



今天给大家分享机器学习中的几大神仙方法!
第一种、各种重建,先把输入corrupt一下,然后用autoencoder重建一下,基本都能让feature更robust,何恺明的MAE也是如此。
第二种、对比学习大神器,核心就看如何构造正样本和负样本。有个惊艳的idea,同一个输入foward两次,因为dropout不同,就可以当正样本,也是无脑涨点。
说到涨点,这里给大家分享这包含整整22个即插即用模块的手册,对于只想水篇论文毕业的同学来说,简直轻松又实用,包含注意力机制、卷积变体等等,彻底把你从想创新点、改模型改代码的噩梦中解救出去!所有模块的论文PDF和代码都打包好了,可以分享给大家↓↓↓
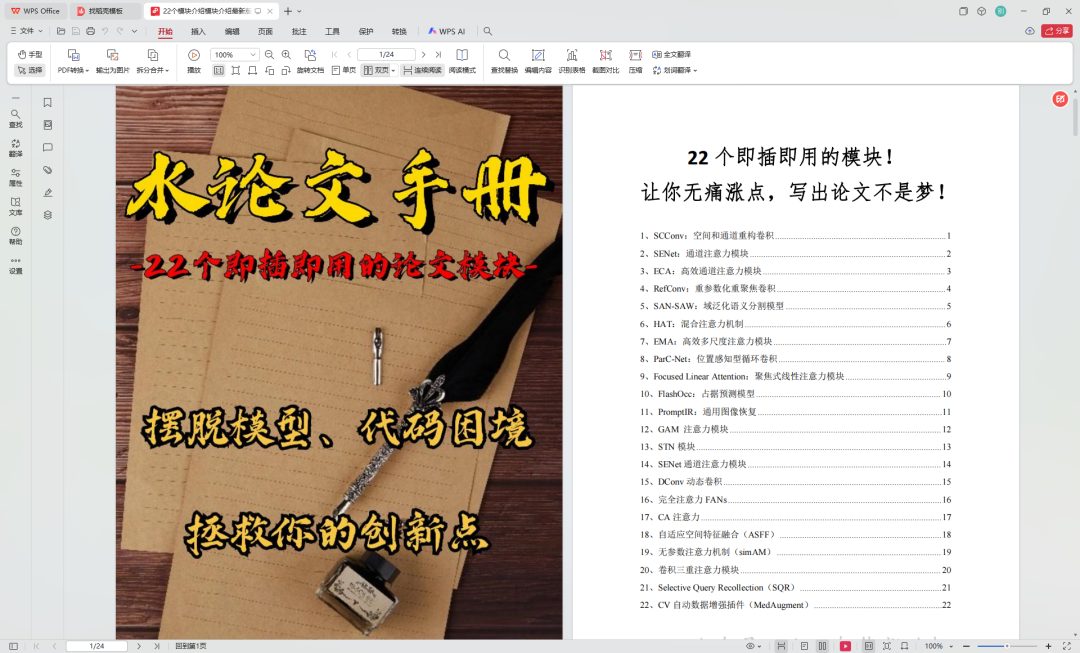
章中所有的数据和资料,可添加小助手无偿分享~
扫码添加小助手即可无偿获取~
也可以关注“AI技术星球”公众号,关注后回复“221C”获取。

第三种、各种dropout,是个地方都可以试着加点dropout,embedding可以加dropout,attention可以加,ffn可以加,mlp可以加,输入上也可以直接加,相当于某种corrupt。
第四种、mixup,也是个神级idea。输入上a类+b类混合一下,然后label也变成a+b混合,基本上也是无脑增强,必定涨点。
这是它的优点:
-
提高泛化能力:通过合成新样本,模型可以学习到更加泛化的特征表示。
-
减少过拟合:平滑的决策边界有助于减少模型对训练数据的过度拟合。
-
增强模型的鲁棒性:Mixup能够使模型对输入数据的微小变化更加不敏感。
-
混合比例λ是一个在0到1之间的标量,它决定了合成样本中每个原始样本的相对贡献。
章中所有的数据和资料,可添加小助手无偿分享~
扫码添加小助手即可无偿获取~
也可以关注“AI技术星球”公众号,关注后回复“221C”获取。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









