



如果你正在学习机器学习入门,纯粹学习机器学习理论,容易陷入迷茫,不清楚算法怎么使用,以及怎么实现这个算法
学习机器学习算法的过程中,建议边学习理论,边尝试将理论中的公式建模推导实现出来,就是大家常说的手搓代码,手搓对于提升代码能力真的很有帮助
下面给大家推荐一个手搓机器学习教程(结合之前的机器学习教程一起看更有感觉):
文章中所有的数据和资料,可添加小助手无偿分享~
扫码添加小助手即可无偿获取~
也可以关注“AI技术星球”公众号,关注后回复“221C”获取。

1. KNN算法
首先要基于KNN的原理实现KNN模型,KNN模型挺简单的,总共就三十行左右代码,但是这个模型的思想是挺重要的,算法的具体代码如下,当然还有相应的训练文件
import numpy as np
from collections import Counterdef euclidean_distance(x1, x2):distance = np.sqrt(np.sum((x1-x2)**2))return distanceclass KNN:def __init__(self, k=3):self.k = kdef fit(self, X, y):self.X_train = Xself.y_train = ydef predict(self, X):predictions = [self._predict(x) for x in X]return predictionsdef _predict(self, x):# compute the distancedistances = [euclidean_distance(x, x_train) for x_train in self.X_train]# get the closest kk_indices = np.argsort(distances)[:self.k]k_nearest_labels = [self.y_train[i] for i in k_indices]# majority voyemost_common = Counter(k_nearest_labels).most_common()return most_common[0][0]
2. 线性回归算法
线性回归模型是最简单的机器学习模型,通过拟合自变量和因变量之间的关系,模型也不复杂,适合小白练手,练习的时候不要直接看答案,争取自己先去写一下代码
import numpy as npclass LinearRegression:def __init__(self, lr = 0.001, n_iters=1000):self.lr = lrself.n_iters = n_itersself.weights = Noneself.bias = Nonedef fit(self, X, y):n_samples, n_features = X.shapeself.weights = np.zeros(n_features)self.bias = 0for _ in range(self.n_iters):y_pred = np.dot(X, self.weights) + self.biasdw = (1/n_samples) * np.dot(X.T, (y_pred-y))db = (1/n_samples) * np.sum(y_pred-y)self.weights = self.weights - self.lr * dwself.bias = self.bias - self.lr * dbdef predict(self, X):y_pred = np.dot(X, self.weights) + self.bias return y_pred
3. 逻辑回归算法
逻辑回归是最简单的二分类模型,基于sigmoid函数来计算正负类的概述,注意逻辑回归的损失函数是交叉熵损失,部分代码如下:
import numpy as npdef sigmoid(x):return 1/(1+np.exp(-x))class LogisticRegression():def __init__(self, lr=0.001, n_iters=1000):self.lr = lrself.n_iters = n_itersself.weights = Noneself.bias = Nonedef fit(self, X, y):n_samples, n_features = X.shapeself.weights = np.zeros(n_features)self.bias = 0for _ in range(self.n_iters):linear_pred = np.dot(X, self.weights) + self.biaspredictions = sigmoid(linear_pred)dw = (1/n_samples) * np.dot(X.T, (predictions - y))db = (1/n_samples) * np.sum(predictions-y)self.weights = self.weights - self.lr*dwself.bias = self.bias - self.lr*dbdef predict(self, X):linear_pred = np.dot(X, self.weights) + self.biasy_pred = sigmoid(linear_pred)class_pred = [0 if y<=0.5 else 1 for y in y_pred]return class_pred
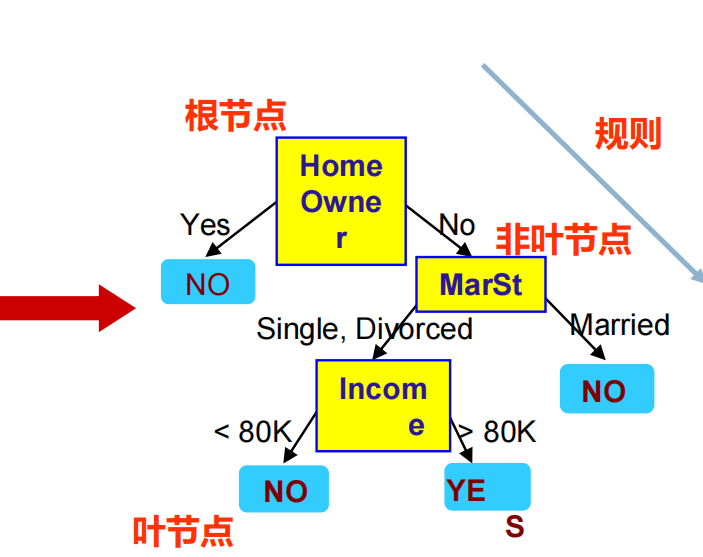
4. 决策树算法
决策树算法是基于二叉树的一种算法,通过在每个节点进行特征划分来实现分类和回归任务,主要有ID3, C4.5和CART分类/回归树几种类型,算法实现过程会比前面的几个更复杂一些,代码比较长就不直接放代码了
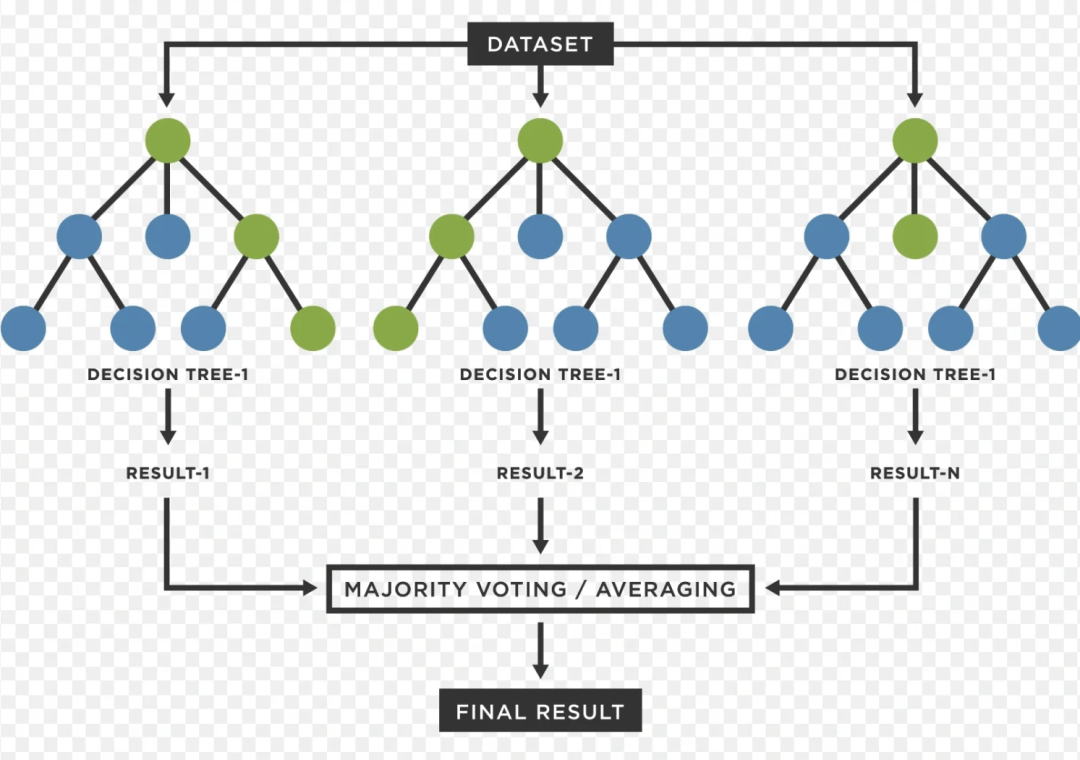
5. 随机森林算法
随机森林算法是基于决策树的一种算法,通过并行训练多棵决策树来提升模型的融合效果,随机森林算法比较容易过拟合,注意设置最大树深度和树的数量等
文章中所有的数据和资料,可添加小助手无偿分享~
扫码添加小助手即可无偿获取~
也可以关注“AI技术星球”公众号,关注后回复“221C”获取。
6. 朴素贝叶斯算法
朴素贝叶斯算法是基于贝叶斯定理的一种算法,可以用于解决垃圾邮件分类等问题,贝叶斯定理真的太伟大了这个思想,朴素指的是特征条件独立,这个在面试中经常会问到

7. PCA算法
主成分分析是用于降维的一种算法,对于数据特征维度比较多,以及存在一些多重共线性问题的时候,可以采用PCA进行降维,防止过拟合。代码总体上不算特别复杂,对于稍微有点python基础的同学,完成可以实现
mport numpy as npclass PCA:def __init__(self, n_components):self.n_components = n_componentsself.components = Noneself.mean = Nonedef fit(self, X):# mean centeringself.mean = np.mean(X, axis=0)X = X - self.mean# covariance, functions needs samples as columnscov = np.cov(X.T)# eigenvectors, eigenvalueseigenvectors, eigenvalues = np.linalg.eig(cov)# eigenvectors v = [:, i] column vector, transpose this for easier calculationseigenvectors = eigenvectors.T# sort eigenvectorsidxs = np.argsort(eigenvalues)[::-1]eigenvalues = eigenvalues[idxs]eigenvectors = eigenvectors[idxs]self.components = eigenvectors[:self.n_components]def transform(self, X):# projects dataX = X - self.meanreturn np.dot(X, self.components.T)
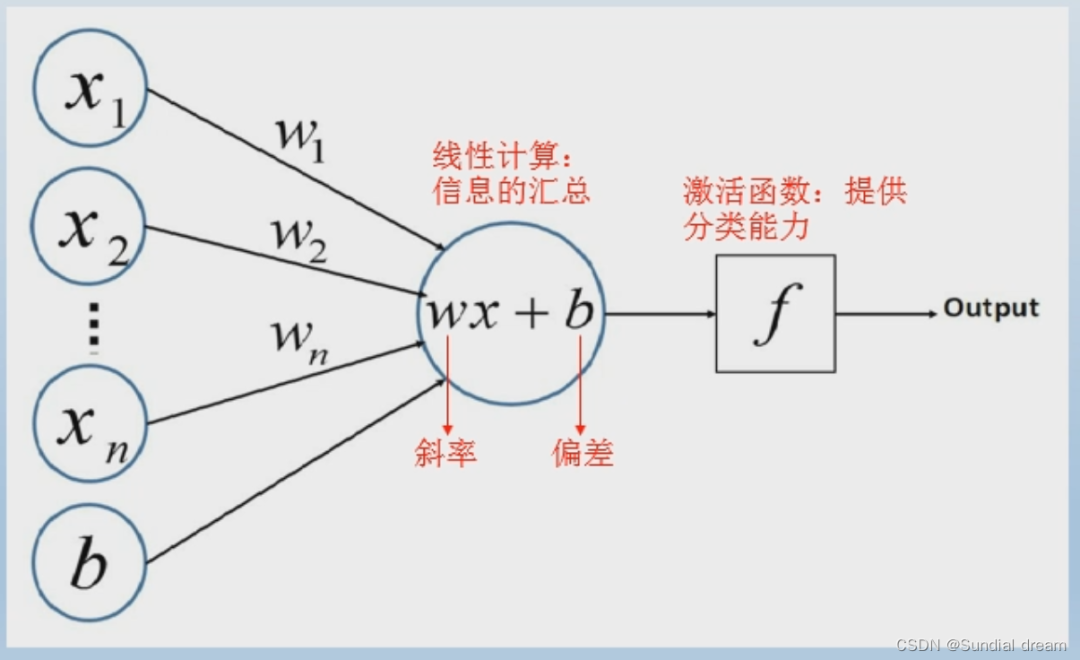
8. 感知机算法
感知机是机器学习历史上第一个真正意义的神经网络的模型,其他深度学习模型都是在这个基础上发展改进的,算法实现简单,易于理解,后续启发了MLP和反向传播等发展,这个可以看一看,手撕感觉意义不大,还不如手撕MLP
9. SVM算法
SVM 的目标不是随便找一个能分开两类的超平面,而是找间隔,间隔越大,分类器越“自信”,对噪声和新样本的鲁棒性越强,泛化能力更好
10. K-means算法
k-means算法是一类聚类算法,属于无监督学习,通过设置K参数,期望最终聚类成K个簇,注意和分类算法进行区分,算法相对来说比其他的复杂,可以看一下代码就行,多看代码一定会有进步的
文章中所有的数据和资料,可添加小助手无偿分享~
扫码添加小助手即可无偿获取~
也可以关注“AI技术星球”公众号,关注后回复“221C”获取。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









