided Diffusion Model
①Conditioning is done in one of two ways in conventional text-conditioned diffusion models:
- The first approach modifies the function
to further accept a conditioning vector
, resulting in
.
- The second approach uses a contrastive trained image-to-concept encoder, and seeks to maximize a similarity measure with a text-to-concept encoder.
②Maximizing the average activation of predicted by
to condition the diffusion model:
where is a scale,
are the set of voxels used for guidance(为什么是先解码再编码了?不太了解扩散的改进)
③Employing euler approximation to get images with low noise:
2.5. Results
2.5.1. Setup
①Dataset: the Natural Scenes Dataset (NSD)
②Subject: they choose 4 of total 7, cuz S1, S2, S5, and S7 have the watched 10000 natural scene images repeated three times in their entirety
③Images in NSD: MS COCO
④Feature of fMRI: value calculated by GLMSingle
⑤Voxel norm: and
per session
⑥Applying average on repeat session of fMRI signal
⑦Data split: 9:1 for tr/test
⑧啥???每个人在V100上训练了1500个小时???62天???
⑨Diffusion base: stable-diffusion-2-1-base, which produces images of 512 × 512 resolution using ϵ-prediction
⑩Using multi-step 2nd order DPM-Solver++ with 50 steps and apply 0.75 SAG(什么玩意这是)
⑪Step size hyperparameter:
⑫Brain encoder: ViT-B/16 with 224×224 output size
⑬Prompt: null prompt ""
⑭CLIP probes: CoCa ViT-L/14 (LAION-2B)
2.5.2. Broad Category-Selective Networks
①Category selective voxels:
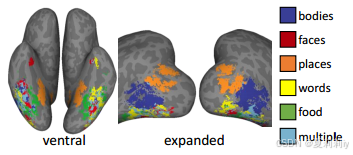
②The top-5 images which have the highest average activation:

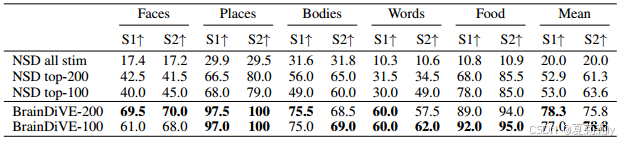
③Semantic specificity of images generated by BrainDiVE and natrual image:
2.5.3. Individual ROIs
①Generation ability of OFA and FFA:
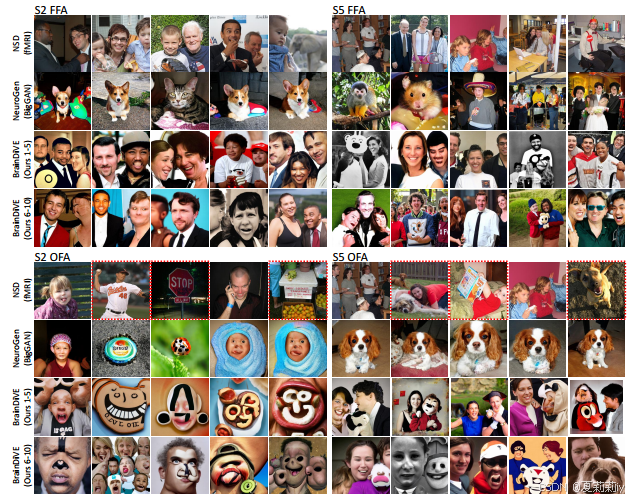
②Performance:
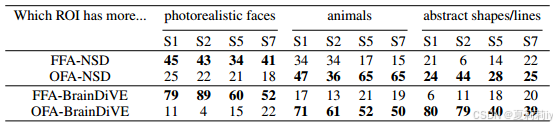
2.5.4. Semantic Divisions within ROIs
①Clustering within the food ROI and within OPA:
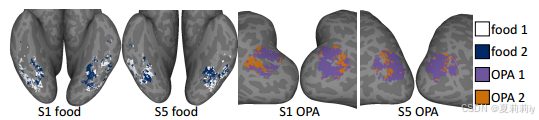
②Visualization of generated image of sub class S1 and S2:

③Subsets of OPA:

④Performance:(表的title很清楚了我就不描述了)


2.6. Discussion
~
3. Reference
@article{luo2023brain,
title={Brain Diffusion for Visual Exploration: Cortical Discovery using Large Scale Generative Models},
author={Luo, Andrew F and Henderson, Margaret M and Wehbe, Leila and Tarr, Michael J},
journal={arXiv preprint arXiv:2306.03089},
year={2023}
}
}

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









