





英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误,若有发现欢迎评论指正!文章偏向于笔记,谨慎食用
目录
2.4.3. Model integrating in the prediction framework
2.5. Experiments and discussions
2.5.1. Dataset and experimental settings
2.5.2. Experimental results and analysis
1. 心得
(1)相关工作显得有点早了
(2)好鲜艳的绘图风格
(3)是不是有点太...performance based?了?emm,双栏九页显得有点短了,感觉实验纯在说性能,有没有更实际一点的作用呢?比如这个比检测疾病来得更加紧急,是不是需要更快速更轻量?出血都是同一原因吗?能不能诊断不同原因的出血?(外行不懂)
(4)需要的特征是不是太多了?如果已知哪些重要(好像文章里提到了高危因素),那加其他那么多进来是emm,也不是不行,就是奇奇怪怪的
2. 论文逐段精读
2.1. Abstract
①Limitation: class imbalance and insufficient utilization of neural networks on postpartum hemorrhage (PPH) prediction
postpartum adj.产后的 hemorrhage n.出血;(尤指大量的)失血 v.出血
2.2. Introduction
①Demand: timely treatment
②Challenges: low quality of data, scarse data, unstructured text records and class imbalance
disseminated v.散布,传播(信息、知识等) adj.浸染的;散播性的
intravascular adj.血管内的 coagulation n.凝固;凝结(物);凝聚;絮(胶)凝;聚集
2.3. Related works
①Discriminative features might be hard to collect
②Univariate analysis ignores the non-linear relationship between feature and target
③Other methods might ignores the class imbalance problem
④Lists several undersampling and oversampling methods
placenta n.胎盘 uterine adj.子宫的
2.4. Methodology
①The overall framework:
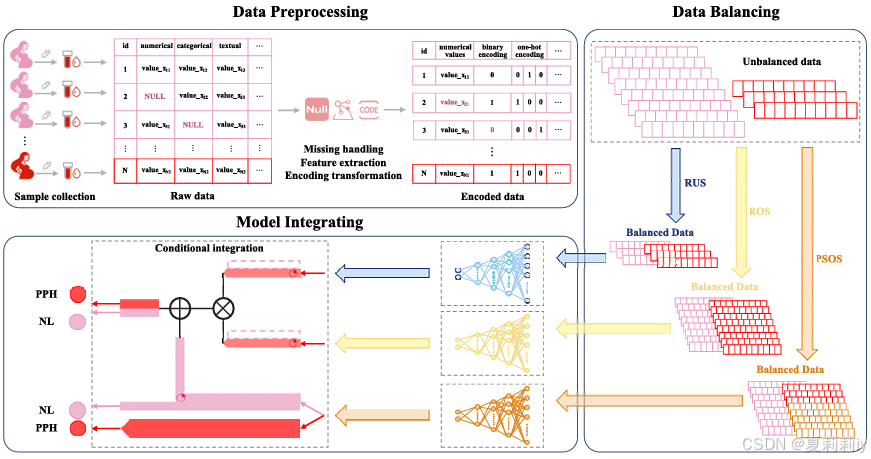
2.4.1. Data preprocessing
①Encode missing values to feature vector:
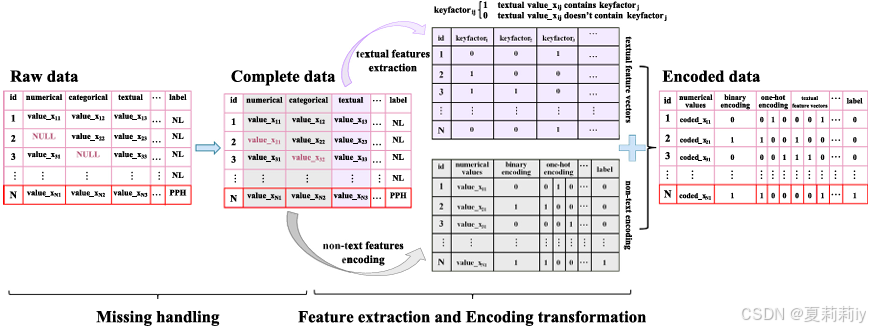
②How to deal with missing data:

where the new category might be "undefined" class
③After this, encoding non-textual feature when feature dimensions are different: binning for skewed or non-linearly correlated continuous variables and one hot for categorical features
④Meanwhile, they define the key factor symbol(这哪来的啊,就是上面的纯紫色表,我咋知道重不重要)
skewed adj.斜的;偏的;偏向(或偏重)…的;歪曲的;歪的;不准确的;有偏颇的 v.歪斜;偏离;歪曲;曲解;影响…的准确性;使不公允
2.4.2. Data balancing
①Two steps oversampling:
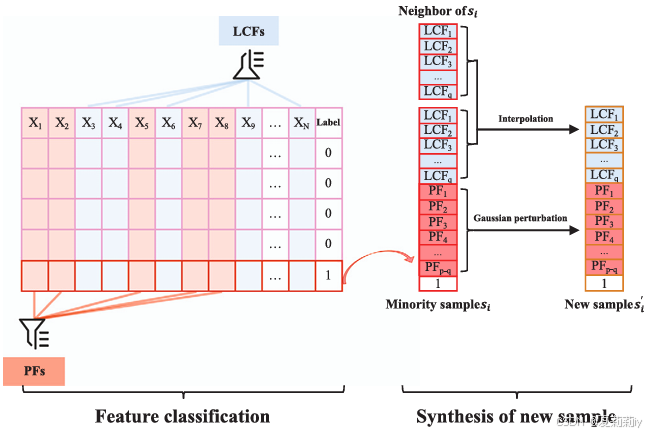
where LCFs is lowly correlated features and PFs is promising features
(1)Feature classification
①The -th sample in the dataset
has
feature number and label
:
②Measure the relationship between feature and label, by Pearson correlation:
(能直接看到标签的吗??是统计?)
③Apply t test on correlation, which ensures less influence from random factor:
(2)Part-synthetic oversampling strategy
①LCF value for new generated sample:
where and
denotes the nearest
neighbors of
②New PF value generated by Gaussian perturbation:
where
③Algorithm of PSOS:

2.4.3. Model integrating in the prediction framework
①Collaborative label prediction of three models:
(emmm)where 1 denotes PPH and 0 denotes NL
②Algorithm of PPH prediction:

2.5. Experiments and discussions
2.5.1. Dataset and experimental settings
①Dataset: gynecology and obstetrics of Sichuan Provincial Maternity and Child Health Care Hospital
②Definition of PPH: blood loss of ≥ 500 ml after vaginal delivery of a baby, or ≥ 1000 ml after caesarean section within 2 hours
③Sample: 24,110 in total, and only 663 (2.75%) are PPH
④Feature in dataset:
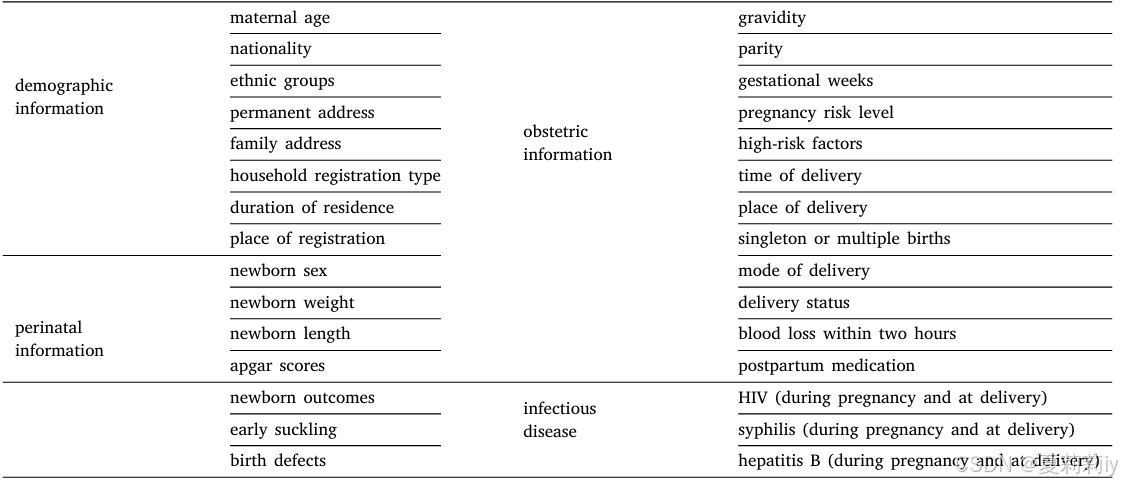
⑤Demographics:
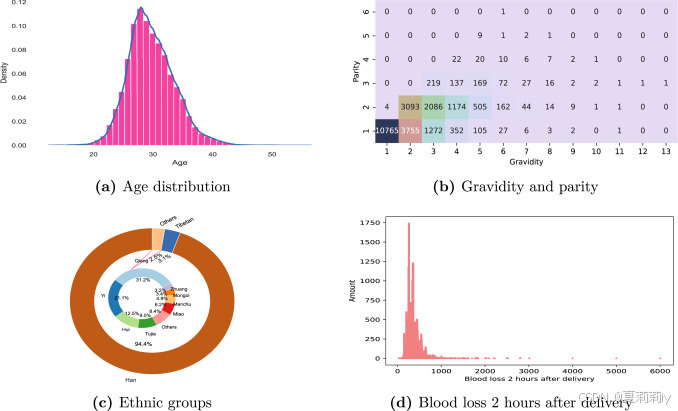
(1)Experimental configuration
①Dimension of feature: 223
②Hyper-parameter:
③Neural network (NN): linear layers with 200, 64 and 32 hidden dimension and ReLU
④Optimizer: Adam with learning rate of 0.0001 and weight decay with 0.0001
(2)Evaluation metrics
①Metrics:
2.5.2. Experimental results and analysis
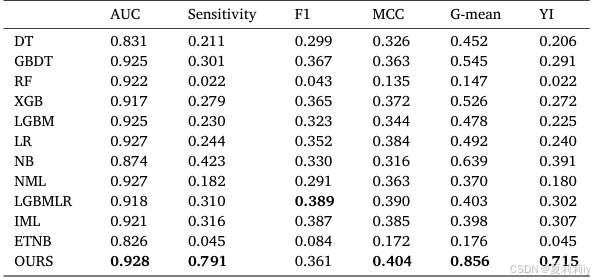
(1)Results of prediction framework
①Performance:
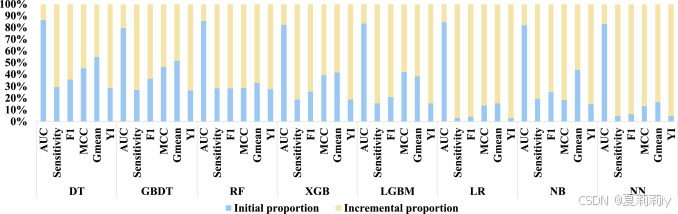
(2)Results of data preprocessing
①How text feature improves performance:
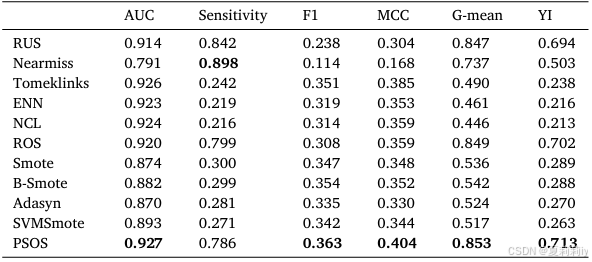
(3)Results of data balancing strategies
①Performance of different sampling strategies:
(4)Results of ablation experiments
①Performance of module ablation:
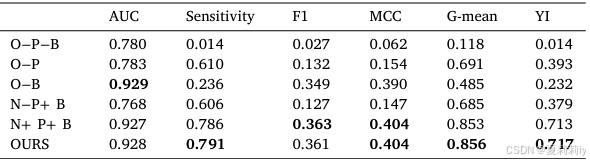
where is complete model,
,
and
denote data preprocessing, data balancing, and a single NN model
2.5.3. Discussion
①Hyper-parameter can be further optimized
2.6. Conclusion
~


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









