



PART/1
概述
最近,使用自注意力机制设计视觉主干架构成为了一个令人兴奋的研究课题。在这项工作中,我们设计了一种改进的主干网络MHSA-Darknet,通过多头自注意力机制保留足够的全局上下文信息,并提取更具区分性的特征用于目标检测。关于路径聚合颈部网络,我们提出了一种简单但非常有效的加权双向特征金字塔网络(BiFPN),用于实现有效的跨尺度特征融合。此外,诸如测试时增强(TTA)和加权框融合(WBF)等其他技术有助于实现更高的检测精度和更强的鲁棒性。我们的实验表明,ViT-YOLO显著优于当前最先进的检测器,并在2021年VisDrone-DET挑战赛中取得了顶尖成绩之一(测试挑战数据集的平均精度均值(mAP)为39.41,测试开发数据集的mAP为41)。
PART/2
背景
目标检测的目的是为每个感兴趣的物体预测一组边界框和类别标签。近年来,随着无人机(UAV)的出现,配备摄像头的无人机迅速应用于农业、航拍、快递、监控等广泛领域。因此,自动且有效的目标检测在无人机平台的场景解析中起着重要作用。

然而,如上图所示,无人机拍摄的图像具有显著特点,包括物体尺度变化极大、背景复杂且充斥着干扰物,以及拍摄视角灵活多变。这些特点给基于普通卷积网络的通用目标检测器带来了巨大挑战。卷积神经网络(CNN)在计算机视觉的各个领域都取得了重大突破。一般来说,现代检测器采用纯卷积网络来提取特征。经典的图像分类网络(如VGG、ResNet被用作最先进的检测器FasterRCNN和RetinaNet等的主干网络)。至于YOLO系列检测器,它们应用了一种新颖的残差网络Darknet,在进行特征提取时效率更高。如今,Transformer由于能够通过自注意力机制学习输入序列之间的复杂依赖关系,已成为自然语言处理中的主导模型。我们也注意到,最近引入的视觉Transformer通过将图像视为一系列图像块,在基准分类任务中取得了具有竞争力的结果。对于具有大规模和复杂场景的无人机拍摄图像,为了提高语义辨别能力并减轻类别混淆,从较大的邻域中收集和关联场景信息有助于学习物体之间的关系。但对于卷积网络来说,卷积操作的局部性限制了其捕捉全局上下文信息的能力。
相比之下,Transformer能够全局地关注图像特征块之间的依赖关系,并通过多头自注意力机制为目标检测保留足够的空间信息。此外,为了解决航拍图像中视角变化的问题,目标检测器应具备更强的领域自适应能力和动态感受野。文献的研究表明,与CNN相比,视觉Transformer对严重的遮挡、扰动和领域偏移具有更高的鲁棒性。因此,提高检测性能的一种直观方法是将Transformer层嵌入到纯卷积主干网络中,以引入更多的上下文信息并学习更具区分性的特征表示。另一方面,无人机拍摄图像中的物体尺寸差异很大,而卷积神经网络单层的特征图表示能力有限,因此有效地表示和处理多尺度特征至关重要。一种经典方法是通过求和或拼接操作来组合低层和高层特征,但不加区分地简单求和或拼接可能会导致特征不匹配和性能下降。我们的关键思路是引入可学习的权重来学习不同输入特征的重要性,同时反复应用自上而下和自下而上的多尺度特征融合。
章中所有的数据和资料,可添加小助手无偿分享~
扫码添加小助手即可无偿获取~
也可以关注“AI技术星球”公众号,关注后回复“221C”获取。

PART/3
新框架解析
我们提出的网络架构是一个同时使用卷积和自注意力机制的混合模型ViT-YOLO,它主要基于YOLOv4-P7。
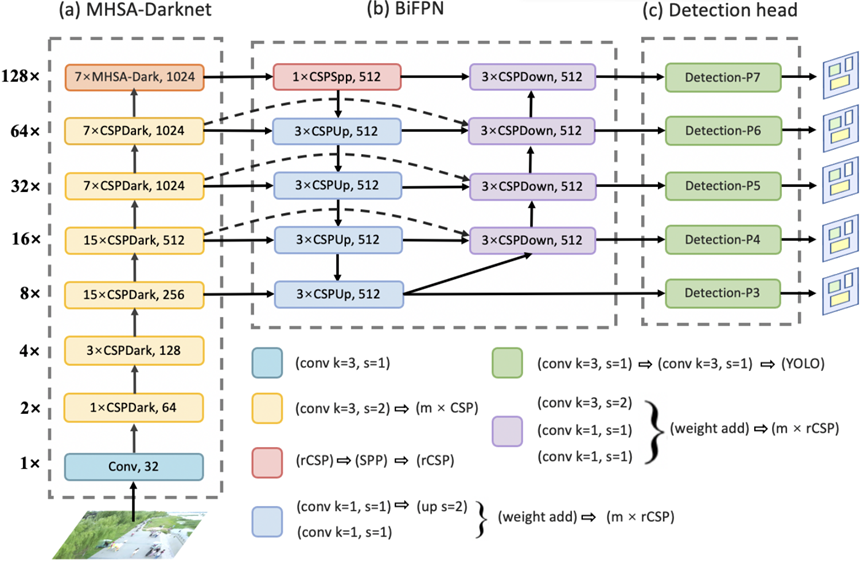
ViT-YOLO的结构如上图所示,可分为三个部分。第一部分,我们使用MHSA-Darknet作为主干网络,将多头自注意力机制集成到原始的CSP-Darknet中,以提取更具区分性的特征。MHSA-Darknet的详细信息将在下面中介绍。
MHSA-Darknet
对于具有大规模和复杂场景的无人机拍摄图像,为了提高语义辨别能力并减轻类别混淆,从较大的邻域中收集和关联场景信息有助于学习物体之间的关系。但对于卷积网络来说,卷积操作的局部性限制了其捕捉全局上下文信息的能力。相比之下,Transformer能够全局地关注图像特征块之间的依赖关系,并通过多头自注意力机制为目标检测保留足够的空间信息。另一方面,视角变化是无人机拍摄图像中最大的挑战之一,这要求检测器应具备更强的领域自适应能力和动态感受野。文献的研究表明,与CNN相比,视觉Transformer对严重的遮挡、扰动和领域偏移具有更高的鲁棒性。为了提高所学习特征的可迁移性,同时捕捉长距离上下文信息,我们提出了MHSA-Darknet主干网络来为检测器提取特征。MHSA-Darknet的设计很简单:将多头自注意力(MHSA)层嵌入到顶部的CSPDark模块中,以便在二维特征图上实现全局(全连接)自注意力。

MHSA-Darknet架构见上表。
章中所有的数据和资料,可添加小助手无偿分享~
扫码添加小助手即可无偿获取~
也可以关注“AI技术星球”公众号,关注后回复“221C”获取。
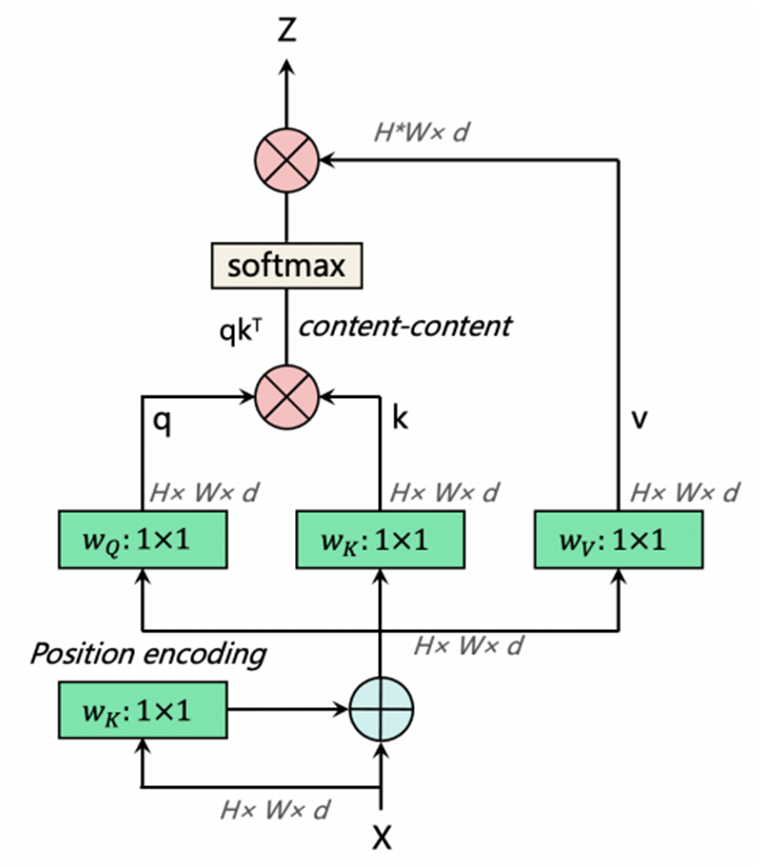
MHSA层如上图所示。YOLOv4-P7中的CSP-Darknet通常有7个阶段(或模块组),通常称为[P1,P2,P3,P4,P5,P6,P7],相对于输入图像的步长分别为[2,4,8,16,32,64,128]。[P1,P2,P3,P4,P5,P6,P7]模块组由多个具有跨阶段部分(CSP)连接的CSPDark模块组成。(即YOLOv4-P7中的CSP-Darknet有[1,3,15,15,7,7,7]个CSPDark模块)。值得注意的是,当网络相对较浅且特征图相对较大时,过早使用Transformer层来强制确定回归边界可能会丢失一些有意义的上下文信息。因此,在MHSA-Darknet中,Transformer层仅应用于P7阶段,而不是P3、P4、P5和P6阶段。
此外,考虑到在全局范围内对n个实体执行自注意力操作需要O(n²d)的内存和计算量,我们认为,遵循上述因素的最简单设置是在主干网络中分辨率最低的特征图上融入自注意力机制,即P7模块组中的CSPDark模块。Darknet主干网络中的P7模块组通常使用7个CSP瓶颈模块,每个模块包含一个1×1空间卷积和一个3×3空间卷积。用MHSA层替换它们构成了MHSA-Darknet架构的基础。
为了处理二维图像,我们将二维特征图\(x\in\mathbb{R}^{H\timesW\timesd}\)的空间维度展平为一个序列\(x_p\in\mathbb{R}^{(H\timesW)\timesd}\),其中\((H,W)\)是原始特征图的分辨率,\(d\)是通道数,\(H\timesW\)作为Transformer层的有效输入序列长度。为了使注意力操作具有位置感知能力,基于Transformer的架构通常会使用位置编码。我们使用带有线性层的标准可学习一维位置嵌入来保留位置信息。
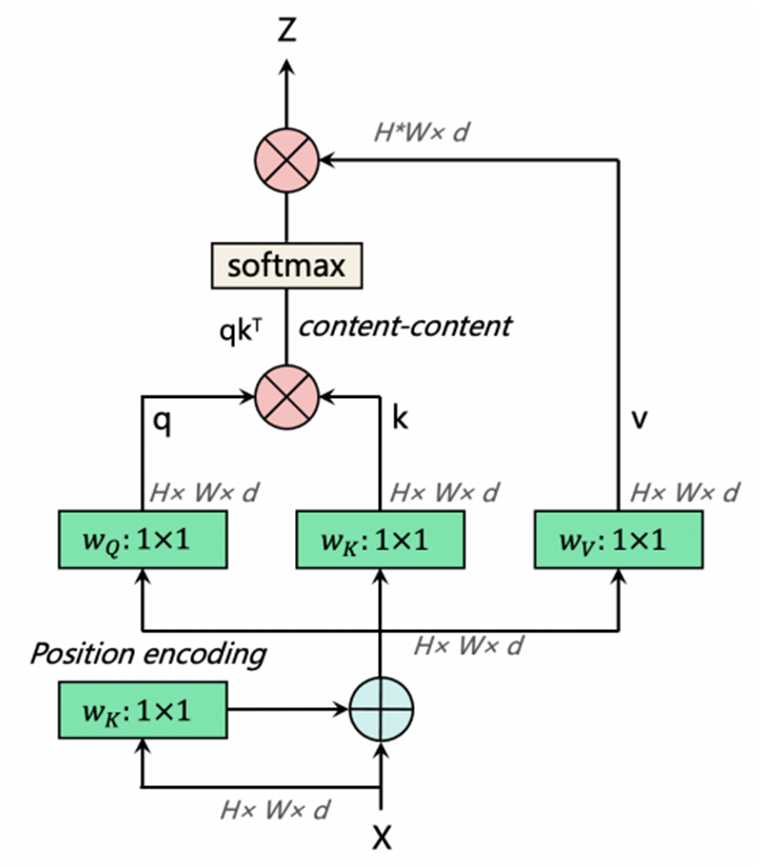
MHSA层如上图所示。
双向特征金字塔网络(BiFPN)
无人机拍摄图像中的物体尺寸差异很大,而卷积神经网络单层的特征图表示能力有限,因此有效地表示和处理多尺度特征至关重要。传统的自上而下的特征金字塔网络(FPN)在本质上受到单向信息流的限制。为了解决这个问题,路径聚合网络(PANet)添加了一个额外的自下而上的路径聚合网络。
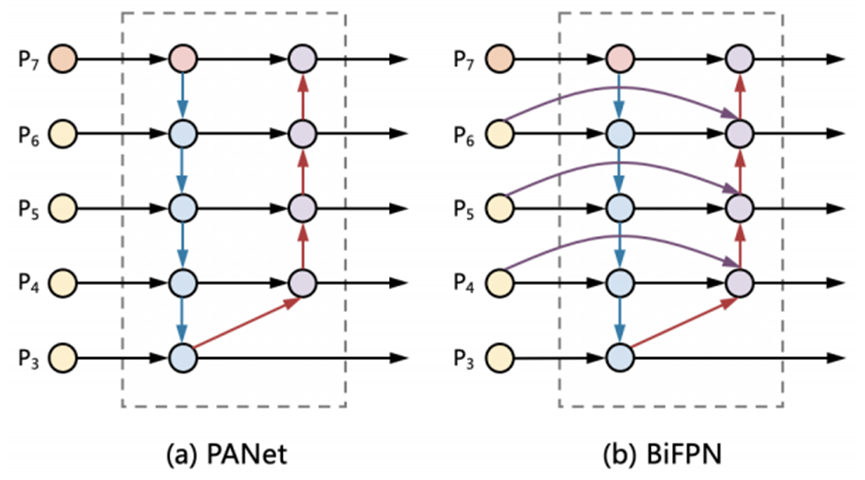
如上图(a)所示。跨尺度连接在文献中得到了进一步研究。在这项工作中,如上图(b)所示,简单但非常有效的加权双向特征金字塔网络(BiFPN)对跨尺度连接进行了两项优化。首先,BiFPN在原始输入和输出节点处于同一层级时,会添加一条额外的边,以便在不增加太多计算成本的情况下融合更多的特征。其次,在组合低层和高层特征时,BiFPN引入了可学习的权重来学习不同输入特征的重要性,而不是简单地求和或拼接,因为简单的求和或拼接可能会导致特征不匹配和性能下降。正式地说,给定一个多尺度特征列表\(\widetilde{P}_{in}=(P_{l_1}^{in},P_{l_2}^{in},\ldots)\),其中\(P_{l_i}^{in}\)表示层级\(l_i\)的特征。路径上的中间特征列表表示为\(\widetilde{P}_{td}=(P_{l_1}^{td},P_{l_2}^{td},\ldots)\)。我们的目标是找到一个变换\(f\),它可以有效地聚合不同的特征并输出一个新的特征列表:\(\widetilde{P}_{out}=f(\widetilde{P}_{in})\)。
上图(a)展示了传统的自上而下和自下而上的路径聚合网络(PANet)。它采用层级\(3-7\)的输入特征\(\widetilde{P}_{in}=(P_{3}^{in},\ldots,P_{7}^{in})\),其中\(P_{i}^{in}\)表示分辨率为输入图像\(1/2^i\)的特征层级。例如,如果输入分辨率是\(1024\times1024\),那么\(P_{3}^{in}\)表示层级\(3\)(\(1024/2^3=128\))的特征,分辨率为\(128\times128\),而\(P_{7}^{in}\)表示层级\(7\)的特征,分辨率为\(8\times8\)。
PART/4
实验及可视化
实现细节在2021年VisDrone目标检测挑战赛中,我们选择了MHSA-Darknet主干网络、BiFPN路径聚合颈部网络,以及基于锚框的YOLOv3检测头作为ViT-YOLO的架构。我们的模型使用随机梯度下降(SGD)作为优化器,默认权重衰减为0.0005,动量为0.937。在模型的初始训练阶段,我们首先进行3个epoch的热身训练。在热身过程中,优化器SGD的动量设置为0.8,并使用一维线性插值来更新每次迭代的学习率。热身训练之后,使用余弦退火函数来衰减学习率,其中初始学习率为0.02,最小学习率为0.2*0.01。最后,我们对模型进行300个epoch的训练。
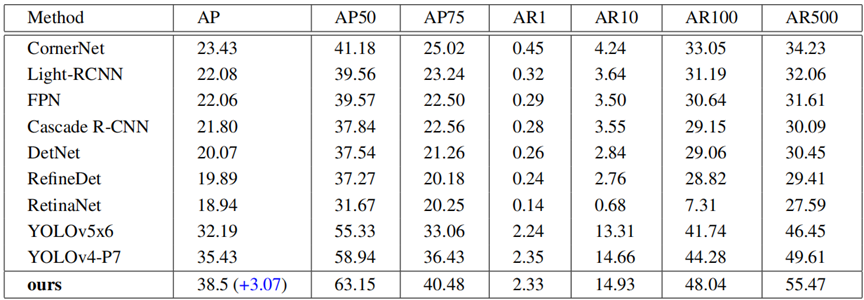
上表展示了我们在VisDrone2019测试开发数据集上的评估结果。在那些最先进的方法中,所有的YOLO系列算法都表现出明显的出色性能。作为优秀模型YOLOv4-P7的改进版本,我们提出的如图2所示的架构在没有使用测试时增强(TTA)和多模型融合的情况下,取得了具有竞争力的性能,平均精度均值(mAP)达到38.5,甚至比基线模型YOLOv4-P7高出3.07。

另一方面,从上图中原始基线模型和我们基于Transformer的模型的预测结果对比来看,我们观察到我们基于Transformer的模型成功识别出了骑摩托车的人,而基线模型则错误地将他们归类为行人。这表明,改进后的主干网络MHSA-Darknet能够通过多头自注意力机制为目标检测提取更具区分性的特征,并且展现出了更强的语义辨别能力,从而减轻了类别混淆问题。
章中所有的数据和资料,可添加小助手无偿分享~
扫码添加小助手即可无偿获取~
也可以关注“AI技术星球”公众号,关注后回复“221C”获取。

















 2235
2235

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









