






A Comparative Study of DSL Code Generation: Fine-Tuning vs. Optimized Retrieval Augmentation
What is DSL
Domain Specific Languages (or DSLs) are custom Computer Languages designed and optimized for specific applications. Examples of DSLs include SQL and industry-specific languages for formalizing API calls, often using formats like JSON or YAML to represent API sequences.
Therefore, general pre-trained models are hard to directly adopted into this task, which can be greatly affected by hallucination. The syntax, names and APIs in DSL are all custom, partly private and ever-changing. So, fine-tuning is also not an ideal method to handle new APIs, but RAG techniques seem fit well with this topic.
Relative work
Code Generation
Exsiting popular code generation LLM, like Copilot, Code Llama, etc. are all trained on public programming languages including C++, Python, etc. but hard or impossible to include DSL. To utilize them, techniques like fine-tuning or few-shot prompt engineering is needed.
Tool Integration
Some LLMs have learnt to call external tools like web search or calculators. However, these pre-trained models are limited to a small set of well-documented tools and hard to adopt to new, private APIs.
Task Orchestration
It is an unfamiliar task that I’ve never heard of. After searching on the Internet, it is like “automated arranging, coordinating and managing tasks”. Under the context of this paper, I think LLM in orchestration is used to divide the user instruction into several ordered sub-tasks. That’s why the authors put orchestration on par with reasoning.
Summary
In summary, DSL itself can be regarded as a kind of programming language, also a set of external tools, so DSL generation can refer from Code Generation and Tool Integration. Additionally, the process of understanding the instruction and dividing into sub-tasks to decide what APIs to call is like Task Orchestration.
Methodology
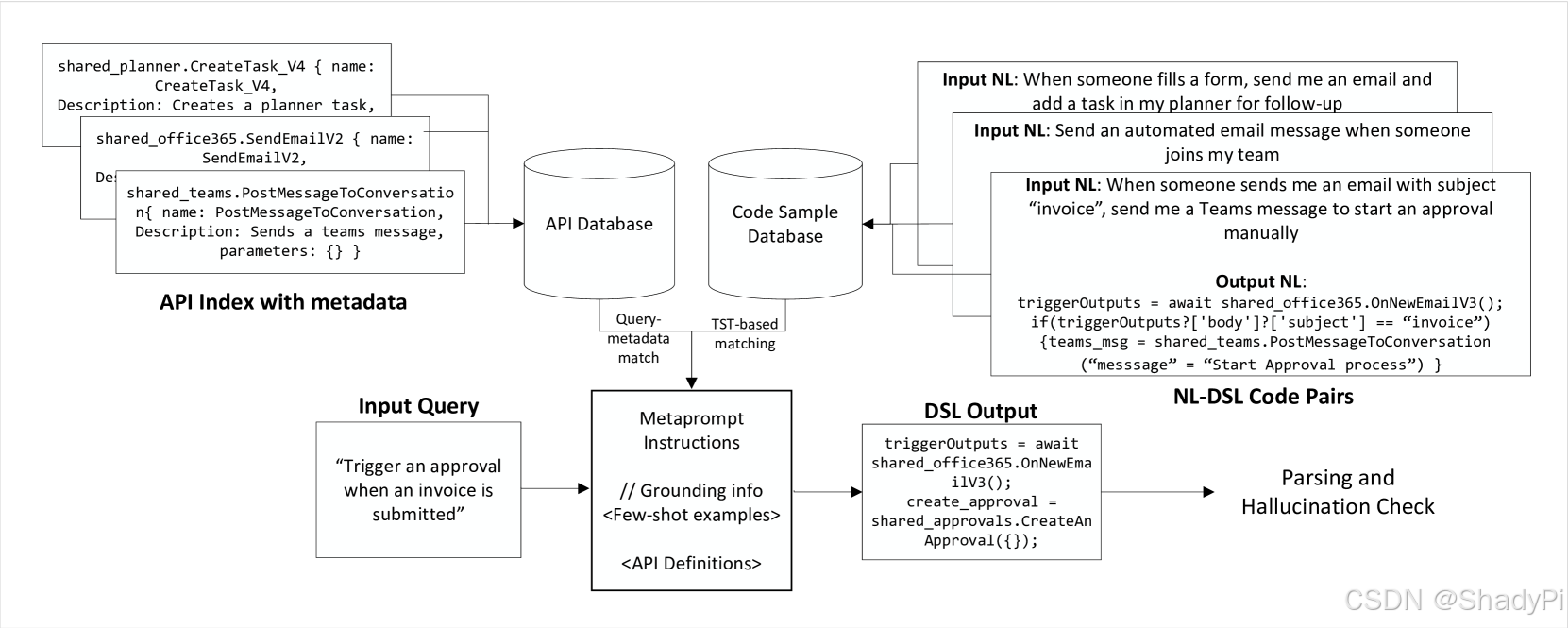
Fine-Tuning Base Model
The backbone in this system is a fine-tuned NL2DSL generation model. It is fine-tuned by LoRA-based approach with 67k NL-DSL pairs from Codex base from OpenAI. To improve the performance, the authors try to do data augmentation and add synthesized data into training set. They found it is challenging to predict the parameter keys due to limitation of data generation, because the synthetized samples do not contain various different parameters.
TST-based Example Retrieval
The authors fine-tuned a pre-trained BERT model with a modified loss function to produce embeddings for retrieval. TST (Target Similarity Tuning) is a kind of loss computation methods, aiming at minimizing the difference between Cosine Similarity of Natural Language Embeddings and another Pre-Defined Metric of Program Similarity.
LTST(θ)=E(i,j)∼D[fθ(ui,uj)−S(pi,pj)]2
L_{TST}(\theta) = \mathbb{E}_{(i,j)\sim\mathcal{D}}\left[f_\theta(u_i, u_j)-S(p_i, p_j)\right]^2
LTST(θ)=E(i,j)∼D[fθ(ui,uj)−S(pi,pj)]2
Here, SSS is Jaccard score of lists of API function names.
The authors mentioned that they collect positive and negative pairs based on similarity of embedding produced by a Pre-Trained Transformer model, but they did not mention how they are used in the fine-tuning.
Prompt Grounding
“Grounding” is a concept proposed by Microsoft (I think). Basically, it means providing additional ground truth information in the prompt. In this system, they provide metadata of API in the prompt, including the description of function and all parameter keys. There are 2 methods proposed.
- Providing metadata of all APIs appeared in retrieved few-shot examples (Regular FD).
- Based on the NL query, retrieve APIs with similar API description in metadata. They named it Semantic Function Definition (SFD). It is useful for prompts where no few-shot examples are retrieved.
Experiments
The backbone agent model used in experiments is GPT-4 (16k token limit).
Dataset Generation
The train and test set consists of a total of 67k and 1k samples, respectively. These samples are (prompt, flow) pairs with the workflows being created by users across a large set of APIs. After removing Personally Identifiable Information, PII data, there are 700 publicly available APIS left. They generate corresponding NL prompts using GPT-4.
Metrics
- Average Similarity
The authors reduce the flow to a sequence of APIs, despite the parameters (actually I don’t think it is reasonable), and then compute the Longest Common Subsequence match between ground truth sequence and predicted sequence. The similarity is LCSS(A,B)/max(∣A∣,∣B∣)LCSS(A,B)/\max(|A|, |B|)LCSS(A,B)/max(∣A∣,∣B∣), where A,BA, BA,B is the reduced API sequence. Hallucination and Parser failures lead to the sample being discarded and is assigned a similarity score of 0. - Unparsed rate
The rate of syntactic errors, ∣Flowunparsed∣/∣Flowtotal∣|\text{Flow}_\text{unparsed}|/|\text{Flow}_\text{total}|∣Flowunparsed∣/∣Flowtotal∣. - Hallucination rate
Hallucinated API name rate: ∣Flowh∣/∣Flowparsed∣|\text{Flow}_\text{h}|/|\text{Flow}_\text{parsed}|∣Flowh∣/∣Flowparsed∣.
Hallucinated API parameter key name rate: ∣Flowh∣/∣Flowparsed∣|\text{Flow}_\text{h}|/|\text{Flow}_\text{parsed}|∣Flowh∣/∣Flowparsed∣.
Results
The test set contains 1000 NL-DSL pairs, where 864 are in-domain samples and 136 are out-of-domain samples. The authors investigate the impact of each ablation with in-domain samples and evaluate the generalizability with out-of-domain samples.
An unusual thing of the results is that they only display the difference with baseline but keep the actual value of baseline secret. Is this confidential requirement or just because the results do not meet the expectation?
Number of few-shot examples
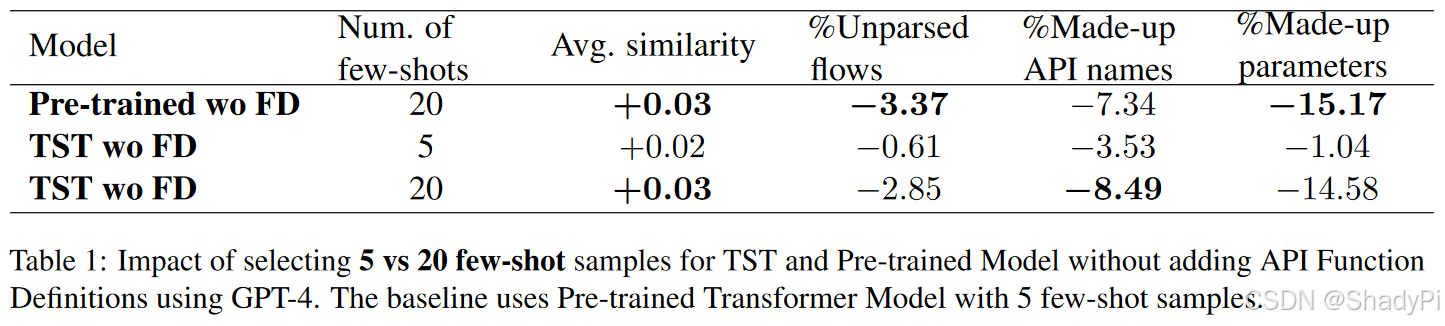
More few-shots improves the performance by reducing the number of made-up API names as well as reducing the number of made-up API parameter keys.
TST vs Pre-trained Model
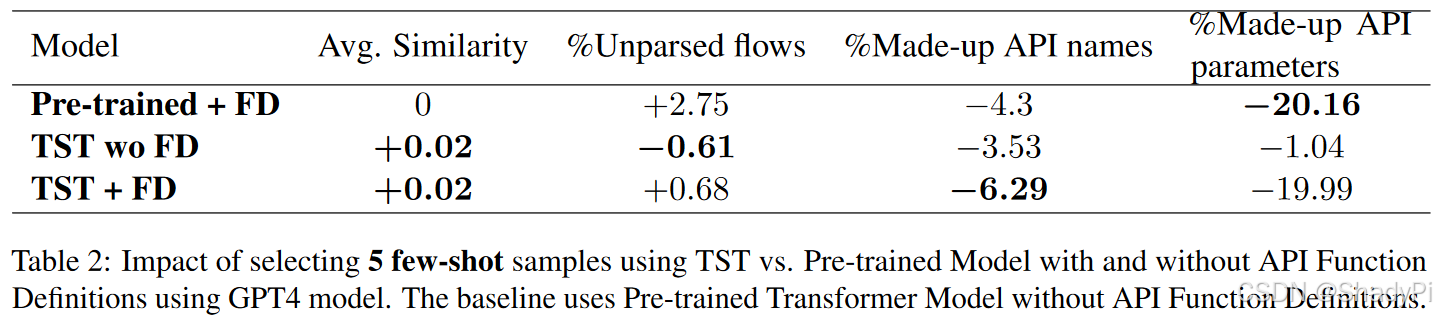
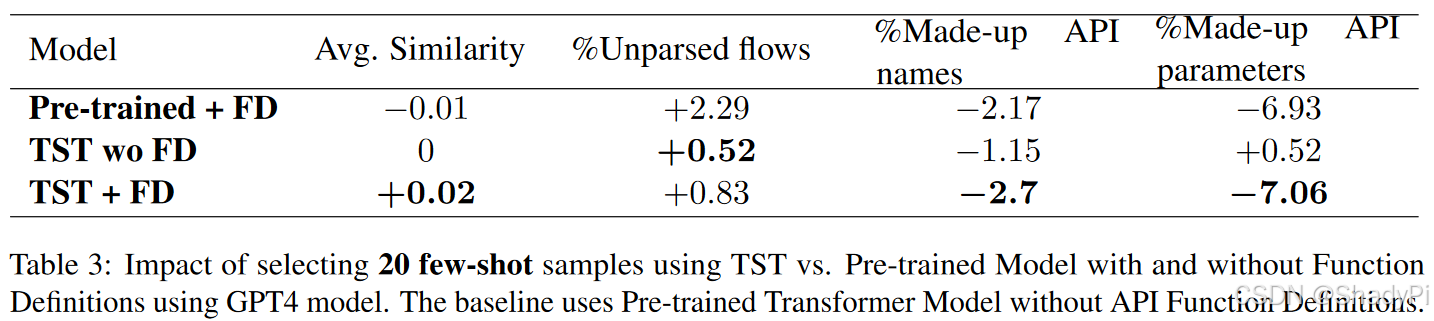
The addition predominantly helps reducing the hallucination rate for API names and parameters, which indicates that adding tool descriptions (like it is done in planning tasks) along with few-shot code samples helps improve reliability of plan generation.
Regular Function Definition vs Semantic Function Definitions

Simply add semantically similar API metadata for a query is not useful for DSL generation.
Out of Domain APIs

When samples are not present in the train set, grounding with RAG context can provide the LLM support for improving code quality. The role of few-shots in informing the syntax of the output code cannot be substituted with just adding function definitions. Since, it is hard to obtain the examples for unseen APIs, alternate ways to improve syntactic errors need to be found.
My thoughts
The metrics of average similarity lacks practical significance, because it does not consider the correctness of parameters. Even a 100% similarity cannot guarantee the generated flow is correct. To be more practical, I think it is necessary to evaluate whether the generated flow works, just like other code generation tasks.
When discussing with an expert in industry, he said his team would consider the NL2DSL task as Named Entity Recognition, NER task, where they will try to recognize the API names, parameter names and key values from prompt. It can greatly decrease the probability of hallucinations but requires user to provide more information in prompt. In fact, we can guide users to clarify their intent, asking users to select and re-rank retrieved key words, instead of generating flow end to end.


















 1153
1153

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











