




 InstructZero是一种针对黑盒大型语言模型的指令优化方法,通过softprompt先优化开源LLM生成优质指令,再与输入一起给黑盒模型,提升其性能。文章介绍了维度消减和贝叶斯优化技术,其中贝叶斯优化通过高斯分布估计和协方差函数寻找最佳prompt。实验表明,该方法在某些任务上优于其他策略。
InstructZero是一种针对黑盒大型语言模型的指令优化方法,通过softprompt先优化开源LLM生成优质指令,再与输入一起给黑盒模型,提升其性能。文章介绍了维度消减和贝叶斯优化技术,其中贝叶斯优化通过高斯分布估计和协方差函数寻找最佳prompt。实验表明,该方法在某些任务上优于其他策略。
INSTRUCTZERO: EFFICIENT INSTRUCTION OPTIMIZATION FOR BLACK-BOX LARGE LANGUAGE MODELS
Chen L, Chen J, Goldstein T, et al. InstructZero: Efficient Instruction Optimization for Black-Box Large Language Models[J]. arXiv preprint arXiv:2306.03082, 2023.
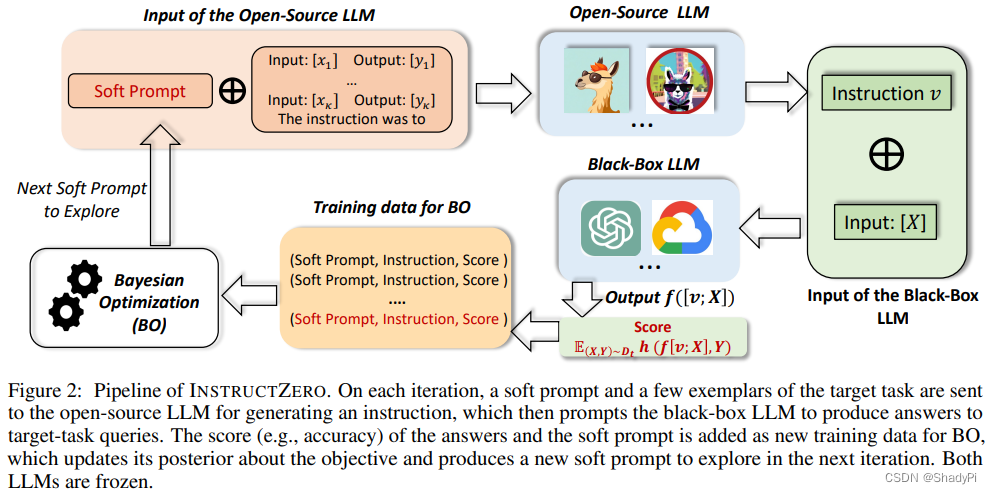
核心思想:用soft prompt先优化一个开源的LLM,使其生成一个优质的instruction,将这个instruction和input一起输入给黑盒LLM,目的是优化黑盒LLM的表现。
开源LLM的输入是soft prompt和一些样例的embedding,输出则是一个instruction。将instruction和input合在一起给黑盒LLM,得到最终的输出。优化则使用非梯度的方法,贝叶斯优化。本工作主要有两个技术,维度消减和贝叶斯优化。
先说比较简单的维度消减,这个技术也算是比较常规了。因为soft prompt的维度很高,比如Vicuna的soft prompt有上千维,这么高的维度现有的优化方法是hold不了的,这时候就需要一个投影矩阵 A ∈ R d ′ × d , d ′ ≪ d A\in R^{d'\times d}, d'\ll d A∈Rd′×d,d′≪d,而优化的向量 p ′ ∈ R d ′ p'\in R^{d'} p′∈Rd′,输入给LLM的soft prompt则表示为 p = A p ′ p = Ap' p=Ap′。文中列举了一些工作证明该技术的合理性,这里就不多赘述了。
第二个就是贝叶斯优化了,将整个pipeline的性能
H
(
⋅
)
H(·)
H(⋅)看作一个高斯分布,用之前尝试过的样本
(
p
,
H
(
p
)
)
(p,H(p))
(p,H(p))来估计这个高斯分布的均值和方差,其中
k
⃗
\vec{k}
k是由协方差函数
k
(
⋅
,
⋅
)
k(·,·)
k(⋅,⋅)的值构成的向量。
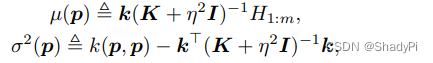
而
u
(
p
)
u(p)
u(p)则被定义为新的prompt相较之前的prompt的期望提升,贝叶斯优化的目的就是最大化
u
(
p
)
u(p)
u(p),得到新的prompt
p
m
+
1
p_{m+1}
pm+1,将
p
m
+
1
p_{m+1}
pm+1送入pipeline中又得到新的打分
H
(
p
m
+
1
)
H(p_{m+1})
H(pm+1)就完成了一次优化迭代。
设计协方差函数
k
(
⋅
,
⋅
)
k(\cdot,\cdot)
k(⋅,⋅)是一件比较考验数学功力的事情,其中的一些逻辑我还没完全理顺。作者认为贝叶斯优化的目标是在instruction域上面优化instruction,因此kernel需要反映生成的instructions在目标任务上的相似度。作者从两个维度构建了该函数,一个是soft prompt本身的相似度,用函数
l
(
⋅
,
⋅
)
l(\cdot,\cdot)
l(⋅,⋅)衡量,可以用Matern或者平方指数核。还有一个维度是prompt输入黑盒LLM产生的输出的相似度,用函数
s
(
⋅
,
⋅
)
s(\cdot,\cdot)
s(⋅,⋅)衡量。
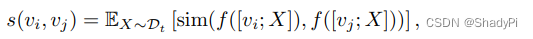
其中sim为F1或者BLUE指数。最后得到的协方差函数如下
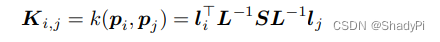
整个算法流程如下

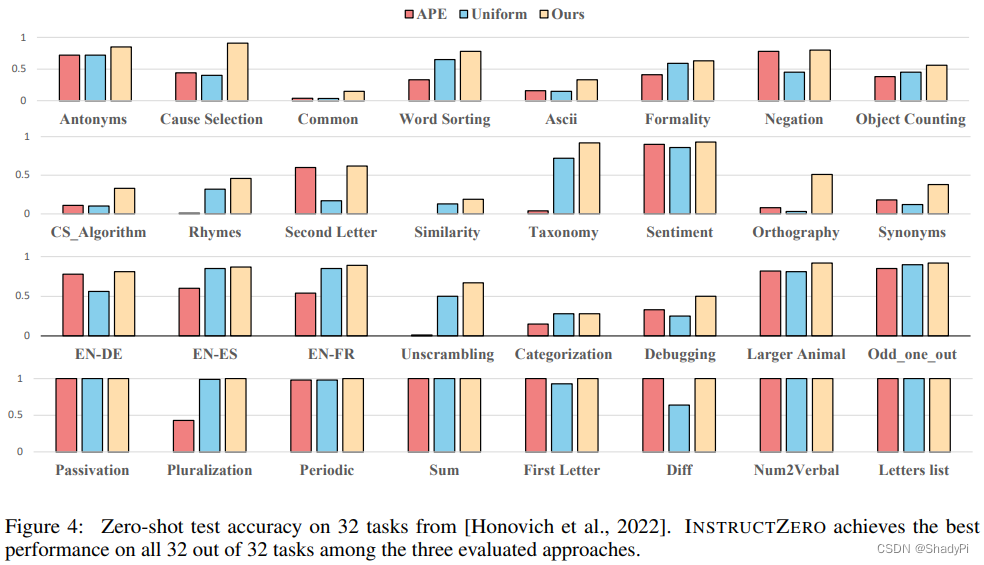
实验对比了APE、Uniform(PromptZero但是没有贝叶斯优化迭代,只是均匀取样)和PromptZero。结果显示在APE已经做得很好的任务上两者相当,而APE做不好的任务PromptZero表现更出色。
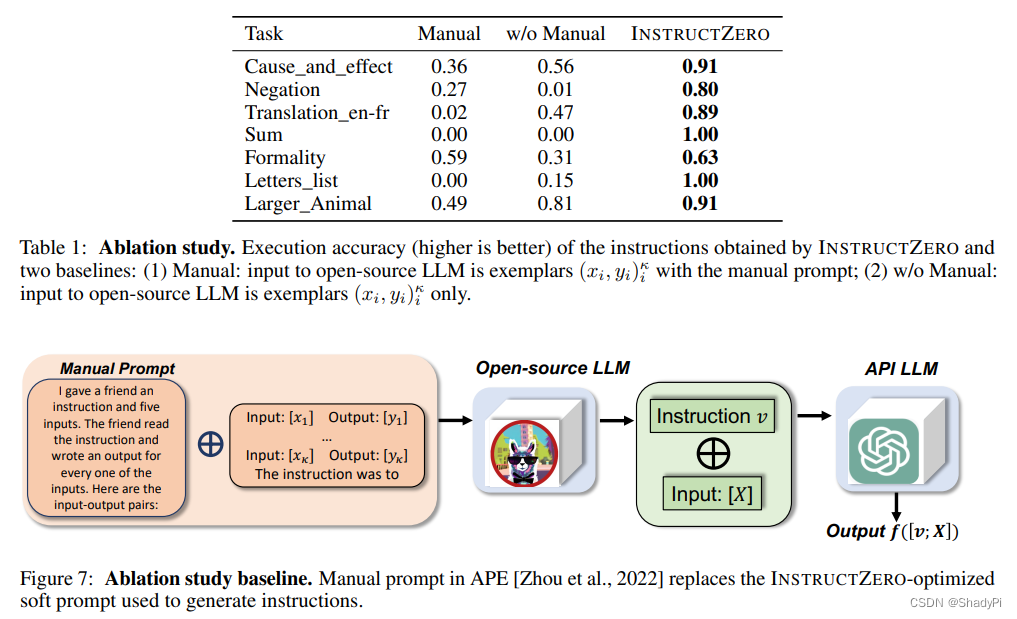
消融实验,用人类写的prompt而不是soft prompt直接给开源LLM让其生成prompt,然后再给API prompt,效果自然是烂。本来就是soft prompt又迭代优化了,感觉属实欺负人工队了。
这篇工作还是有很多可取之处,尤其是BO的设计值得学习。不过用soft prompt调教一个开源LLM然后优化API LLM的表现感觉有点兜圈子啊。说不定效果没有soft prompt直接调教T5,如HyperPrompt的效果好。另外最开始看到作者用开源模型+soft prompt我以为又是hyperprompt的套路,要参与模型的向前甚至向后传播,但实际上也只需要输入输出,不管中间过程,只是调用API的话可能确实需要很多次调用,但应该也是可行的。


















 2400
2400

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











