








论文网址:[2503.02351] MindSimulator: Exploring Brain Concept Localization via Synthetic FMRI
英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误,若有发现欢迎评论指正!文章偏向于笔记,谨慎食用
目录
2.4.1. Motivation and Overview
2.6.1. Evaluation for Synthetic fMRI
2.6.2. Out-of-Distribution Generalization
2.7. Localizing Concept-Selective Regions
2.7.1. Predict Empirical Regions
2.7.2. Exploring Novel Regions
1. 心得
(1)看似简单,实则复杂的一篇论文。哈哈,很奇妙,有点像越嚼越香的干面包
(2)脑信号编码和解码领域论文最近真的很各有千秋啊
2. 论文逐段精读
2.1. Abstract
①Brain stimuli by specific object is subjective
②They proposed MindSimulator to locate concept-selective regions
2.2. Introduction
①Specific conception (such as places, bodies, faces, words, colors, and foods) will stimulate different corresponding cortical regions
②Limitations: limited data, bias of artificially selected stimuli, and isolated objects in unnatural scenes(这个似乎就和上一篇论文相反,上一篇觉得就应该单独看一个物体只认知这个物体,但这一篇认为物体不应该独立于场景而存在。可能就是上下文认知不同吧。)
2.3. Related Works
①Lists fMRI encoding/decoding and generative methods
2.4. Method
2.4.1. Motivation and Overview
①⭐The same stimuli will bring differet fMRI recording. 因此一个刺激会对应多个fMRI记录。通过回归模型加工的刺激只能得到单一的fMRI记录,但生成模型更为随机。所以作者采用生成模型
②Overview of model:
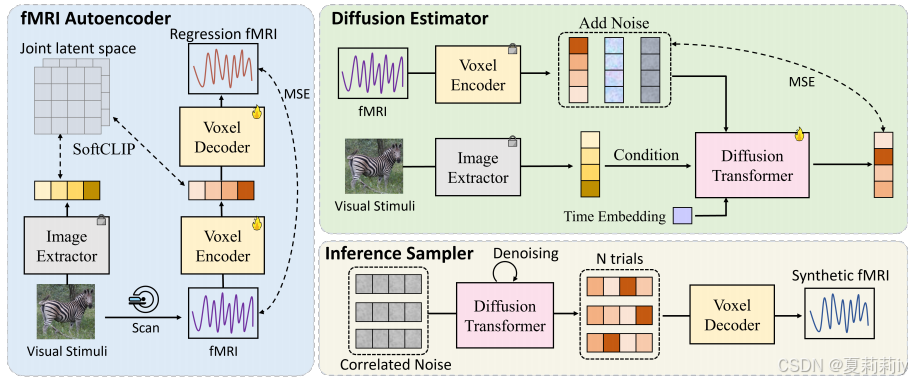
2.4.2. fMRI Autoencoder
①Paired data is from sample
, where
is preprocessed BOLD signal and
is corresponding visual stimuli (从很后面返回到这里,这个一维是因为展平了)
②Voxel encoder embeds
to
with higher dimension
③Voxel decoder decodes
back to fMRI voxel
④Loss of autoencoder block:
⑤They use pre-trained CLIP-ViT to align fMRI and stimuli
⑥Loss of align:
⑦Autoencoder loss:
⑧Diffusion estimator is Transformer with cross-attention
2.4.3. Diffusion Estimator
①They designed a diffusion estimator with
time steps to obtain the noised fMRI representation:
where denotes noise schedule hyperparameter and
denotes Gaussian noise
②Learning objective:
2.4.4. Inference Sampler
①Predicted fMRI representation:
②They generate fMRI signals by
noise and take the average of
fMRI
③Noise generation: randomly sample two independent noise and
, then generates others:
2.5. Experiments Setup
2.5.1. Datasets
①Dataset: Natural Scenes Dataset (NSD)
②Subject: 8
③Image/stimuli set: MSCOCO
④Session: 3 with 10000 images each, then obtain 30000 fMRI signals for one sbject
⑤Selected subject: 1, 2, 5, 7 for their complete experiment
⑥Data split: 9000 for training and 1000 for testing
⑦⭐作者在训练的时候将一个被试的三次session当作三个数据,但在测试时会综合一个刺激对应的三个fMRI刺激并取平均作为结果
⑧The authors utilized the GLMSingle tool to compute the beta-activations for each voxel, which reflect the strength of the brain's response to specific stimuli, and normalized these activations.
⑨Brain atlas: 官方自动分割的,不是现有的模板
2.5.2. Implementation Details
①Image extractor: CLIP ViT-L/14 with 257×768 dimension
②Voxel encoder: MLPs and residual networks, voxel decoder is the opposite
③Optimizer: AdamW
④Epoch: 300 for fMRI autoencoder and 150 for diffusion
⑤Cycle learning rate: starting from 3e-4
⑥Diffusion estimator: adopting a cosine noise schedule and 0.2 conditions drop
⑦Diffusion network: 6 Transformer blocks with 257 image tokens, 257 noised fMRI tokens, and 1 time embedding each
⑧ is randomly sampled in (0,1)
2.5.3. Evaluation Metrics
①⭐Pearson correlation, voxel-wise mean square error (MSE), and R-squared cannot reflect performance accurately:

②Evaluation method:
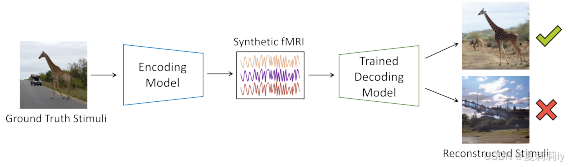
2.6. Results
2.6.1. Evaluation for Synthetic fMRI
①Performance table:

②Image reconstruction:

2.6.2. Out-of-Distribution Generalization
①Semantic-level performance when MindSimulator generates to other image only datasets:

②Image reconstruction performance:

2.6.3. Ablation
①Module ablation:

2.7. Localizing Concept-Selective Regions
2.7.1. Predict Empirical Regions
①The empirical findings of faces-, bodies-, places-, and wordsselective regions in NSD fLoc:
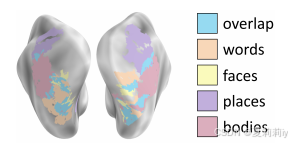
②Subset of the top 100 image categories selected by pre-trained CLIP model:

③Localization evaluation of places- and bodies-selective regions:

2.7.2. Exploring Novel Regions
①Localized concept-selective regions according to synthetic fMRI:
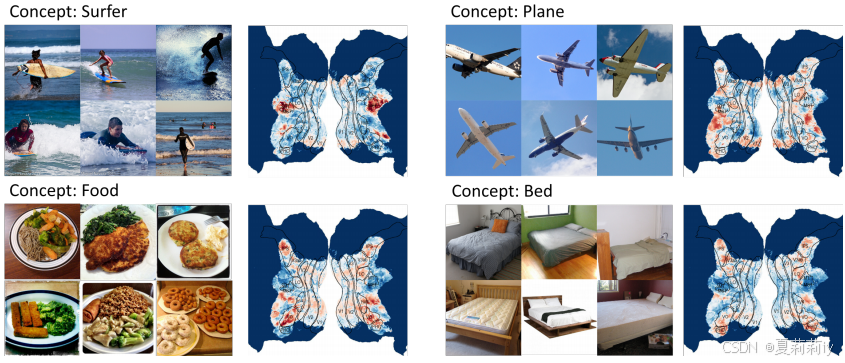
较低的视觉皮层对颜色和形状具有选择性,而较高的视觉皮层则对特定的概念具有选择性
②Reconstruction after mask:

2.8. Conclusion
~


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









