




指数加权平均
对于一个呈序列形式的数据集,一种统计并获得连续曲线的方法是指数加权平均。具体来讲,对于一个数据序列
θ1,θ2,⋯ ,θm
\theta_1,\theta_2,\cdots,\theta_m
θ1,θ2,⋯,θm
如果直接把这些点相连,得到的曲线会包含大量噪声,杂乱而无规律:
所以我们重新计算一下每个点的值,令
v0=0v1=βv0+(1−β)θ1⋯vi=βvi−1+(1−β)θi⋯vm=βvm−1+(1−β)θm
v_0=0\\
v_1=\beta v_0+(1-\beta)\theta_1\\
\cdots\\
v_i=\beta v_{i-1}+(1-\beta)\theta_i\\
\cdots\\
v_m=\beta v_{m-1}+(1-\beta)\theta_m\\
v0=0v1=βv0+(1−β)θ1⋯vi=βvi−1+(1−β)θi⋯vm=βvm−1+(1−β)θm
通过该平均方法,我们实际上是对1∼i1\sim i1∼i的数据进行了加权平均,且权重从iii到111呈指数递减,越靠近当前索引所占的权重越高。一个经验的估计是viv_ivi大概代表着前11−β\frac{1}{1-\beta}1−β1个数据求平均,因为超过该范围的样本所占的权重已经比较小了。
参数β\betaβ影响的就是之前的样本所占权重的衰减速率,β\betaβ越接近1,样本权重衰减就越慢,我们囊括的样本就越多,此时曲线会比较平滑,但不能及时反映出当前点产生的效应,通常会比较滞后。而KaTeX parse error: Undefined control sequence: \bata at position 1: \̲b̲a̲t̲a̲越接近0,样本权重衰减就越快,曲线就会波动更剧烈,但是对当前数据非常敏感,反应很及时。
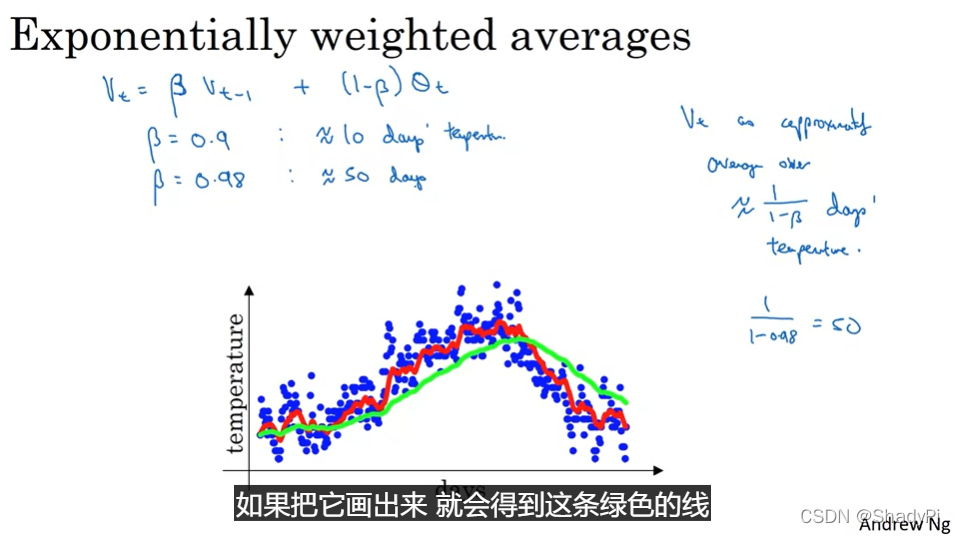
下图为β=0.9\beta=0.9β=0.9(红色)和β=0.98\beta=0.98β=0.98(绿色)时我们得到的曲线:
偏差消除
在实际应用中,我们得到的曲线其实和上图的曲线还有一点偏差,如果β=0.98\beta=0.98β=0.98,我们实际得出的应该是紫色线:
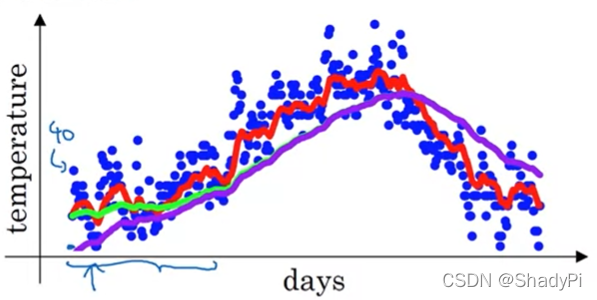
这是因为在指数加权平均的前期,我们的初始值v0=0v_0=0v0=0还占据了很大的权重,使得曲线的前端都被拉低了,直到曲线的中后程,v0v_0v0的权重衰减的足够低,紫色线才逐渐与绿色线重合。
想要避免这种情况,可以在之前的运算中再加上一项,得到
vi=βvi−1+(1−β)θi1−βi
v_i=\frac{\beta v_{i-1}+(1-\beta)\theta_i}{1-\beta^i}
vi=1−βiβvi−1+(1−β)θi
因为初始项v0=0v_0=0v0=0在viv_ivi中所占的权重就是βi\beta^iβi,所以除以1−βi1-\beta^i1−βi就可以排除掉v0v_0v0带来的影响,得到一个合理的曲线。


















 889
889

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











