








论文网址:[2310.01728] Time-LLM: Time Series Forecasting by Reprogramming Large Language Models
英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误,若有发现欢迎评论指正!文章偏向于笔记,谨慎食用
目录
2.6. Conclusion and Future Work
1. 心得
(1)一觉醒来,已经爆肝了两篇论文了。我的年好像还没有过,起来读读论文好了
(2)怎么ICLR也收酱紫深度的吗,不是数学大赏了?赏不动一点
(3)有些会议的章节名字是真的可爱
![]()
其实可以看出来是 大号大写+大写 大大写+大写,虽然在latex肯定输入的\section{Main Results},这个样式让我当时自己写的时候,单词都给强制大写得来认不出来了
(4)经历了贪婪饕餮嫉妒懒惰傲慢暴怒之后的我已经 心如 止水 fine
2. 论文逐段精读
2.1. Abstract
①Large language model (LLM) is able to deal multi tasks
②Challenge of LLM: how to combine time series and natural language
2.2. Introduction
①Advantages of pre-trained model: excellent performance on few-shot and zero-shot transfer learning
②⭐Other models are generally based on statistics, while LLM has reasoning and pattern recognition capabilities
③Challenge: discrete LLM token and continuous time series data are hard to align, and reasoning ability in time series is not exist
desiderata n. 需求;迫切需要得到之物;迫切需要的东西;必需品;迫切需要之物
2.3. Related Work
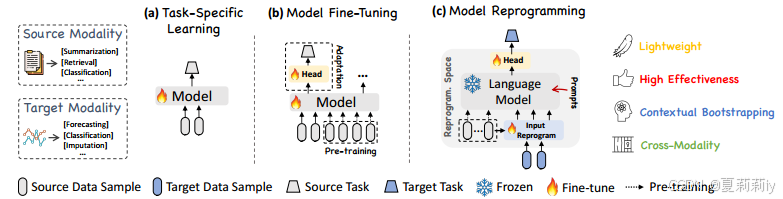
①Task-specific learning: design a small model for specific task like (a)
②In-modality adaptation: limited data scale, as (b)
③Cross-modality adaptation: the alignment and combination of two modalities can better suit more tasks
2.4. Methodology
①Model architecture:
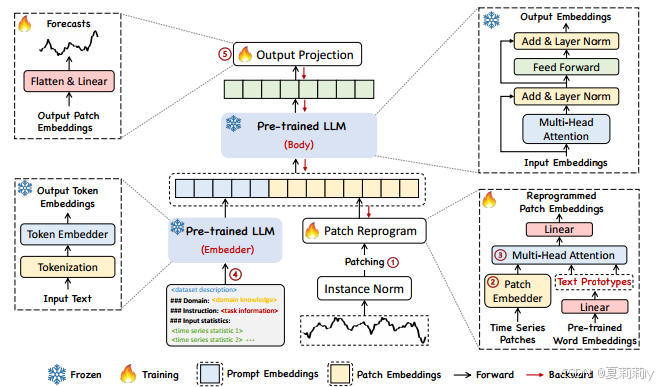
②Given a sequence of historical observation , where
is the number of sequence and
is time steps
③Task: finding a mapping to forecast the future
time steps
④Aiming: minimize the regression loss i.e.
⑤Process: employ normalization, patching, and embedding to each sequence to predict
2.4.1. Model Structure
(1)Input Embedding
①Mitigating the time series distribution shift by individually normalized to have zero mean and unit standard deviation via reversible instance normalization (RevIN)
②Divide into several consecutive overlapped or non-overlapped patches with length
(滑窗捏~~). So the patch number and patches will be
and
, where
is the stride
③Embedding patches by linear layer
(2)Patch Reprogramming
①A common method for LLM learning is to learn a "noise"
“噪声”形式是什么?
这里的“噪声”并不是指随机干扰,而是一种可学习的输入变换,用于将目标数据(如时间序列)转换为预训练模型(如LLM或视觉模型)能够理解的格式。这种变换允许模型在不更新参数的情况下处理新模态的数据。
举例说明:
视觉模型的跨域应用(Misra et al, 2023):
假设有一个预训练的视觉模型,原本用于处理自然图像(如猫狗分类)。现在想用它处理医学图像(如X光片)。由于医学图像与自然图像的分布不同,直接输入会导致模型性能下降。
解决方法是通过学习一种“噪声”变换,将医学图像转换为类似自然图像的格式。例如,可以通过添加特定的滤波器或颜色映射,使X光片看起来更像自然图像。这种变换是可学习的,且不需要更新预训练模型的参数。声学模型处理时间序列数据(Yang et al, 2021):
假设有一个预训练的声学模型,原本用于处理语音信号。现在想用它处理时间序列数据(如股票价格)。
由于语音信号和时间序列数据的结构不同,直接输入会导致模型无法理解。
解决方法是通过学习一种“噪声”变换,将时间序列数据转换为类似语音信号的格式。例如,可以通过重采样或频谱变换,使时间序列数据在频域上类似于语音信号。这种变换也是可学习的。在这些例子中,“噪声”是一种输入层面的适配器,用于弥合源数据(预训练模型的输入)和目标数据(新任务的数据)之间的差距。
②However, time series are not suitable for transformation
时间序列不可编辑是什么意思?
时间序列数据的“不可编辑”指的是其固有的连续性和复杂性,使得无法通过简单的变换将其无损地转换为其他模态(如自然语言或图像)。具体来说:
时间序列的连续性:
时间序列数据是按时间顺序记录的,每个时间点的值都依赖于之前的值。这种连续性使得对时间序列的编辑(如插入、删除或修改)可能会破坏其整体结构和语义。时间序列的复杂性:
时间序列数据通常包含多种模式(如趋势、周期、噪声),这些模式之间的关系复杂,难以用简单的规则或语言描述。举例说明:
假设有一段股票价格的时间序列数据:
如果直接将其转换为自然语言描述(如“股票价格先上涨,后下跌”),会丢失大量细节信息(如具体的波动幅度、频率等)。
如果尝试将其转换为图像(如折线图),虽然可以保留部分信息,但图像无法完全捕捉时间序列的动态特性(如时间依赖关系)。
因此,时间序列数据的“不可编辑”意味着:
无法通过简单的变换将其无损地转换为其他模态。
无法通过直接编辑输入数据来适配预训练模型,而需要更复杂的适配方法(如学习“噪声”变换)。
③Thus, they proposed a word embedding method, including , where
is the vocabulary size. A large number of vocabulary
results in wastage of computational resources, so they maps
to a smaller set
by linear probing:
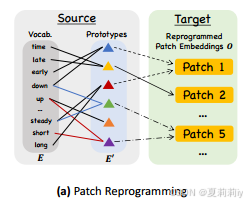
where
④Then they get target by combining prototypes through multi-head cross-attention layer:

(3)Prompt-as-Prefix
①Language has low sensitivity to numerical sequences and each language model stores numerical values differently in Patch-as-Prefix:
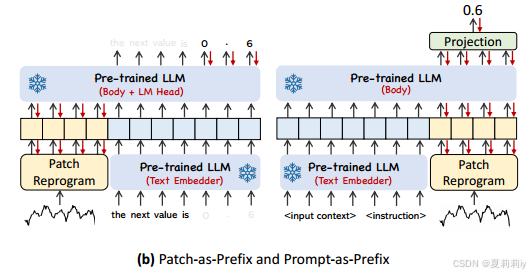
②But Prompt as Prefix overcomes these limitations by adding (1) dataset context, (2) task instruction, and (3) input statistics:

(4)Output Projection
③Flatten and project representations to get prediction
2.5. Main Results
①Fair configuration: Llama-7B as default backbone
②Baselines: Transformer based: PatchTST, ESTformer, Non-Stationary Transformer, FEDformer, Autoformer, Informer, Reformer; competitive models: GPT4TS, LLMTime, DLinear, TimesNet, LightTS and short term N-HiTS, N-BEATS
2.5.1. Long-term Forecasting
①Datasets: ETTh1, ETTh2, ETTm1, ETTm2, Weather, Electricity (ECL), Traffic, and ILI
②Input time series length:
③Forecasting range:
④Metrics: mean square error (MSE) and mean absolute error (MAE)
⑤Performance table:
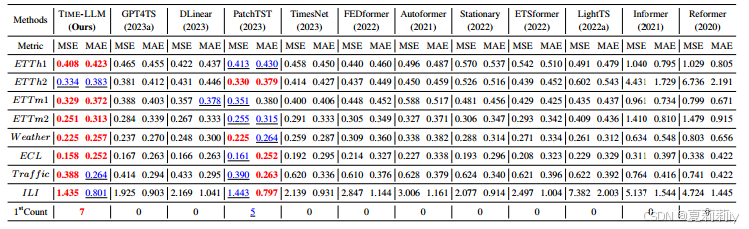
where only ILI forecasts
2.5.2. Short-term Forecasting
①Performance on M4:

2.5.3. Few-shot Forecasting
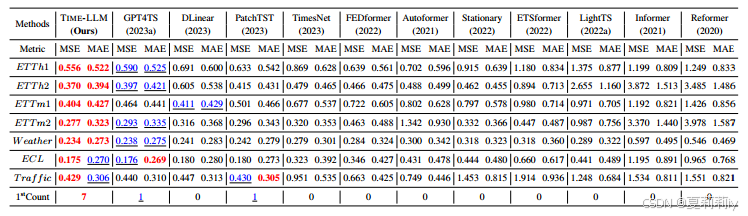
①10% few shot performance:
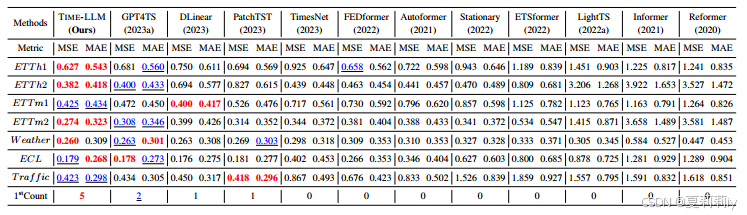
②5% few shot performance:
2.5.4. Zero-shot Forecasting
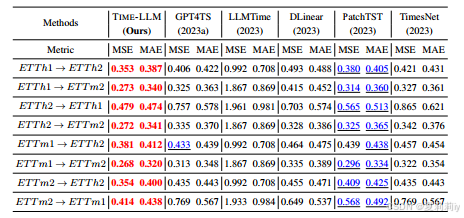
①Performance:
2.5.5. Model Analysis
①Backbone ablation:
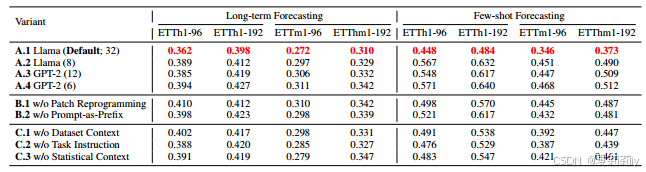
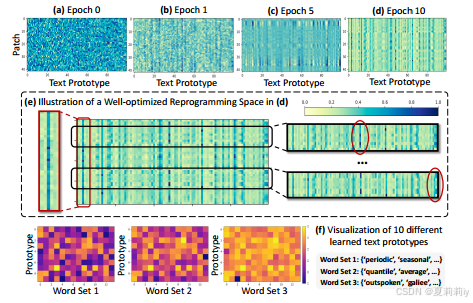
②Patch reprogramming:
③Efficiency analysis on different backbones:

2.6. Conclusion and Future Work
~

















 1520
1520

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









