



一. Sigmoid函数介绍
1. 函数表达式
Sigmoid函数是一种常用的激活函数,也称为Logistic函数,它将任意实数映射到一个范围在0到1之间的值。Sigmoid函数的数学表达式为:
2. 函数图像
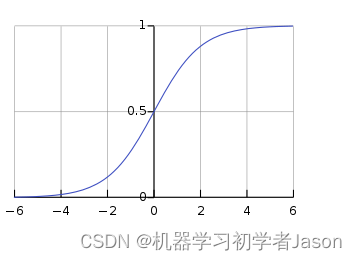
二. Sigmoid函数使用
Sigmoid函数曾经在神经网络的早期阶段得到广泛应用,主要用于二分类问题和输出层的激活函数。虽然现在它的使用已经被更先进的激活函数所取代,但Sigmoid函数仍然在某些特定的应用场景中具有一定的用途,例如:
-
二分类问题:Sigmoid函数最典型的应用场景是二分类问题,其中模型需要将输入数据分为两个类别。在神经网络中,Sigmoid函数可以作为输出层的激活函数,将网络的输出映射到(0, 1)的概率范围内,表示样本属于某个类别的概率。
-
逻辑回归:逻辑回归是一种常用的统计学习方法,用于建立分类模型。在逻辑回归中,Sigmoid函数被用作逻辑函数(Logistic function),用于将线性模型的输出转换为概率值。
-
异常检测:在一些异常检测问题中,需要将数据映射到一个介于0和1之间的范围内,以评估数据点是否属于正常状态。Sigmoid函数可以用于此类场景,将模型的输出映射到概率分布。
-
概率建模:在某些情况下,需要建立概率模型来描述事件的发生概率。Sigmoid函数可以用作概率模型中的激活函数,以确保输出在概率范围内。
Sigmoid函数的主要特点包括:
-
输出范围在0到1之间:Sigmoid函数的输出范围在0到1之间,这使得它特别适合用于二分类问题,因为它可以将输出解释为样本属于某个类别的概率。
-
平滑性:Sigmoid函数是光滑且连续的,在整个定义域上都具有可导性,这对于基于梯度的优化方法(如梯度下降)非常重要。
-
非线性特性:Sigmoid函数是一种非线性函数,它引入了非线性变换,使得神经网络能够学习和表示复杂的非线性函数关系。
尽管Sigmoid函数在早期的神经网络中被广泛使用,但它也存在一些缺点,如:
- 梯度饱和:当输入很大或很小时,Sigmoid函数的梯度会接近于零,这可能会导致梯度消失问题,使得训练过程变得缓慢或停滞。
- 输出不是零中心:Sigmoid函数的输出范围是(0, 1),并不是零中心,这可能会导致一些训练问题。
- 指数运算开销大:Sigmoid函数的计算需要进行指数运算,计算量较大,特别是在大规模数据集和深层网络中。
由于这些缺点,近年来在神经网络中,ReLU(修正线性单元)等激活函数逐渐取代了Sigmoid函数的应用。

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









